 Service网络
Service网络
# 服务发现和负载均衡
使用k8s部署服务,所有的服务都部署在pod内部的容器中,服务集群就需要多个pod副本实现。
那么多个pod副本实现负载均衡访问,我们第一想到的是使用nginx转发, nginx也在一个pod中
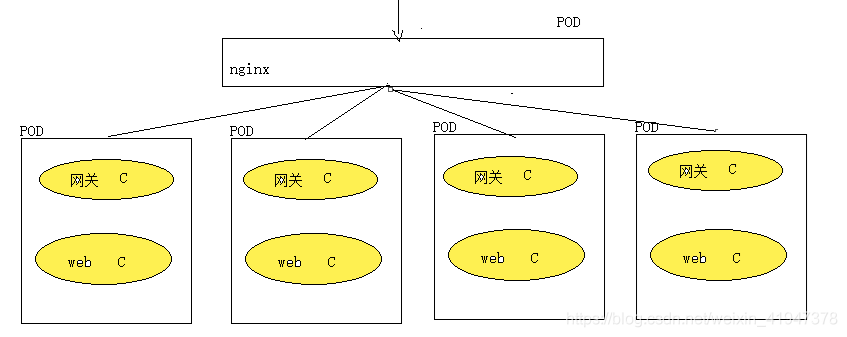
问题: Pod是一个服务进程,有生命周期,并且pod随时可能宕机,k8s立马对pod进行重建,但是此时重建的pod的ip,hostname都发生了变化(无状态的pod)。此时nginx还能访问重建的pod吗??
答案:nginx作为pod副本的负载均衡服务器,无法发现k8s重建,或者新建的pod,也就是说k8s重建的,新建的pod,使用nginx无法访问。因此使用nginx作为pod副本负载均衡访问服务,是无法实现的。所以就引入了service。
# Service相关概念
k8s 的服务(service)暴露service的三种方式ClusterIP、NodePort与LoadBalance,这 几种方式都是在service的维度提供的,单独用service暴露服务的方式,在实际生产 环境中不太合适:
ClusterIP的方式只能在集群内部访问。
NodePort方式的话,测试环境使用还行,当有几十上百的服务在集群中运行时NodePort的端口管理是灾难。
LoadBalance方式受限于云平台,且通常在云平台部署ELB还需要额外的费用。
k8s还提供了一种集群维度暴露服务的方式,也就是ingress。ingress可以简单理解为service的service,他通过独立的ingress对象来制定请求转发的规则,把请求路由到一个或多个service中。这样就把服务与请求规则解耦了,可以从业务维度统一考虑业务的暴露,而不用为每个service单独考虑。
Service是一个抽象的概念。它通过一个虚拟的IP的形式(VIPs),映射出来指定的端口,通过代理客户端发来的请求转发到后端一组Pods中的一台(也就是endpoint)
Service定义了Pod逻辑集合和访问该集合的策略,是真实服务的抽象。Service提供了统一的服务访问入口以及服务代理和发现机制,关联多个相同Label的Pod,用户不需要了解后台Pod是如何运行。
外部系统访问Service
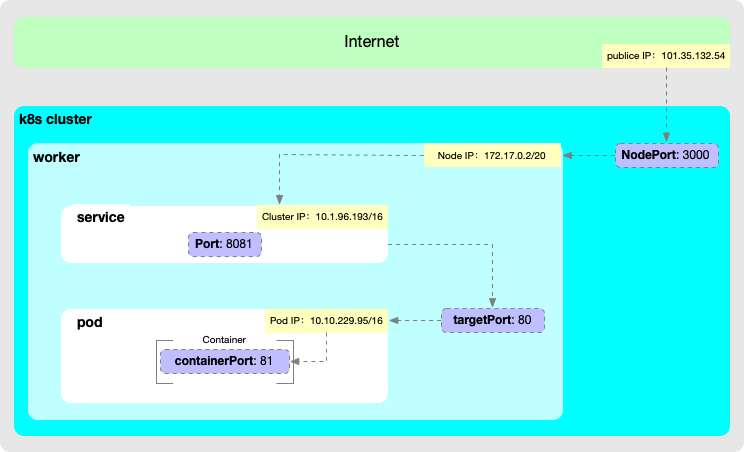
Node IP:Node节点的IP地址
Node IP是Kubernetes集群中节点的物理网卡IP地址,所有属于这个网络的服务器之间都能通过这个网络直接通信。这也表明Kubernetes集群之外的节点访问Kubernetes集群之内的某个节点或者TCP/IP服务的时候,必须通过Node IP进行通信
Cluster IP:Service的IP地址(虚拟)
最后Cluster IP是一个虚拟的IP,但更像是一个伪造的IP网络,原因有以下几点:
Cluster IP仅仅作用于Kubernetes Service这个对象,并由Kubernetes管理和分配P地址
Cluster IP无法被ping,他没有一个“实体网络对象”来响应
Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备通信的基础,并且他们属于Kubernetes集群这样一个封闭的空间。Kubernetes集群之内,Node IP网、Pod IP网于Cluster IP网之间的通信,采用的是Kubernetes自己设计的一种编程方式的特殊路由规则。
Pod IP: Pod的IP地址(虚拟)
Pod IP是每个Pod的IP地址,他是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络。
# Service VIP(ClusterIP)
Client只需通过ClusterIP就可以访问背后的Pod集群,不需要关心集群中的具体Pod数量和PodIP,即使是PodIP发生变化也会被ClusterIP所屏蔽。注意,这里的ClusterIP实际是个虚拟IP,也称Virtual IP(VIP)。
Service VIP 是一个服务、进程,运行在每个node节点上,是一个独立的网关入口,它的高可用 由etcd保证,这个服务用的映射数据是存在etcd上的
Service VIP 是 k8s 提供一个虚拟IP, Service 就是一个虚拟ip的资源对象。Service VIP就相当于是服务网关,所有的请求都要被service VIP进行拦截,然后进行转发,它屏蔽了底层 pod Ip,hostname变化所造成的影响,使得用户不需要关心pod在底层到底是如何变化的,或者不需要关心pod的ip,hostname是如何变化。
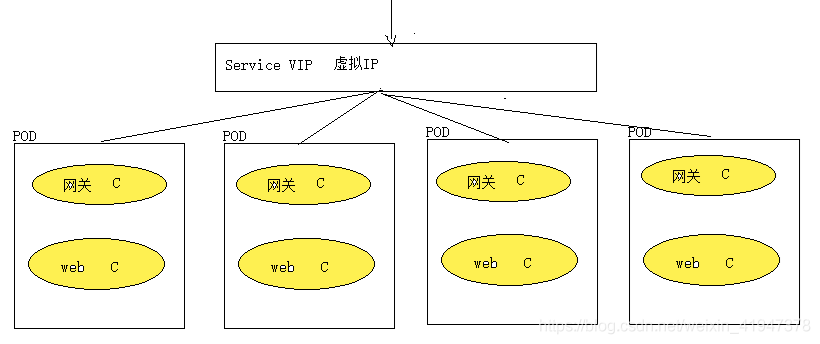
注意:service VIP 一旦创建就不会发生变化,service VIP高可用性由etcd来保证,service VIP作为一组pod业务的统一网关入口。
# Service 网络原理
VIP 其实现原理主要是靠TCP/IP的ARP协议。因为ip地址只是一个逻辑地址,在以太网中MAC地址才是真正用来进行数据传输的物理地址,每台主机中都有一个ARP高速缓存,存储同一个网络内的IP地址与MAC地址的对应关 系,以太网中的主机发送数据时会先从这个缓存中查询目标IP对应的MAC地址,会向这个MAC地址发送数据。操作系统会自动维护这个缓存,这就是整个实现 的关键。
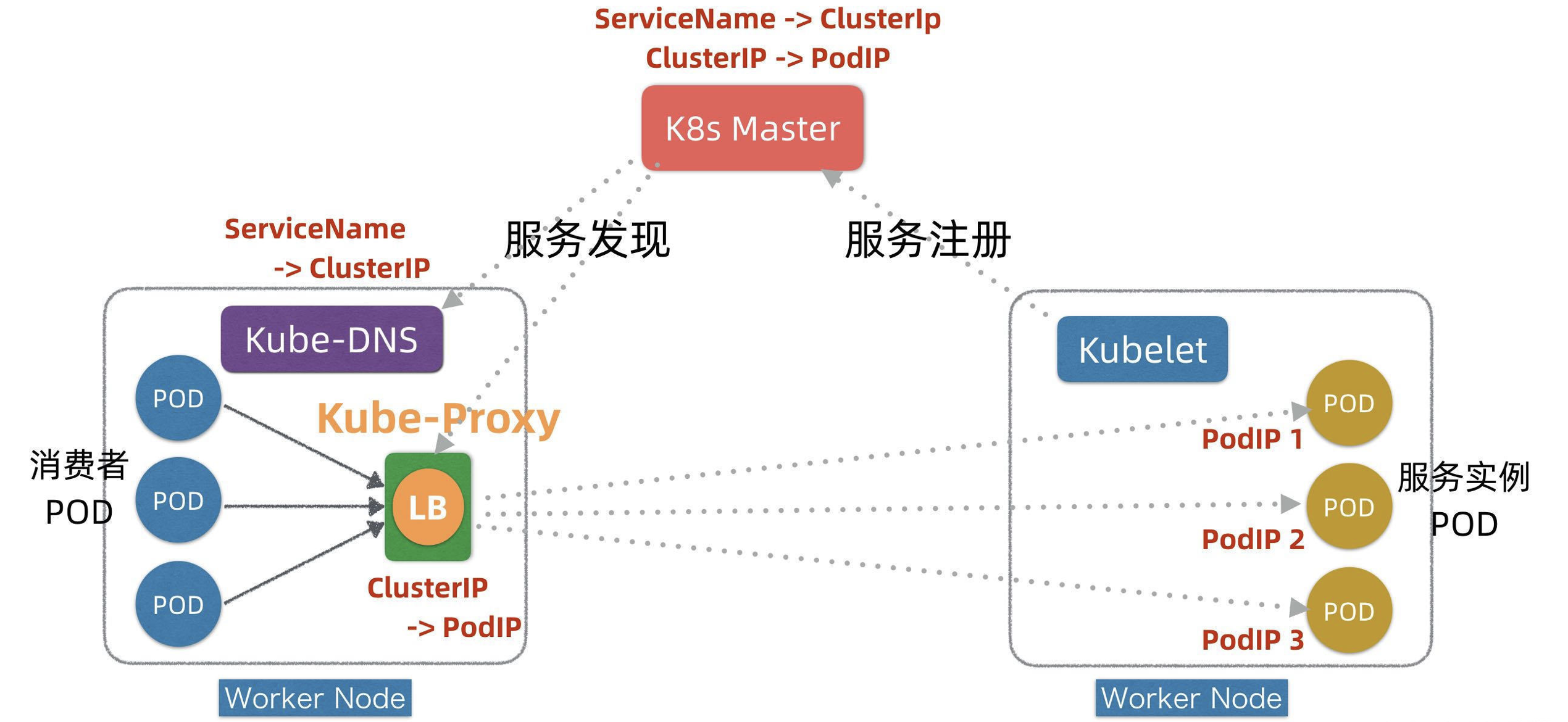
在K8s平台的每个Worker节点上,都部署有两个组件,一个叫Kubelet,另外一个叫Kube-Proxy,这两个组件+Master是K8s实现服务注册和发现的关键。下面我们看下简化的服务注册发现流程。
kubelet 是 k8s 在node节点上的代理服务。pod的CRUD的是由node节点上kubelet来进行操作。kubelet实际上就相当于链式调用,上游服务是master(scheduler,apiserver),由node的kubelet接受请求,执行具体操作。
kube-proxy 监听 apiserver 中service 与Endpoint 的信息, 配置iptables 规则,请求通过iptables 直接转发给 pod
- 首先,在服务Pod实例发布时(可以对应K8s发布中的Kind: Deployment),Kubelet会负责启动Pod实例,启动完成后,Kubelet会把服务的PodIP列表汇报注册到Master节点。
- 其次,通过服务Service的发布(对应K8s发布中的Kind: Service),K8s会为服务分配ClusterIP,相关信息也记录在Master上。
- 第三,在服务发现阶段,Kube-Proxy会监听Master并发现服务ClusterIP和PodIP列表映射关系,并且修改本地的linux iptables转发规则,指示iptables在接收到目标为某个ClusterIP请求时,进行负载均衡并转发到对应的PodIP上。
- 运行时,当有消费者Pod需要访问某个目标服务实例的时候,它通过ClusterIP发起调用,这个ClusterIP会被本地iptables机制截获,然后通过负载均衡,转发到目标服务Pod实例上。
实际消费者Pod也并不直接调服务的ClusterIP,而是先调用服务名,因为ClusterIP也会变(例如针对TEST/UAT/PROD等不同环境的发布,ClusterIP会不同),只有服务名一般不变。为了屏蔽ClusterIP的变化,K8s在每个Worker节点上还引入了一个KubeDNS组件,它也监听Master并发现服务名和ClusterIP之间映射关系,这样, 消费者Pod通过KubeDNS可以间接发现服务的ClusterIP。
# 1. pod负载均衡流程
K8s中的代理转发是iptables转发,虽然K8s中有Kube-Proxy,但它只是负责服务发现和修改iptables(或ipvs)规则,实际请求是不穿透Kube-Proxy的。
k8s 几类ip
- Node IP: 物理机节点IP地址
- Cluster IP:虚拟机IP,由k8s抽象出的service资源对象具有的IP地址,此ip地址类型默认就是clusterIP, 此类型只能在局域网进行通信,无法对外网提供服务。
- Pod IP:POD 进程IP地址
负载均衡流程
- 在物理机开辟一个端口,实现数据包(请求)转发
- 创建service VIP 资源对象,实现物理端口和service VIP 端口关系映射,从而从物理机端口转发的请求自动转发给service VIP
- service 资源对象通过iptables,根据转发策略,把请求转发给相应的Pod.
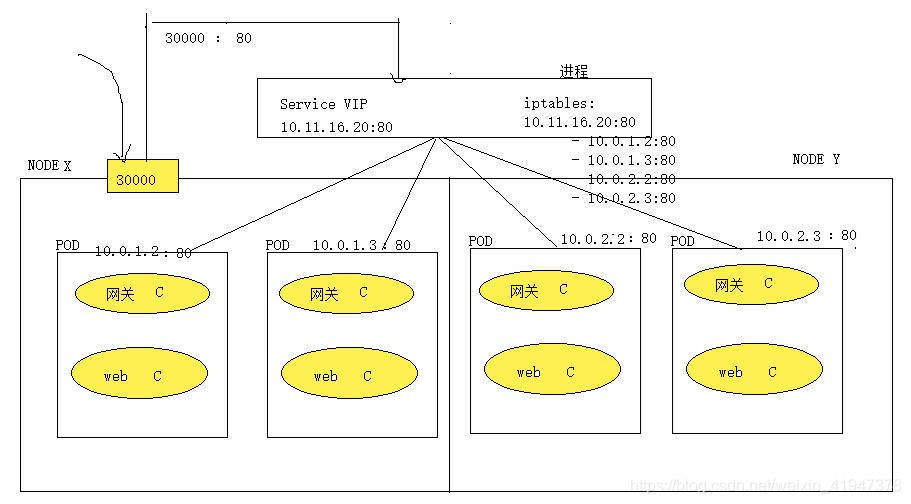
- 图中 ServiceVIP 实际上是每个node节点内部的一个进程,抽出来是为了方便理解、画图
- 而ServiceVIP中的映射数据是存在etcd的
- iptables中 10.11.16.20:80 这个地址映射了四个pod地址
- 物理机node开辟一个端口,外网访问这个物理机地址对应的端口,则将请求转发给该端口对应的映射的Service VIP,再由Service VIP通过iptables实现负载均衡、路由到对应的pod上
# 2. Service关联pod
Service和pod如何关联起来的,service是通过标签选择器选择一组相关的pod。通常来说service只对一组相关的pod副本提供服务。多个业务pod,就应该有多个service。
一个业务组pod副本,对应一个service:
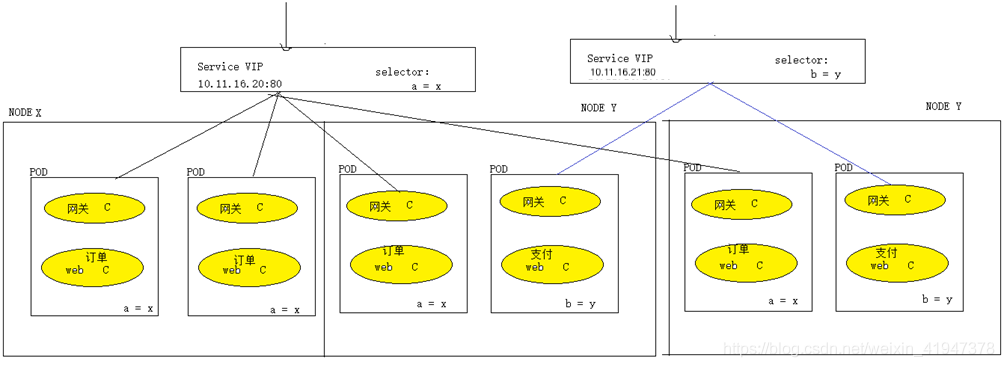
一个Service VIP对应一个虚拟地址
# 3. Pod服务发现
kube-proxy在每一个node节点都存在一个进程,每一个node节点中kube-proxy都会监控pod(不只监听本地节点的)的ip地址变化,发现pod的ip地址发生了变化,把变化的ip的更新到service资源对象的endpoints. 使得service vip可以及时感知到pod ip的变化,从而可以实现更好的,及时的,稳定的访问。
Pod宕机,当k8s重建pod后,pod的ip地址,hostname发现了变化,service VIP 可以感知到pod ip,hostname已经发生了变化。K8s node节点中提供一个核心组件:
kube-proxy,这个代理组件主要用来实现服务发现,路由规则改写。kube-proxy 进程 可以书写负载均衡的规则,实际上就去修改etcd
每个节点中都有 一个 kube-proxy 组件,即每个节点都会运行一个 kube-proxy 进程,它会做两件事:
- 监听pod
- 一但pod发生变化,就会修改ServiceVIP 映射iP的规则,即endpoints资源对象,每个endpoint对应一个pod
k8s所有的资源对象都存储在etcd, 所有的资源对象都可以用yaml资源配置文件方式进行表示,因此这些资源以yaml方式存储
# kube-proxy的三种代理模式
kubernetes里kube-proxy支持三种模式,在v1.8之前我们使用的是iptables 以及 userspace两种模式,在kubernetes 1.8之后引入了ipvs模式,并且在v1.11中正式使用,其中iptables和ipvs都是内核态也就是基于netfilter,只有userspace模式是用户态。
- user space
- iptables
- ipvs
# 1. User space模式
在这种模式下,kube-proxy通过观察Kubernetes中service和endpoint对象的变化,当有新的service创建时,所有节点的kube-proxy在node节点上随机选择一个端口,在iptables中追加一条把访问service的请求重定向到这个端口的记录,并开始监听这个端口的连接请求。
比如说创建一个service,对应的IP:1.2.3.4,port:8888,kube-proxy随机选择的端口是32890,则会在iptables中追加
-A PREROUTING -j KUBE-PORTALS-CONTAINER -A KUBE-PORTALS-CONTAINER -d 1.2.3.4/32 -p tcp --dport 8888 -j REDIRECT --to-ports 328901
2
3执行过程
- 当有请求访问service时,在PREROUTING阶段,将请求jump KUBE-PORTALS-CONTAINER
- KUBE-PORTALS-CONTAINER 中的这条记录起作用,把请求重定向到kube-proxy刚监听的端口32890上,数据包进入kube-proxy进程内,
- 然后kube-proxy会从这个service对应的endpoint中根据SessionAffinity来选择一个作为真实服务响应请求。
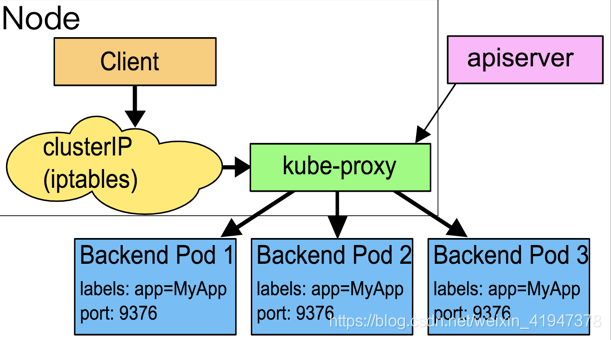
缺点:请求数据需要到kube-proxy中,就是用户空间中,才能决定真正要转发的实际服务地址,性能会有损耗。并且在应用执行过程中,kube-proxy的可用性也会影响系统的稳定
# 2. iptables 模式(默认) !!!
Iptables模式为Services的默认代理模式。在iptables 代理模式中,kube-proxy不在作为反向代理的在VIPs 和backend Pods之间进行负载均衡的分发。这个工作交给了在四层的iptables来实现。iptables 和netfilter紧密集成,密切合作,都在kernelspace 就实现了包的转发。
iptables 的负载均衡方式是随机和轮询
在这个模式下,kube-proxy 主要有这么几步来实现实现报文转发:
- 通过watching kubernetes集群 cluster API, 获取新建、删除Services或者Endpoint Pod指令。
- kube-proxy 在node上设置iptables规则,当有请求转发到Services的 ClusterIP上后,会立即被捕获,并重定向此Services对应的一个backend的Pod。
- kube-proxy会在node上为每一个Services对应的Pod设置iptables 规则,选择Pod默认算法是随机策略。
在iptables 中kube-proxy 只做好watching API 同步最新的数据信息这个角色。路由规则信息和转发都放在了kernelspace 的iptables 和netfiter 来做了。但是,这个这个模式不如userspace模式的一点是,在usersapce模式下,kube-proxy做了负载均衡,如果选择的backend 一台Pod没有响应,kube-proxy可以重试,在iptables模式下,就是一条条路由规则,要转发的backend Pod 没有响应,且没有被K8S 摘除,可能会导致转发到此Pod请求超时,需要配合K8S探针一起使用。
在这种模式下,kube-proxy通过观察Kubernetes中service和endpoint对象的变化,当有servcie创建时,kube-proxy在iptables中追加新的规则。对于service的每一个endpoint,会在iptables中追加一条规则,设定动作为DNAT,将目的地址设置成真正提供服务的pod地址;再为servcie追加规则,设定动作为跳转到对应的endpoint的规则上。
默认情况下,kube-proxy随机选择一个后端的服务,可以通过iptables中的 -m recent 模块实现session affinity功能,通过 -m statistic 模块实现负载均衡时的权重功能
执行过程
- 当请求访问service时,iptables在prerouting阶段,将讲求jump到KUBE-SERVICES,
- 在KUBE-SERVICES 中匹配到上面的第一条准则,继续jump到KUBE-SVC-XXXXXXXXXXXXXXXX,
- 根据这条准则jump到KUBE-SEP-XXXXXXXXXXXXXXXX,
- 在KUBE-SEP-XXXXXXXXXXXXXXXX规则中经过DNAT动做,访问真正的pod地址10.1.0.8:8080。
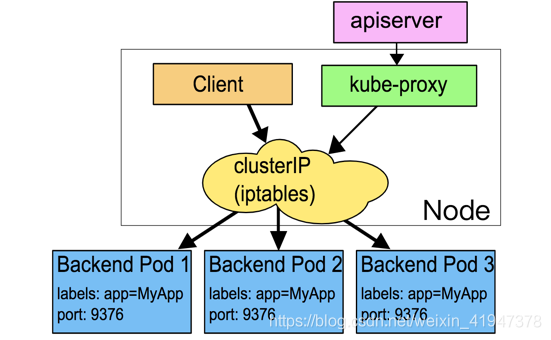
数据转发都在系统内核层面做,提升了性能,并且即便kube-proxy不工作了,已经创建好的服务还能正常工作 。但是在这种模式下,如果选中的第一个pod不能响应,请求就会失败,不能像userspace模式,请求失败后kube-proxy还能对其他endpoint进行重试。这就要求我们的应用(pod)要提供readiness probes功能,来验证后端服务是否能正常提供服务,kube-proxy只会将readiness probes测试通过的pod写入到iptables规则中,以此来避免将请求转发到不正常的后端服务中。
# 3. IPVS 模式
IPVS(IP虚拟服务器)实现传输层负载平衡,通常称为第4层LAN交换,是Linux内核的一部分。
IPVS在主机上运行,在真实服务器集群前充当负载均衡器。 IPVS可以将对基于TCP和UDP的服务的请求定向到真实服务器,并使真实服务器的服务在单个IP地址上显示为虚拟服务。
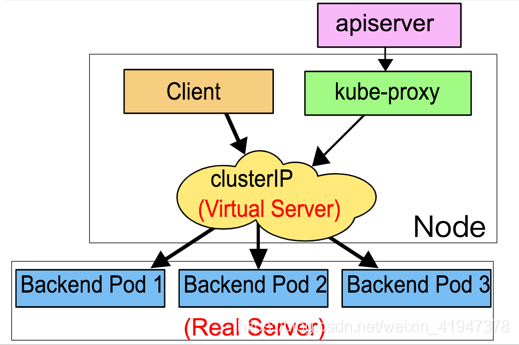
由于在iptables模式中,kube-proxy需要为每一个服务,每一个endpoint都生成相应的iptables规则,当服务规模很大时,性能也将显著下降,因此kubernetes在1.8引入了IPVS模式,1.9版本中变成beta,在1.11版本中成为GA。
在IPVS模式下,kube-proxy观察Kubernetes中service和endpoint对象的变化,通过调用netlink接口创建相应的IPVS规则,并周期性的对Kubernetes的service、endpoint和IPVS规则进行同步,当访问一个service时,IPVS负责选择一个真实的后端提供服务。
IPVS模式也是基于netfilter的hook功能(INPUT阶段),这点和iptables模式是一样的,但是用的是内核工作空间的hash表作为存储的数据结构,在这种模式下,iptables可通过ipset来验证具体请求是否满足某条规则。在service变更时,只用更新ipset中的记录,不用改变iptables的规则链,因此可以保证iptables中的规则不会随着服务的增加变多,在超大规模服务集群的情况下提供一致的性能效果。
负载步骤
- 通过watching kubernetes集群 cluster API, 获取新建、删除Services或者Endpoint Pod指令,有新的Service建立,kube-proxy回调网络接口,构建IPVS规则。
- 同时,kube-proxy会定期同步 Services和backend Pods的转发规则,确保失效的转发能被更新修复。
- 有请求转发到后端的集群时,IPVS的负载均衡直接转发到backend Pod。
IPVS在对后端服务的选择上也提供了更多灵活的算法:
- rr: round-robin(轮询算法)
- lc: least connection (最少连接数算法)
- dh: destination hashing(目的hash算法)
- sh: source hashing(原地址hash算法)
- sed: shortest expected delay(最短延迟算法)
- nq: never queue(无需队列等待算法)
iptables 和 ipvs的区别
- PVS为大型集群提供了更好的可扩展性和性能。
- IPVS支持比iptables更复杂的负载平衡算法(最小负载,最少连接,位置,加权等)。
- IPVS支持服务器健康检查和连接重试等。
# 总结
- K8s的Service网络构建于Pod网络之上的抽象层,它主要目的是解决服务发现(Service Discovery)和负载均衡(Load Balancing)问题。
- K8s通过一个ServiceName+ClusterIP统一屏蔽服务发现和负载均衡,底层技术是在DNS+Service Registry基础上发展演进出来。
- K8s的服务发现和负载均衡是在客户端通过Kube-Proxy + iptables转发实现,它对应用无侵入,且不穿透Proxy,没有额外性能损耗。
- K8s服务发现机制,可以认为是现代微服务发现机制和传统Linux内核机制的优雅结合。