 【protobuf】protobuf 编码原理
【protobuf】protobuf 编码原理
# protobuf 定义
syntax = "proto3";
// 我是注释
message Person {
string name = 1;
int32 id = 2;
}
2
3
4
5
6
7
字段编号:消息类型中的每个字段都需要定义唯一的编号,该编号会用来识别二进制数据中字段。编号在[1,15]范围内可以用一个字节编码表示。在[16,2047]范围可以用两个字节编码表示。所以将15以内的编号留给频繁出现的字段可以节省空间。编号的最小值为1,最大值为2^29-1=536870911. 不能使用[19000,19999]范围内的数字,因为该范围内的数字被proto编译器内部使用。同理,其他预先已经被保留的数字也不能使用。
字段规则:每个字段可以被singular或者repeated修饰。在proto3语法中,如果不指定修饰类型,默认值为singular. singular: 表示被修饰的字段最多出现1次,即出现0次或1次。repeated: 表示被修饰的字段可以出现任意次,包括0次。在proto3语法中,repeated修饰的字段默认采用packed编码
保留字段:当删掉或者注释掉message中的一个字段时,将来其他开发人员在更新message定义时可以重用之前的字段编号。如果他们意外载入了旧版本的.proto文件将会导致严重的问题,例如数据损坏。一种避免问题产生的方式是指定保留的字段编号和字段名称。如果将来有人用了这些字段编号将在编译proto的时候产生错误,显示提醒proto有问题。NOTE,不要对同一个字段混合使用字段名称和字段编号。
message Foo { reserved 2, 15, 9 to 11; reserved "foo", "bar"; }1
2
3
4
# protobuf 数据格式
protobuf 是用二进制来表示数据,可读性差
xml 格式
<person> <id>91890</id> </person>1
2
3json 格式
{ "id":91890 }1
2
3用protobuf表示如下, 它直接用二进制来表示数据,不像上面XML和JSON格式那么直观的看到表示的内容。
00010000 10100001 11001101 00000101 // 二进制1- 00010000 10100001 11001101 00000101的第一个字节 :表示的是数据的序号和类型,编码方式是varient
- 00010000 表示是否解析到了本次varient的最后一个字节
- 00010000 表示序号,十进制2,即id的序号
- 00010000 表示该字段的类型,000表示int32类型
# 编码原理
protobuf高效的秘密在于它的编码格式,它采用了TLV(tag-length-value)编码格式。
每个字段都有唯一的tag值,它是字段的唯一标识。length表示value数据的长度,length不是必须的,对于固定长度的value,是没有length的。value是数据本身的内容。

对于tag值,它有field_number和wire_type两部分组成。field_number就是在前面的message中我们给每个字段的编号,wire_type表示类型,是固定长度还是变长的。wire_type当前有0到5一共6个值,所以用3个bit就可以表示这6个值。tag结构如下图。
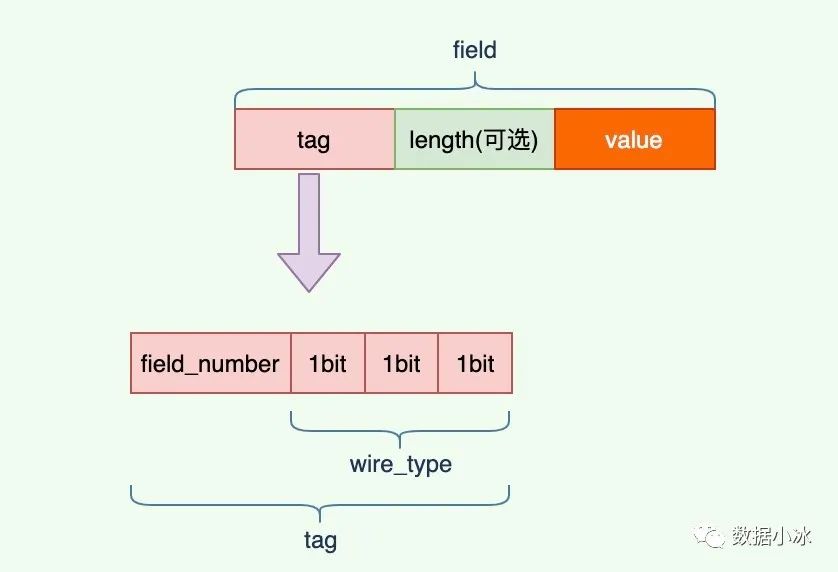
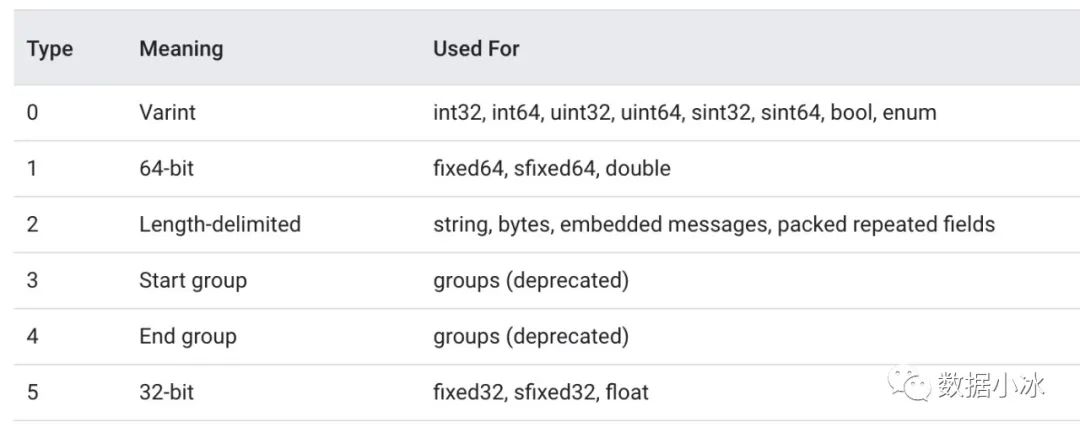
wire_type值如下表, 其中3和4已经废弃,我们只需要关心剩下的4种。对于Varint编码数据,不需要存储字节长度length.这种情况下,TLV编码格式退化成TV编码。对于64-bit和32-bit也不需要length,因为type值已经表明了长度是8字节还是4字节。
# 1. varint 编码原理
Varint顾名思义就可变的int,是一种变长的编码方式。值越小的数字,使用越少的字节表示,通过减少表示数字的字节数从而进行数据压缩。对于int32类型的数字,一般需要4个字节表示,但是采用Varint编码,对于小于128的int32类型的数字,用1个字节来表示。对于很大的数字可能需要5个字节来表示,但是在大多数情况下,消息中一般不会有很大的数字,所以采用Varint编码可以用更少的字节数来表示数字。
Varint是变长编码,那它是怎么区分出各个字段的呢?也就是怎么识别出这个数字是1个字节还是2个字节,Varint通过每个字节的最高位来识别,如果字节的最高位是1,表示后续的字节也是该数字的一部分,如果是0,表示这是最后一个字节,且剩余7位都用来表示数字。虽然这样每个字节会浪费掉1bit空间,也就是1/8=12.5%的浪费,但是如果有很多数字不用固定的4字节,还是能节省不少空间。
- int32类型的数字 1的varint编码
- 1 的二进制编码
00000000 00000000 00000000 00000001, 从左到右是高位->低位 - 取最低位7位
000 00001,余下都是0,高位补0,表示这是最后一个字节,得到0000 0001 - 因为其没有后续字节, 因此其最高有效位为 0, 其余的 7 位以补码形式存放 1
- 1 的二进制编码
- int32类型的数字 666 的varint编码
- 666 的二进制编码
00000000 00000000 00000010 10011010 - 取最低位7位
0011010,余下不都是0,高位补110011010 - 依次再取低位7位
0000101,余下都是0,高位补000000101 - 拼接得到varint编码:
10011010 00000101, Base128 Varints 采用小端字节序, 因此数字的高位存放于低地址上
- 666 的二进制编码
- 通过 varint编码 推导int32
- varint编码:
10011010 00000101 - 移除标志位(每个字节首位)并交换字节顺序 得到
000010 10011010 - 与666的二进制相同
- varint编码:
# 2. Zigzag 编码原理
负数的符号位为数字的最高位,它的最高位是1,所以对于负数用Varint编码一定为占用5个字节。这是不划算的,明明是4字节可以搞定的,现在统统都需要5个字节。所以protobuf定义了sint32和sint64类型来表示负数,先采用Zigzag编码,将有符号的数转成无符号的数,在采用Varint编码,从而减少编码后字节数。
Zigzag采用无符号数来表示有符号数,使得绝对值小的数字可以采用比较少的字节来表示。在理解Zigzag编码之前,我们先来看几个概念。
原码:最高位为符号位,剩余位表示绝对值
反码:除符号位外,对原码剩余位依次取反
补码:对于正数,补码为其本身,对于负数,除符号位外对原码剩余位依次取反然后+1
int32 的数字 -2 Zigzag编码示例
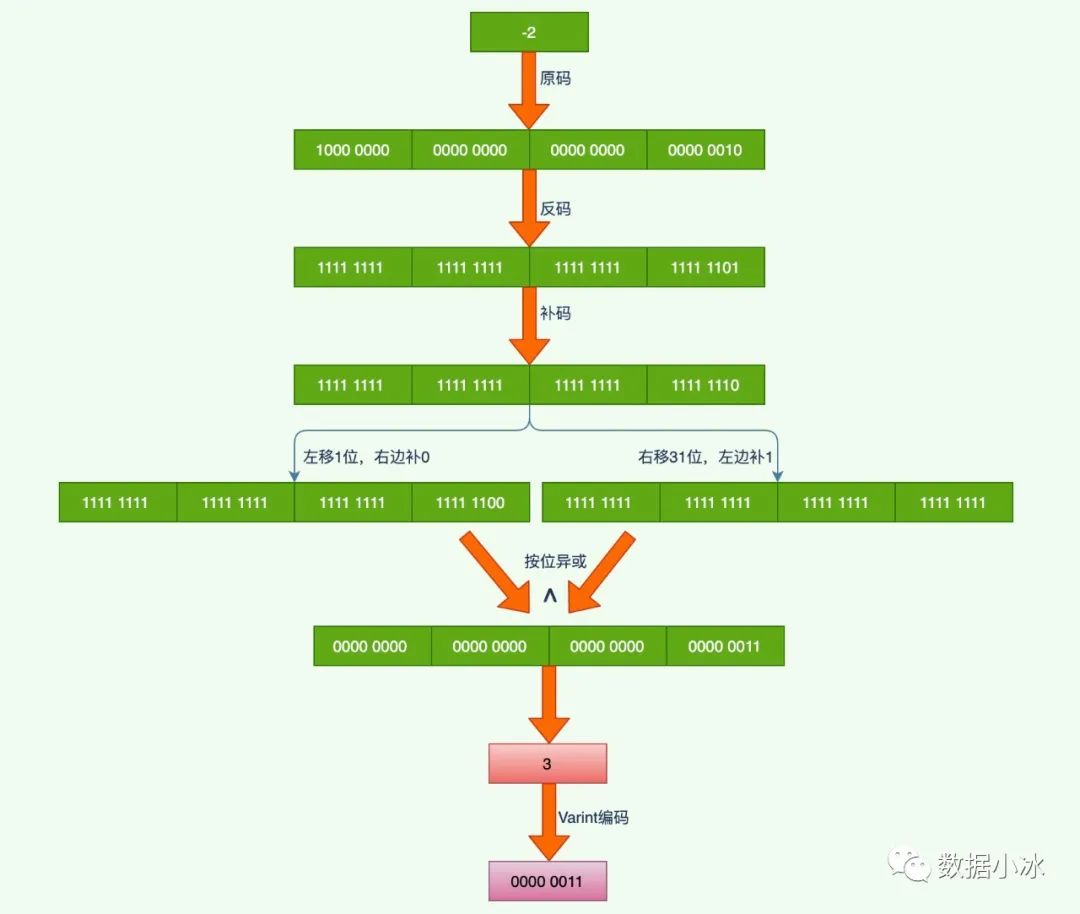
总结起来,对于负数对其补码做运算操作,对于数n,如果是sint32类型,则执行(n<<1)^(n>>31)操作,如果是sint64则执行(n<<1)^(n>>63), 通过前面的操作将一个负数变成了正数。这个过程就是Zigzag编码,最后在采用Varint编码。
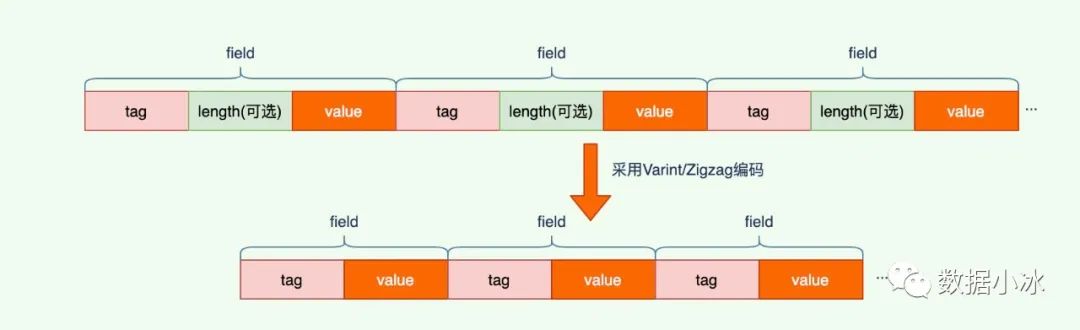
因为Varint和Zigzag编码可以自解析内容的长度,所以可以省略长度项。TLV存储简化为了TV存储,不需length项。
# protobuf与json的编码对比
json数据
{ "id": 666 }1
2
3protobuf编码后的数据格式
00010000 10100001 11001101 00000101 // 第一个字节表示序号和字段类型 即序号为2,类型为int的字段, 后三个字节表示数据的值,值为918901
2
问题:id这个字段名去哪儿了?
答案:id的字段名被protobuf舍弃了,protobuf最终的编码结果是抛弃了所有的字段名,仅仅保留了字段的序号、类型和数据的值。
# protobuf 特性
# 1. 基本特性
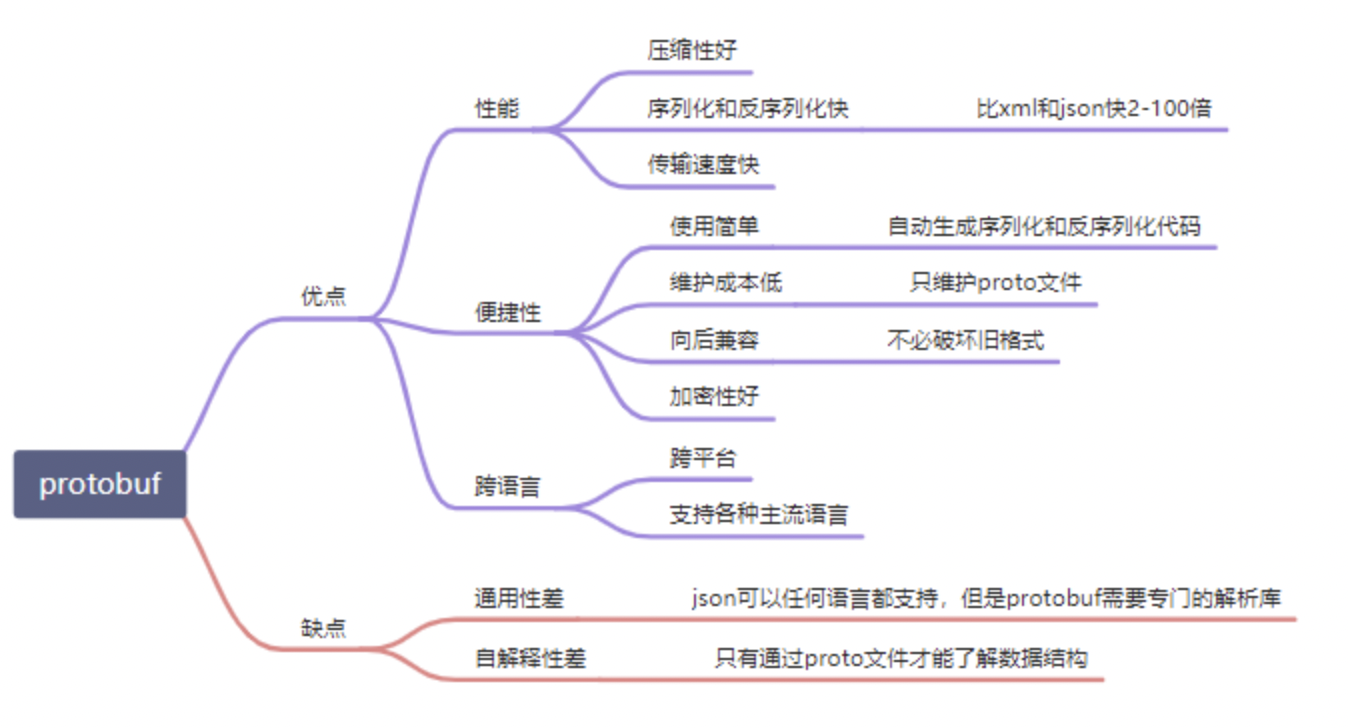
# 2. 编码特性
- protobuf的解码不需要类型相同,也不需要字段名相同
- protobuf的解码依赖于序号的正确性
- protobuf中的序号大小会影响最终编码大小
- protobuf的对象类型可以向String类型兼容
- protobuf可以和json完全兼容,且编码字节数要比json少
参考资料
https://zhuanlan.zhihu.com/p/537871378
https://mp.weixin.qq.com/s/wZJzkKqNAsRE7Wyan_RXfg
https://mp.weixin.qq.com/s/wJpTgAcFX50naaBNXvjEIw