 分库分表带来的读扩散问题
分库分表带来的读扩散问题
# 场景描述
- 项目: 某项目
- 数据库: tdpg, tdmysql (鹅厂出品)
- 背景: tdmysql数据查询慢, tdpg查询慢
# 前戏
# 1. 分库分表
- 比如你单表都几千万数据了,你确定你能抗住么?绝对不行,单表数据量太大,会极大影响你的sql执行的性能,到了后面你的sql可能就跑的很慢了。一般来说,就以我的经验来看,单表到几百万的时候,性能就会相对差一些了,你就得分表了。
- 分表: 就是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户id来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在200万以内。
- 分库: 就是你一个库一般我们经验而言,最多支撑到并发2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒1000左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
# 1.1 水平拆分
- 水平拆分的意思,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。
- 水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来抗更高的并发,还有就是用多个库的存储容量来进行扩容
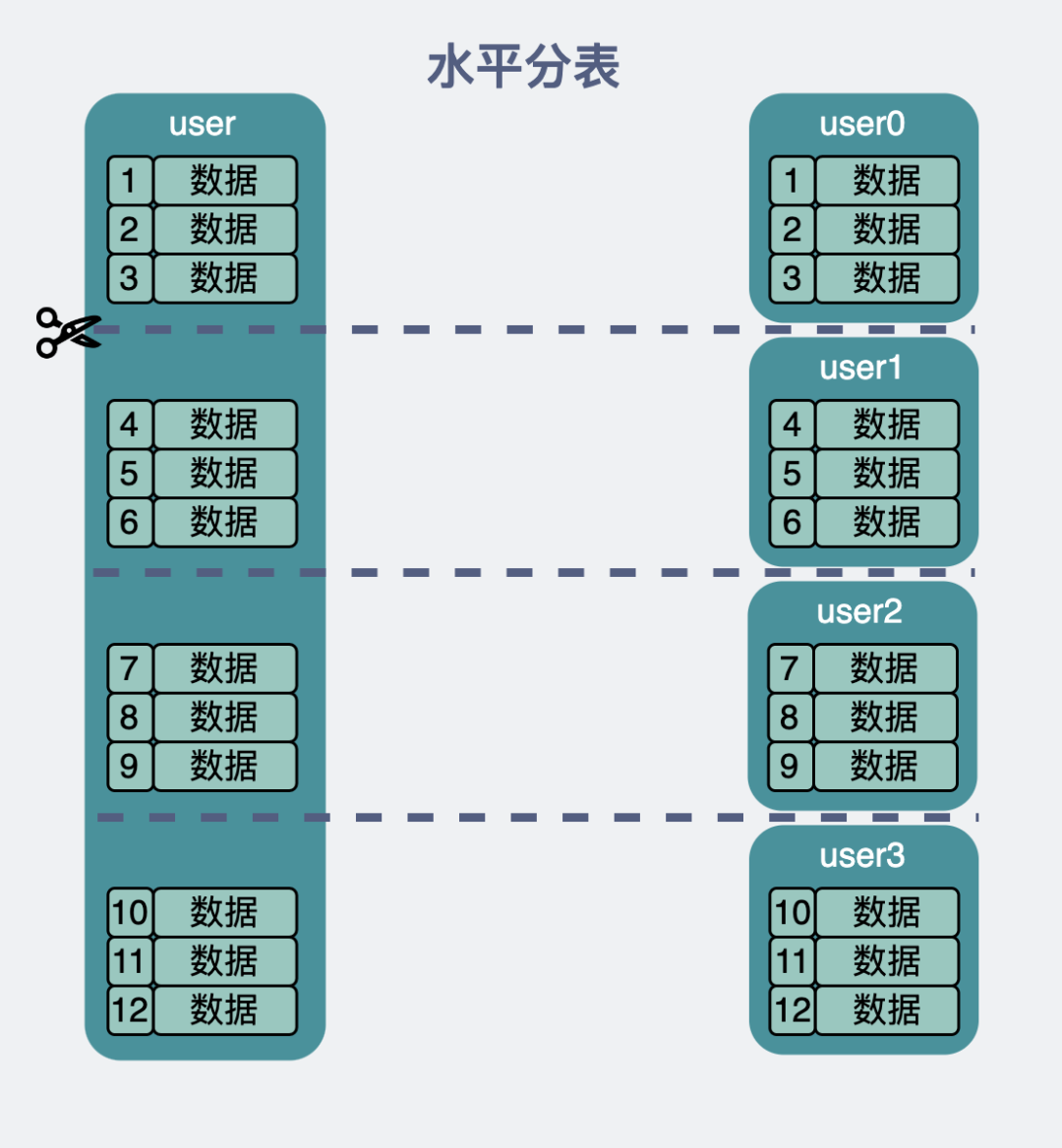
拆分方式
根据id范围分表
- 优点: 简单.
- 缺点:根据id范围去做分表,因为id是递增的,那新写入的数据一般都会落到某一张表上,如果你的业务场景写数据特别频繁,那这张表就会出现写热点的问题。
根据id取模分表
- 优点: 当然是比较简单。而且读写数据都可以很均匀的分摊到每个分表上。
- 缺点: 如果想要扩展表的个数, 模就跟跟原来就对不上了。
将上面两种方式结合起来
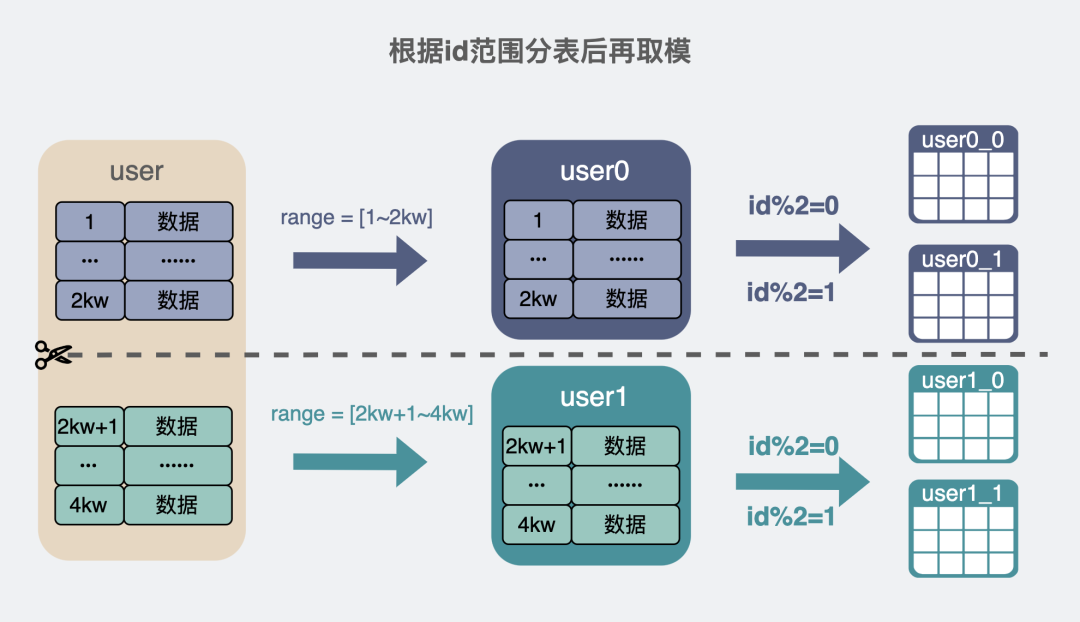
# 1.2 垂直拆分
- 垂直拆分的意思,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。
- 还有表层面的拆分,就是分表,将一个表变成N个表,就是让每个表的数据量控制在一定范围内,保证SQL的性能。否则单表数据量越大,SQL性能就越差。一般是200万行左右,不要太多,但是也得看具体你怎么操作,也可能是500万,或者是100万。你的SQL越复杂,就最好让单表行数越少。
# 2. 读扩散
上面提到的好几种分表方式,都用了id这一列作为分表的依据,这其实就是所谓的分片键。一般用数据库主键作为分片键。
读扩散是怎么产生的呢?
- 在分表之后, 数据会分配到不同表中,甚至不同库中
- 某一张表(
id-分片键,name)分表之后产生了100张表 - 查询sql
select * from name = 'Pig' - name不是分片键, 最坏需要查询100次sql,
- 这个时候就产生了读扩散问题!
# 读扩散解决办法
# 1. 创建影子表(映射表)
鹅厂工程师培训
tdmysql建议方法
读扩散问题的核心在于,主键是分片键,而普通索引列并不分片。创建影子表就是为了维护普通索引列和分片键的关系
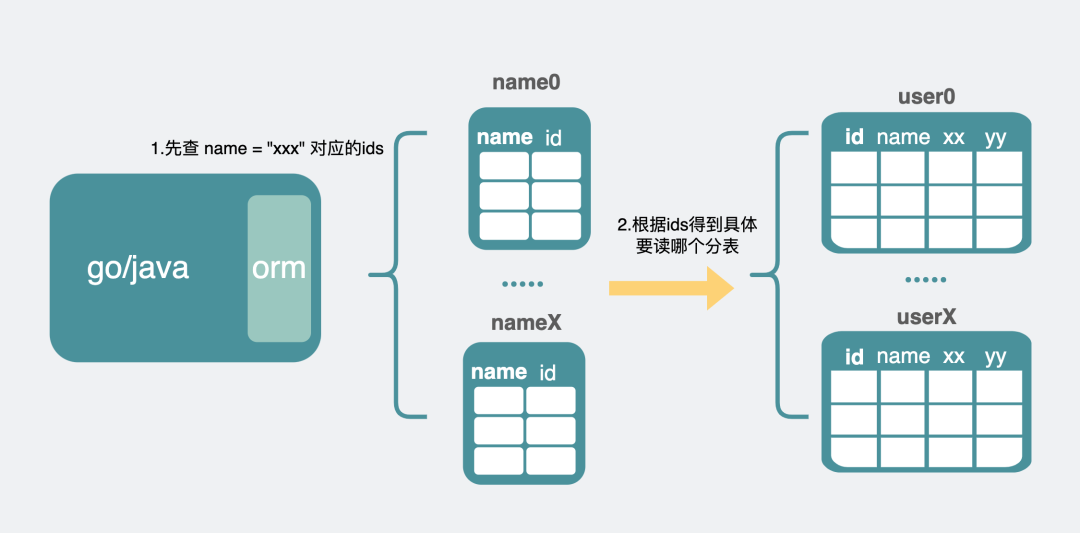
当我们要查询普通索引列时,先到这个新的分片表里做一次查询,就能迅速定位到对应的主键id,然后再拿主键id去旧的分片表里查一次数据。这样就从原来漫无目的的全表扩散查询,缩减为只查固定几个表了。
缺点:
- 影子表维护很复杂, 需要维护两套表,并且普通索引列更新时,要两张表同时进行更改。
- 使用不方便,
# 2.选用es
某项目生产环境即将采用的办法...
利用倒排索引的思路去解决分表下的数据查询问题
将mysql接入es也非常简单,可以通过开源工具
canal监听mysql的binlog日志变更,再将数据解析后写入es,这样es就能提供近实时的查询能力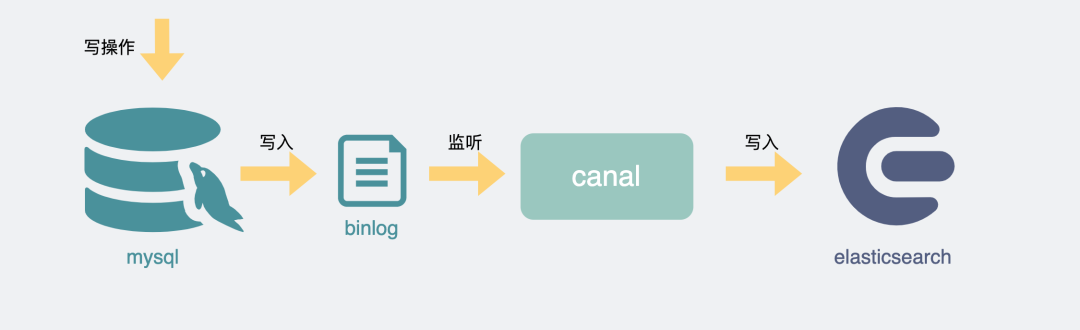
# 3. 使用TiDB
- TiDB 是一个分布式 NewSQL 数据库。它支持水平弹性扩展、ACID 事务、标准 SQL、MySQL 语法和 MySQL 协议,具有数据强一致的高可用特性,是一个不仅适合 OLTP 场景还适OLAP 场景的混合数据库。
- 它通过引入Range的概念进行数据表分片,比如第一个分片表的id在0~2kw,第二个分片表的id在2kw~4kw。
上次更新: 2023/04/16, 18:35:33