 etcd版本差异
etcd版本差异
# ETCD 3.0版本差异
# 版本说明
目前etcd主要经历了3个大的版本,分别为etcd 0.4版本、etcd 2.0版本和etcd 3.0版本。对于etcd 2.0版本,已经可以很好满足etcd的初步需求,主要包括:
专注于key-value存储,而不是一个完整的数据库;
通过HTTP + JSON的方式暴露给外部API;
watch机制提供持续监听某个key变化的功能,以及基于TTL的key的自动过期机制。
但是在实际过程中,我们也发现了一些问题,比如客户端需要频繁地与服务端进行通信,集群在空间和时间上都需要承受较大的压力,以及垃圾回收key的时间不稳定等,同时“微服务”架构要求etcd能够单集群支撑更大规模的并发,因此诞生了etcd 3.0版本,主要对HTTP + JSON的通信方式、key的自动过期机制、watch机制、数据持久化等进行了优化,下面我们看看etcd 3.0版本对每个模块都做了哪些优化。
# 客户端通信方式
gRPC是Google开源的 个高性能、跨语言的RPC框架,基于HTTP/2协议实现。它使用protobuf作为序列化和反序列化协议,即基于 protobuf 来声明数据模型和RPC接口服务。protobuf的效率远高于JSON,尽管etcd v2的客户端已经对JSON的序列号和反序列化进行了大量的优化,但是etcd v3的gRPC序列号和反序列化的速度依旧是etcd v2的两倍多。
etcdv3的客户端使用gRPC与server进行通信,通信的消息协议使用protobuf进行约定,代替了v2版本的HTTP+JSON格式,使用二进制替代文本,更加节省空间。同时gRPC使用的是HTTP/2协议,同一个连接可以同时处理多个请求,不必像HTTP1.1协议中,多个请求需要建立多个连接。同时,HTTP/2会对请求的Header和请求数据进行压缩编码,常见的有Header帧,用于传输Header内容,另外就是Data帧,来传输正文实体。客户端可以将多个请求放到不同的流中,然后将这些流拆分成帧的形式进行二进制传输,传输的帧也会有一个编号,因此在一个连接中客户端可以发送多个请求,减少了连接数,降低了对服务器的压力,二进制的数据传输格式也会是传输速度更快。
总结一下,其实这里主要进行2点优化:
- 二进制取代字符串:通过gRPC进行通信,代替了v2版本的HTTP+JSON格式;
- 减少TCP连接:使用HTTP/2协议,同一个连接可以同时处理多个请求,摒弃多个请求需要建立多个连接的方式。
# 键的过期机制
etcdv2中的键的实效是使用TTL机制来实现的,每个有存活时间的键,客户端必须定期的进行刷新重新设置保证它不被自动删除,每次刷新同时还会重新建立连接去更新键。也就是说,及时整个集群都处于空闲状态,也会有很多客户端与服务器进行定期通信,以保证某个key不被自动删除。
etcdv3版本中采用了租约机制进行实现,每个租约会有一个TTL,然后将一些key附加到租约上,当租约到期后,附加到它上边的key都会被删除。利用键的过期机制可以实现服务注册功能,我们可以将一个服务的域名、IP等信息注册到etcd中,并给相应的键设置租约,并在TTL时间内定期维持一个心跳进行刷新。当服务故障后,心跳消失从而相应的键就会自动删除,从而实现了服务的注册功能和服务的健康检查功能。
总结一下,就是v2版本比较傻瓜,需要时刻维护每个key的通信,v3就比较智能,整个统一的过期key的代号,我们把代号称之为“租约”,我们只需要维护这个代号即可,避免客户端去维护所有的key。
# watch机制
etcdv2中的键被废除以后,为了能够跟踪key的变化,使用了事件机制进行跟踪,维护键的状态,来防止被删除掉的后键还能恢复和watch到,但是有一个滑动窗口的大小限制,那么如果要获取1000个时间之前的键就获取不到了。因此etcdv2中通过watch来同步数据不是那么可靠,断开连接一段时间后就会导致有可能中间的键的改动获取不到了。在etcdv3中支持get和watch键的任意的历史版本记录。
另外,v2中的watch本质上还是建立很多HTTP连接,每一个watch建立一个tcp套接字连接,当watch的客户端过多的时候会大大消耗服务器的资源,如果有数千个客户端watch数千个key,那么etcd v2的服务端的socket和内存资源会很快被耗尽。v3版本中的watch可以进行连接复用,多个客户端可以共用相同的TCP连接,大大减轻了服务器的压力。
总结一下,其实这里主要进行2点优化:
- 实时监听key的更新:解决v2中途key的数据更新,客服端不会感知的问题;
- 多路复用:这个可以想到select和epool模型,就是一个客户之前需要建立多个TCP连接,现在只需要建立一个即可。
# 数据存储模型
etcd是一个key-value数据库,ectd v2只保存了key的最新的value,之前的value会被直接覆盖,如果需要知道一个key的历史记录,需要对该key维护一个历史变更的窗口,默认保存最新的1000个变更,但是当数据更新较快时,这1000个变更其实“不够用”,因为数据会被快速覆盖,之前的记录还是找不到。为了解决这个问题,etcd v3摒弃了v2不稳定的“滑动窗口”式设计,引入MVCC机制,采用从历史记录为主索引的存储结构,保存了key的所有历史记录变更,并支持数据在无锁状态下的的快速查询。 etcd是一个key-value数据库,etcdv2的key是一个递归的文件目录结构,在v3版本中的键改成了扁平化的数据结构,更加简洁,并通过线段树的优化方式,支持key的快速查询。
由于etcd v3实现了MVCC,保存了每个key-value pair的历史版本,数据了大了很多,不能将整个数据库都存放到内存中。因此etcd v3摒弃了内存数据库,转为磁盘数据库,即整个数据都存储在磁盘上,底层的存储引擎使用的是BoltDB。
总结一下,其实这里主要进行3点优化:
- 保存历史数据:摈弃v2的“滑动窗口”式设计,通过MVCC机制,保存了所有的历史数据;
- 数据落磁盘:因为要保存历史数据,数据量态度,不适合全内存存储,使用BoltDB存储;
- 查询优化:摒弃v2的目录式层级化设计,使用线段树优化查询。
# 多版本并发控制
# 为什么选择MVCC
高并发情况下,会存在大量读写操。对于etcd v2,它是一个纯内存的数据库,整个数据库有一个Stop-the-World的大锁,可以通过锁的机制来解决并发带来的数据竞争,但是通过锁的方式存在一些确定,具体如下:
锁的粒度不好控制,每次操作Stop-the-World时都会锁住整个数据库。
读锁和写锁会相互阻塞。
如果使用基于锁的隔离机制,并且有一段很长的读事务,那么在这段时间内这个对象就会无法被改写,后面的事务也会被阻塞,直到这个事务完成为止,这种机制对于并发性能来说影响很大。
MVCC其实就是多版本并发控制,etcd在v3才引入,它可以很好的解决锁带来的问题,每当需要更改或者删除某个数据对象时,DBMS不会在原地删除或者修改这个已有的数据对象本身,而是针对该数据对象创建一个新的版本,这样一来,并发的读取操作可以在无需加锁的情况下读取老版本的数据,而写操作就可以同时进行,这个模式的好处可以让读取操作不再阻塞。
总而言之,MVCC能最大的实现高效的读写并发,尤其是高效的读,因此非常适合etcd这种“读多写少”的场景。
# 数据模型
将讲解MVCC的实现原理前,还需要了解v2和v3的数据存储模型。
对于v2,前面其实已经讲过,v2是一个存内存的数据库,数据会通过WAL日志和Snapshot来持久化数据,具体持久化数据的方式,后面会整体讲述。
对于v3,因为它支持历史版本数据的查询,所以它是将数据存储在一个多版本的持久化K-V存储里面,当持久化键值数据发生变化时,会先保存之前的旧值,所以数据修改后,key先前版本的所有值仍然可以访问和watch。由于v3需要保存数据的历史版本,这就极大地增加了存储量,内存存储不了那么多的数据,所以v3的数据需要持久化到磁盘中,存储数据为BoltDB。
那什么是BoltDB呢?BoltDB是一个纯粹的Go语言版的K-V存储,它的目标是为项目提供一个简单、高效、可靠的嵌入式的、可序列化的键值数据库,而不要像MySQL那样完整的数据库服务器。BoltDB还是一个支持事务的键值存储,etcd事务就是基于BoltDB的事务实现的。为了大家能充分理解,我再扩展2个问题:
- v2会定时快照,v3需要进行快照么?
答案是不会。v3实现MVCC之后,数据是实时写入BoltDB数据库中,也就是数据的持久化已经“摊销”到了每次对key的写请求上,因此v3就不需要再做快照了。
- v3中所有的历史数据都会保存下来么?
答案是不会。虽然v3没有快照,数据全部落在BoltDB,但是为了防止数据存储随着时间推移而无限增长,etcd可能会压缩(其实就是删除)key的旧版本数据,说的通俗一点,就是删除BoltDB中旧版本的数据。
# 初探MVCC实现
那么v3是怎么实现MVCC的呢?我们可以先看如下操作:
etcdctl txn <<< 'put key1 "v1" put key2 "v2"'
etcdctl txn <<< 'put key1 "v12" put key2 "v22"'
2
BoltDB中会存入4条数据,具体代码如下所示:
rev={3 0}, key=key1, value="v1"
rev={3 1}, key=key2, value="v2"
rev={4 0}, key=key1, value="v12"
rev={4 0}, key=key2, value="v22"
2
3
4
reversion主要由2部分组成,第一部分是main rev,每操作一次事务就加1,第二部分是sub rev,同 一个事务中每进行一次操作就加1。如上示例所示,第一次操作的main rev是3,第二次是4 。
了解v3的磁盘存储之后,可以看到要想从BoltDB中查询数据,必须通过reversion,但是客户端都是通过key来查询value,所以etcd在内存中还维护了一个kvindex ,保存的就是key reversion之前的映射关系,用来加速查询。kvindex是基于Google开源的GoLang的B树实现,也就v3在内存中维护的二级索引,这样当客户端通key查询value的时候, 会先在kvindex中查询这个key的所有revision ,然后再通过 revision从BoltDB中查询数据。
# 日志和快照管理
# 数据持久化
etcd对数据的持久化,采用的是WAL日志加Snapshot快照的方式。
其实在“3.3.1 复制状态机”就已经讲述了WAL日志的作用,这里再简单重温一下。etcd对数据的更新都是先写到WAL中,当通过Raft将WAL同步到所有分布式节点之后,再将WAL中的数据写到内存。对于WAL日志,其实还有个作用,就是实现redo和undo功能,也就是当数据出现问题时,以为WAL日志记录了对数据的所有操作,所以可以通过WAL对数据库进行恢复和回滚。
既然有了WAL日志,那为什么还需要定期做快照呢?这里其实和Redis中的RDB和AOF日志很像,我们可以把WAL日志对标为Redis的AOF日志,Snapshot快照对标为Redis的RDB日志。在Redis中进行节点间数据同步时,我们是先全量同步RDB日志(快照文件),然后再增量同步AOF日志(数据增量文件)。etcd也不一样,因为WAL日志太琐碎了,如果需要通过WAL日志去同步数据,太慢了,我们先把之前所有的数据同步过去(Snapshot快照文件),然后再同步后续的增量数据(WAL日志)。当对WAL数据昨晚快照后,就可以将旧的WAL数据删除。
# 快照管理
至于快照文件是怎么生成的,如果了解Redis中的RDB文件的生成原理,这个就不难理解了,为了偷个懒,我直接把之前Redis的快照原理图贴过来:
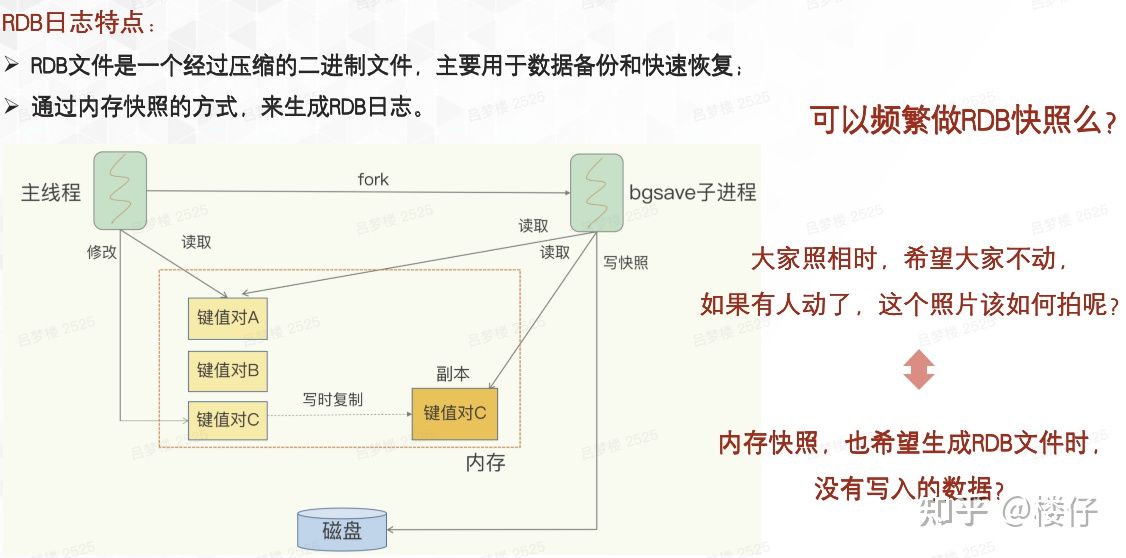
其实就是通过写时复制技术Copy-On-Write完成的,当需要进行快照时,如果数据有更新,会生成一个数据副本,如图中的“键值对C”,当进行快照时,数据如果未更新,直接落盘,数据如果有更新,同步副本数据即可。