 redis集群模式
redis集群模式
# 集群工作原理
单机瓶颈: Redis在单机架构下的瓶颈:master节点的数据和slave节点的数据量一样,也就是master容纳多少,slave也只能容纳多少,如果需要放1T数据,在缓存中,那么就遇到的性能瓶颈了。
集群模式: 支撑N个redis master node,每个master node都可以挂载多个slave node,读写分离的架构,对于每个master来说,写就写到master,然后读就从mater对应的slave去读,高可用,因为每个master都有salve节点,那么如果mater挂掉,redis cluster这套机制,就会自动将某个slave切换成master,redis cluster(多master + 读写分离 + 高可用),我们只要基于redis cluster去搭建redis集群即可,不需要手工去搭建replication复制+主从架构+读写分离+哨兵集群+高可用
# 集群模式和高可用哨兵模式
# 1. Redis Cluster
是Redis的集群模式
自动将数据进行分片,每个master上放一部分数据
提供内置的高可用支持,部分master不可用时,还是可以继续工作的
在redis cluster架构下,每个redis要放开两个端口号,比如一个是6379,另外一个就是加10000的端口号,比如16379端口号是用来进行节点间通信的,也就是cluster bus的东西,集群总线。cluster bus的通信,用来进行故障检测,配置更新,故障转移授权
# 2. replication + sentinel
高可用模式
如果你的数据量很少,主要是承载高并发高性能的场景,比如你的缓存一般就几个G,单机足够了,replication,一个mater,多个slave,要几个slave跟你的要求的读吞吐量有关系,然后自己搭建一个sentinal集群,去保证redis主从架构的高可用性,就可以了
redis cluster,主要是针对海量数据+高并发+高可用的场景,海量数据,如果你的数据量很大,那么建议就用redis cluster
# 集群数据分布的算法
- hash算法
- hash一致性算法
- redis cluster,hash slot 算法
# 1. hash算法
假设有4个redis节点,分别是redis0,redis1,redis2,redis3;有20个数据,这20个数据需要尽可能均匀地存储在这4个redis节点上。传统的做法是:将这20个数据(key)进行hash运算(如果是string类型,可以直接哈希。如果是文件,可以对唯一的文件名进行哈希),hash后的值和4(节点数量)进行取余运算,算出来是什么结果就落在哪个节点上。比如经过hash取余运算后结果为0,就存储在redis0节点;结果为1,存储在redis1节点;结果为2,存储在redis2节点,以此类推......
读取数据的时候,根据数据(key)进行hash运算,然后和节点数进行取余,就能得出数据存储在哪个节点了,进而读出数据。
这种算法能够使各个redis节点比较均匀地分担压力,和HashMap和类似。
缺点:
- 如果增加redis节点或者删除redis节点(这种情形很常见),因为节点数量改变了,所以会导致数据(key)进行hash后和节点数取余的结果发生改变,不能定位到之前的redis节点,无法从缓存中读取数据,这时就会直接从DB中读取,会造成redis穿透,甚至系统奔溃。一般在redis节点改变的时候,会在极短的时间内将缓存中的数据在redis节点之间进行重分配。
- 数据命中:即节点数量改变后不受影响的数据(少部分数据在节点数量改变前和改变后key的hash值取余后,值没发生变化)。这种算法数据命中率很低。
# 2. 一致性Hash算法
首先对节点进行哈希计算,哈希值通常在 2^32-1 范围内。然后将 2^32-1 这个区间首尾连接抽象成一个环并将节点的哈希值映射到环上,当我们要查询 key 的目标节点时,同样的我们对 key 进行哈希计算,然后顺时针查找到的第一个节点就是目标节点。
- 根据原理我们分析一下节点添加和删除对数据范围的影响。
节点添加
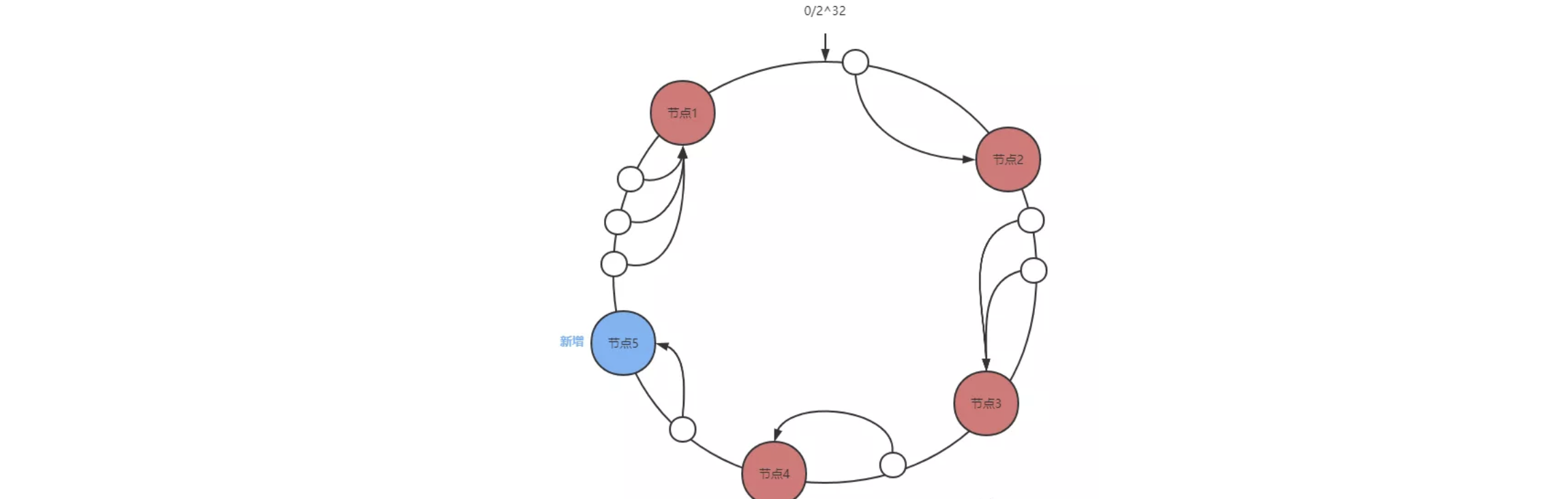
只会影响新增节点与前一个节点(新增节点逆时针查找的第一个节点)之间的数据。
节点删除
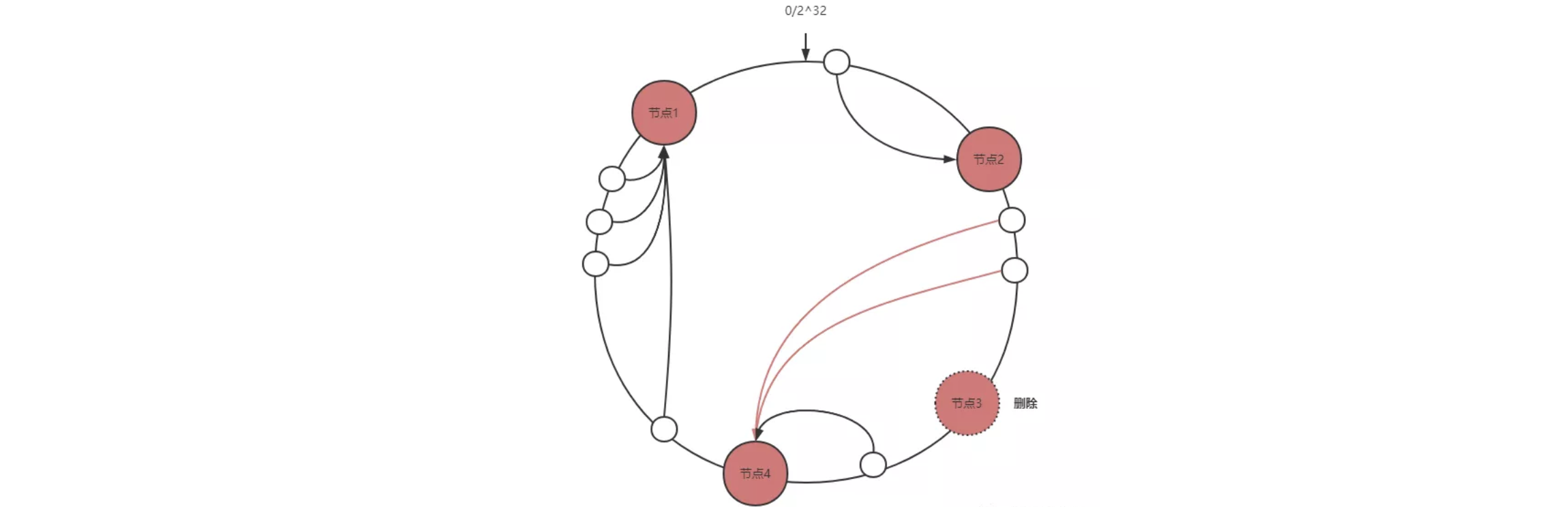
只会影响删除节点与前一个节点(删除节点逆时针查找的第一个节点)之间的数据。
这样就完了吗?还没有,试想一下假如环上的节点数量非常少,那么非常有可能造成数据分布不平衡,本质上是环上的区间分布粒度太粗。
怎么解决呢?不是粒度太粗吗?那就加入更多的节点,这就引出了一致性哈希的虚拟节点概念,虚拟节点的作用在于让环上的节点区间分布粒度变细。
一个真实节点对应多个虚拟节点,将虚拟节点的哈希值映射到环上,查询 key 的目标节点我们先查询虚拟节点再找到真实节点即可。
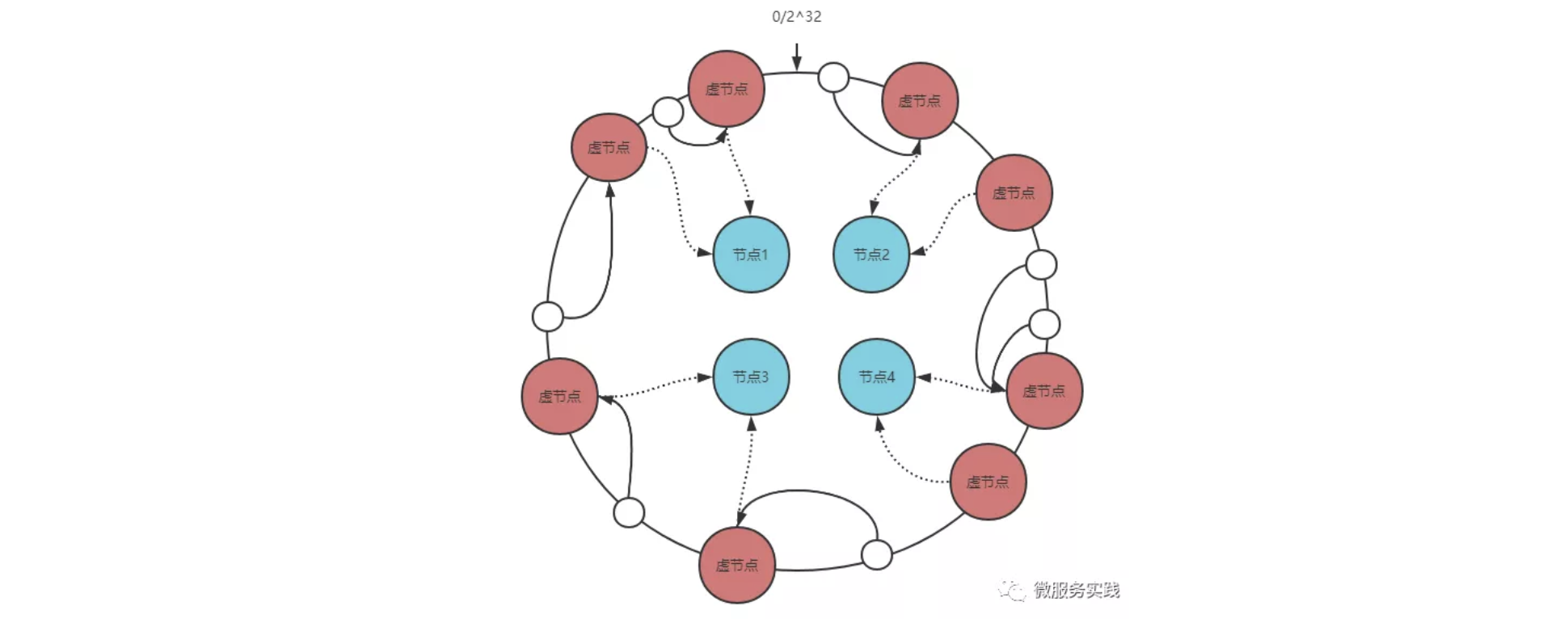
- 解决了缓存热点问题: 引入了虚拟环(虚拟节点)的概念,目的是为了让每个master都做了均匀分布,这样每个区间内的数据都能够 均衡的分布到不同的节点中,而不是按照顺时针去查找
# 3. hash slot 算法
- Redis Cluster有固定的16384(2^14)个Hash slot,对每个key计算CRC16值,然后对16384取模,可以获取key对应的hash slot,redis cluster中每个master都会持有部分slot,比如有3个master,那么可能每个master持有5000多个hash slot
- hash slot让node的增加和移除很简单,增加一个master,就将其他master的hash slot移动部分过去,减少一个master,就将它的hash slot移动到其他master上去,移动hash slot的成本是非常低的,客户端的api,可以对指定的数据,让他们走同一个hash slot,通过hash tag来实现
- 如果有一台master宕机了,其它节点上的缓存几乎不受影响,因为它取模运算是根据 Hash slot来的,也就是 16384,而不是根据Redis的机器数。
# 集群高可用性与主备切换原理
判断节点宕机
- 如果一个节点认为另外一个节点宕机,那么就是pfail,主观宕机,如果多个节点都认为另外一个节点宕机了,那么就是fail,客观宕机,跟哨兵的原理几乎一样,sdown,odown,在cluster-node-timeout内,某个节点一直没有返回pong,那么就被认为pfail,如果一个节点认为某个节点pfail了,那么会在gossip ping消息中,ping给其他节点,如果超过半数的节点都认为pfail了,那么就会变成fail
从节点过滤
- 对宕机的master node,从其所有的slave node中,选择一个切换成master node,检查每个slave node与master node断开连接的时间,如果超过了cluster-node-timeout * cluster-slave-validity-factor,那么就没有资格切换成master,这个也是跟哨兵是一样的,从节点超时过滤的步骤
从节点选举
- 哨兵:对所有从节点进行排序,slave priority,offset,run id,每个从节点,都根据自己对master复制数据的offset,来设置一个选举时间,offset越大(复制数据越多)的从节点,选举时间越靠前,优先进行选举,所有的master node开始slave选举投票,给要进行选举的slave进行投票,如果大部分master node(N/2 + 1)都投票给了某个从节点,那么选举通过,那个从节点可以切换成master,从节点执行主备切换,从节点切换为主节点
与哨兵比较
- 整个流程跟哨兵相比,非常类似,所以说,redis cluster功能强大,直接集成了replication和sentinal的功能