 零拷贝技术
零拷贝技术
# 什么是零拷贝
零拷贝是指计算机执行IO操作时,CPU不需要将数据从一个存储区域复制到另一个存储区域,从而可以减少上下文切换以及CPU的拷贝时间。它是一种
I/O操作优化技术。
“拷贝”:就是指数据从一个存储区域转移到另一个存储区域。
“零” :表示次数为0,它表示拷贝数据的次数为0。
零拷贝就是不需要将数据从一个存储区域复制到另一个存储区域, 节省I/O
# 传统 IO 的执行流程
例如文件下载功能, 前端请求过来,服务端将服务端主机磁盘中的文件从已连接的socket发出去, 服务端的过程如下
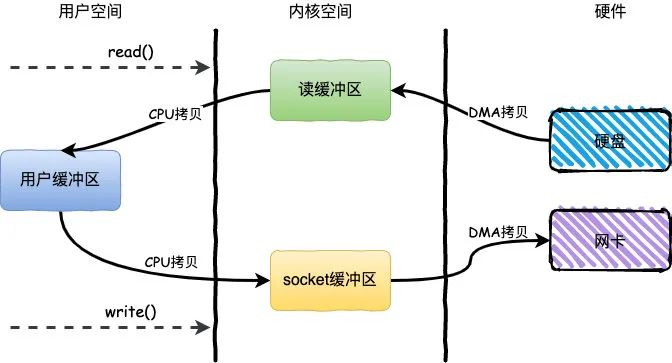
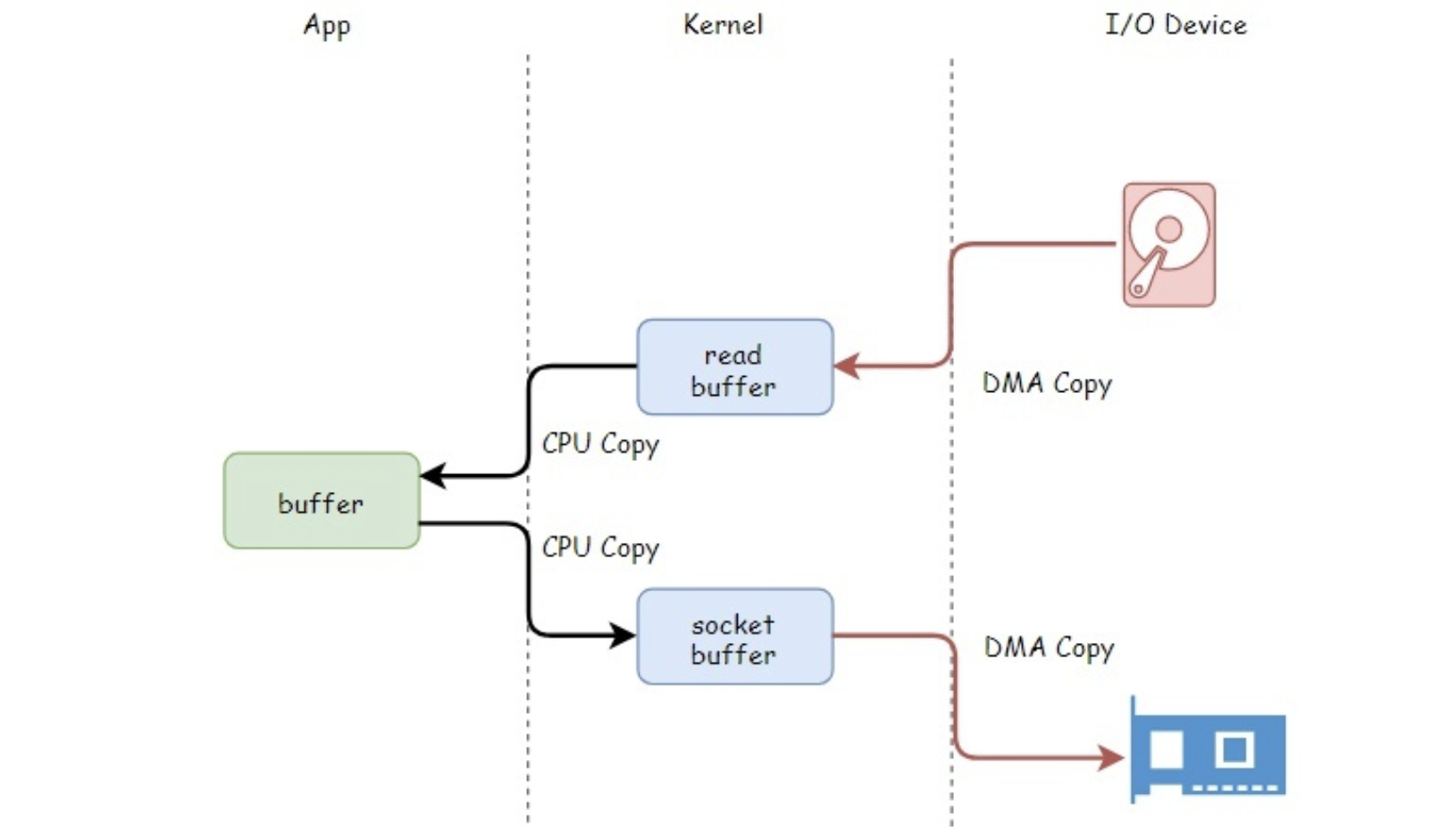
read:把数据从磁盘读取到内核缓冲区,再拷贝到用户缓冲区write:先把数据写入到socket缓冲区,最后写入网卡设备
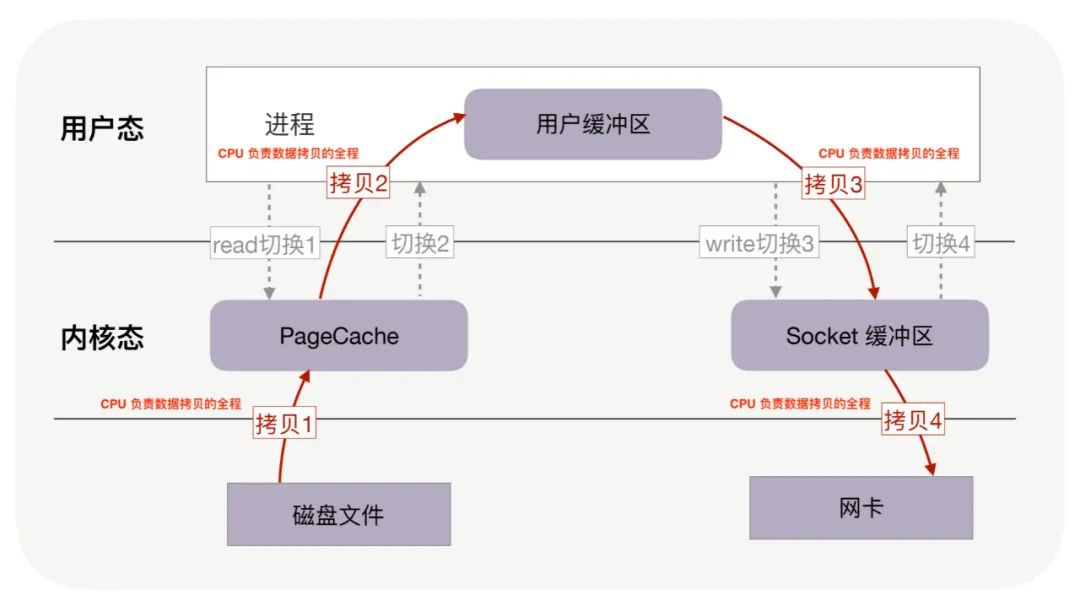
- 用户应用进程调用read函数,向操作系统发起IO调用,上下文从用户态转为内核态(切换1)
- DMA控制器把数据从磁盘中,读取到内核缓冲区。
- CPU把内核缓冲区数据,拷贝到用户应用缓冲区,上下文从内核态转为用户态(切换2),read函数返回
- 用户应用进程通过write函数,发起IO调用,上下文从用户态转为内核态(切换3)
- CPU将用户缓冲区中的数据,拷贝到socket缓冲区
- DMA控制器把数据从socket缓冲区,拷贝到网卡设备,上下文从内核态切换回用户态(切换4),write函数返回
测过程发生了什么呢?
4 次 copy:
- CPU 负责将数据从磁盘搬运到内核空间的 Page Cache 中;
- CPU 负责将数据从内核空间的 Socket 缓冲区搬运到的网络中;
- CPU 负责将数据从内核空间的 Page Cache 搬运到用户空间的缓冲区;
- CPU 负责将数据从用户空间的缓冲区搬运到内核空间的 Socket 缓冲区中;
4 次上下文切换:
read 系统调用时:用户态切换到内核态;
read 系统调用完毕:内核态切换回用户态;
write 系统调用时:用户态切换到内核态;
write 系统调用完毕:内核态切换回用户态;
# DMA
DMA,英文全称是Direct Memory Access,即直接内存访问。DMA本质上是一块主板上独立的芯片,允许外设设备和内存存储器之间直接进行IO数据传输,其过程不需要CPU的参与, 而直接通过 DMA 控制器(DMA Controller,简称 DMAC)。这块芯片,我们可以认为它其实就是一个协处理器(Co-Processor)。
DMAC 最有价值的地方体现在,当我们要传输的数据特别大、速度特别快,或者传输的数据特别小、速度特别慢的时候。
比如说,我们用千兆网卡或者硬盘传输大量数据的时候,如果都用 CPU 来搬运的话,肯定忙不过来,所以可以选择 DMAC。而当数据传输很慢的时候,DMAC 可以等数据到齐了,再发送信号,给到 CPU 去处理,而不是让 CPU 在那里忙等待。
注意,这里面的“协”字。DMAC 是在“协助”CPU,完成对应的数据传输工作。在 DMAC 控制数据传输的过程中,我们还是需要 CPU 的进行控制,但是具体数据的拷贝不再由 CPU 来完成。
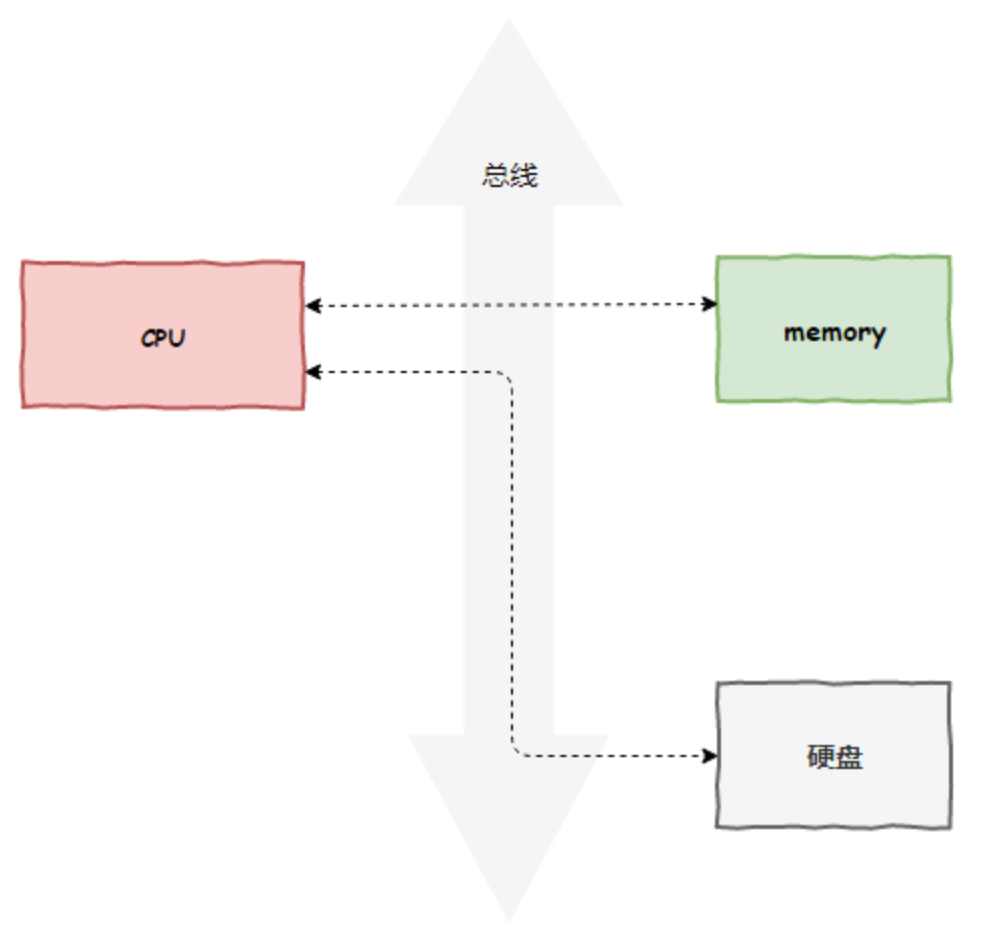
DMA未参与, 计算机所有组件之间的数据拷贝(流动)必须经过 CPU
DMA 代替了 CPU 负责内存与磁盘以及内存与网卡之间的数据搬运,CPU 作为 DMA 的控制者
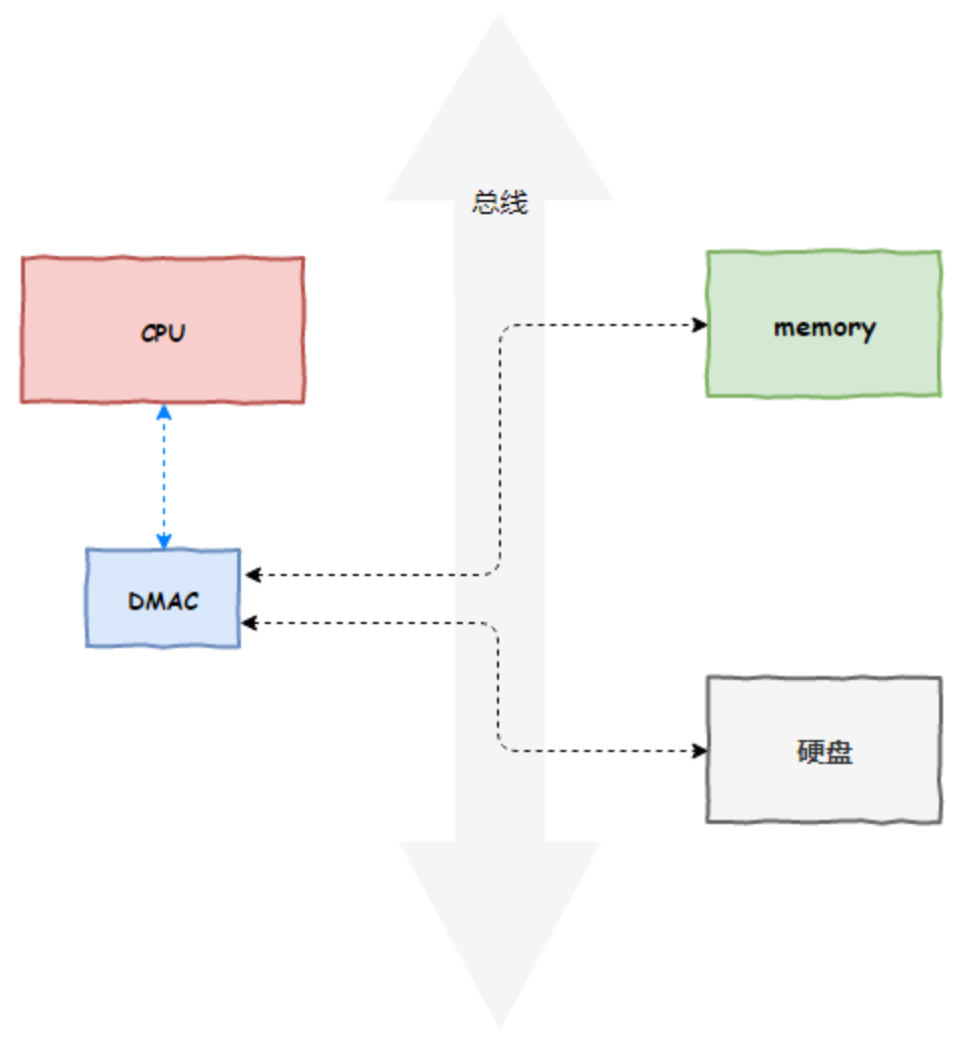
DMA 有其局限性,DMA 仅仅能用于设备之间交换数据时进行数据拷贝,但是设备内部的数据拷贝还需要 CPU 进行,例如 CPU 需要负责内核空间数据与用户空间数据之间的拷贝(内存内部的拷贝)
# 零拷贝技术
零拷贝的特点是 CPU 不全程负责内存中的数据写入其他组件,CPU 仅仅起到管理的作用。但注意,零拷贝不是不进行拷贝,而是 CPU 不再全程负责数据拷贝时的搬运工作。如果数据本身不在内存中,那么必须先通过某种方式拷贝到内存中(这个过程 CPU 可以不参与),因为数据只有在内存中,才能被转移,才能被 CPU 直接读取计算。
实现方式
- sendfile
- mmap
- splice
- 直接 Direct I/O
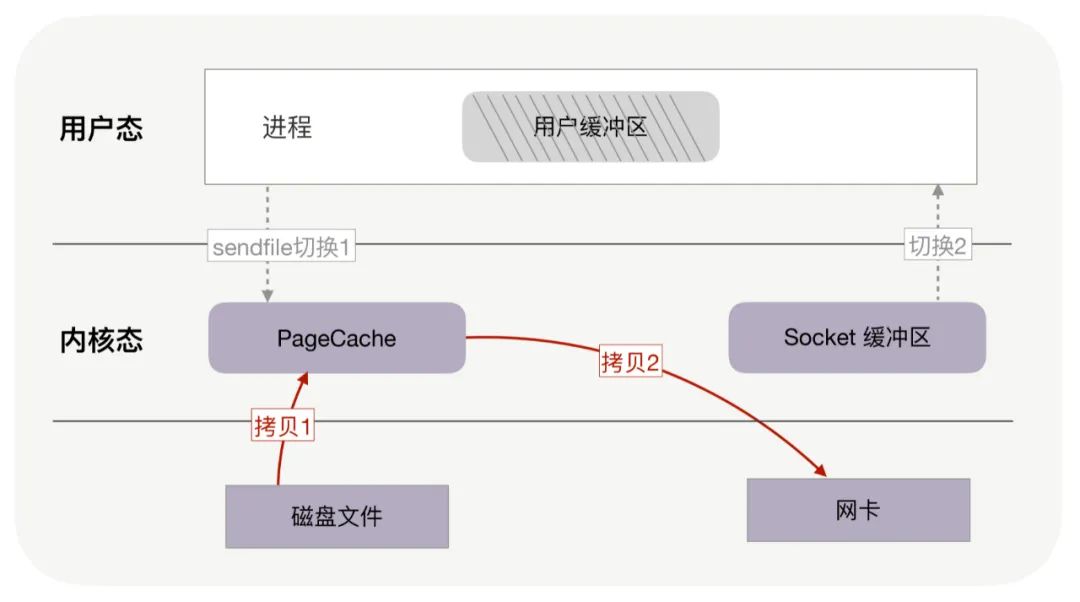
# 1. sendfile !!!
snedfile 的应用场景是:用户从磁盘读取一些文件数据后不需要经过任何计算与处理就通过网络传输出去。此场景的典型应用是消息队列。
sendfile 主要使用到了两个技术:
DMA 技术;
传递文件描述符代替数据拷贝;
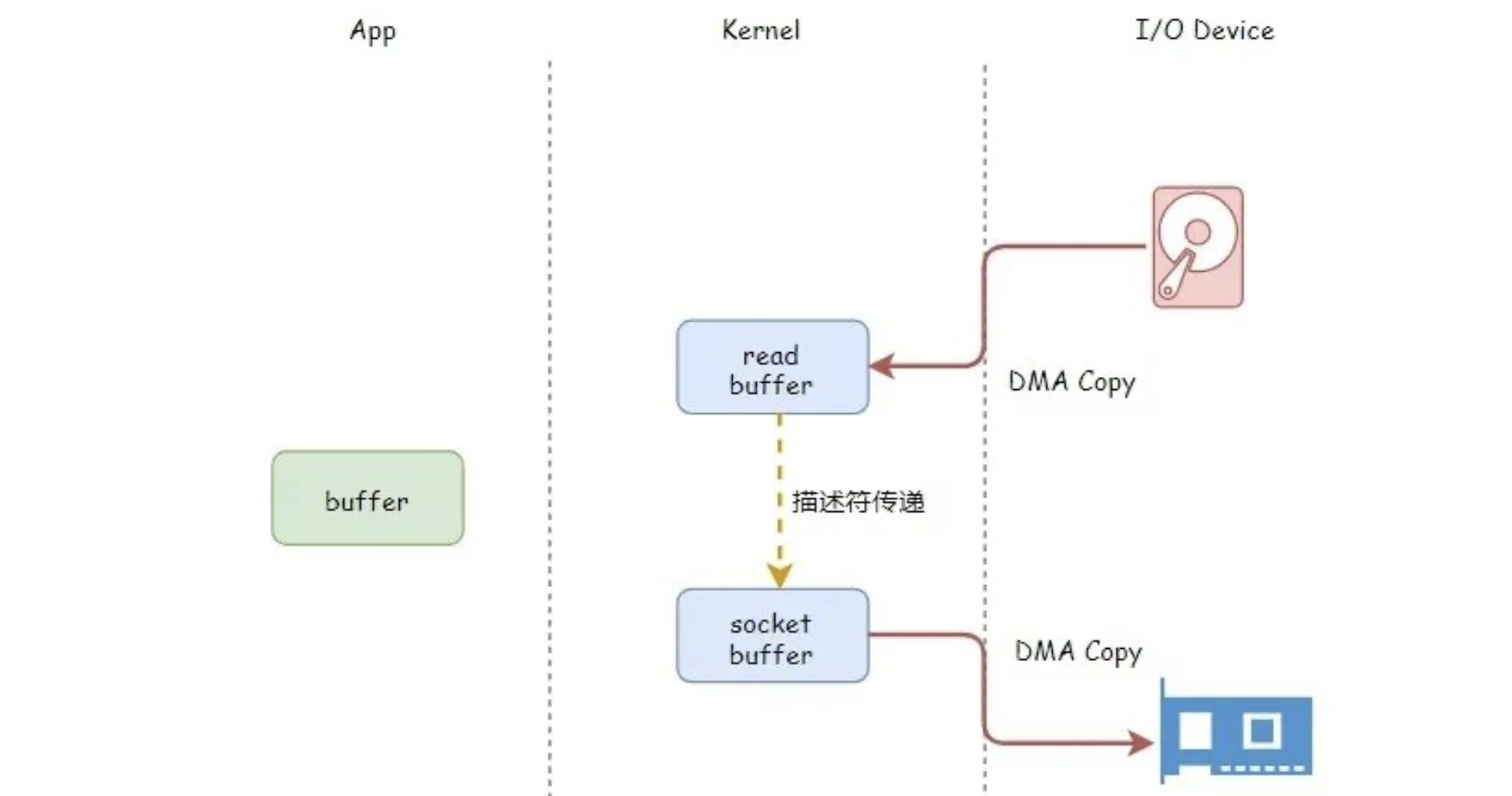
sendfile 仅仅对应一次系统调用,而传统文件操作则需要使用 read 以及 write 两个系统调用。
sendfile 能够将用户态与内核态之间的上下文切换从 4 次讲到 2 次
# 2. mmap !!!
mmap+write简单来说就是使用 mmap 替换了 read+write 中的 read 操作,减少了一次 CPU 的拷贝mmap 主要实现方式是将读缓冲区的地址和用户缓冲区的地址进行映射,内核缓冲区和应用缓冲区共享,从而减少了从读缓冲区到用户缓冲区的一次CPU拷贝。
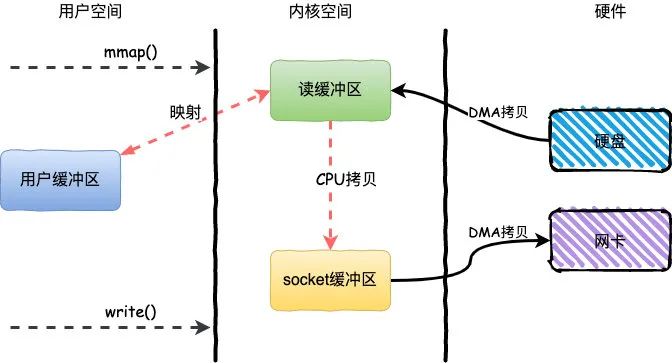
整个过程发生了 4 次用户态和内核态的上下文切换和 3 次拷贝,具体流程如下:
- 用户进程通过 mmap() 方法向操作系统发起调用,上下文从用户态转向内核态;
- DMA 控制器把数据从硬盘中拷贝到读缓冲区;
- 上下文从内核态转为用户态,mmap 调用返回;
- 用户进程通过 write() 方法发起调用,上下文从用户态转为内核态;
- CPU 将读缓冲区中数据拷贝到 socket 缓冲区;
- DMA 控制器把数据从 socket 缓冲区拷贝到网卡,上下文从内核态切换回用户态,write() 返回。
mmap 的方式节省了一次 CPU 拷贝,同时由于用户进程中的内存是虚拟的,只是映射到内核的读缓冲区,所以可以节省一半的内存空间,比较适合大文件的传输。
# 3. splice
- ...
# 4. Direct I/O
Direct I/O 即直接 I/O。其名字中的”直接”二字用于区分使用 page cache 机制的缓存 I/O。
缓存文件 I/O:用户空间要读写一个文件并不直接与磁盘交互,而是中间夹了一层缓存,即 page cache;
直接文件 I/O:用户空间读取的文件直接与磁盘交互,没有中间 page cache 层;
“直接”在这里还有另一层语义:其他所有技术中,数据至少需要在内核空间存储一份,但是在 Direct I/O 技术中,数据直接存储在用户空间中,绕过了内核。此时用户空间直接通过 DMA 的方式与磁盘以及网卡进行数据拷贝。
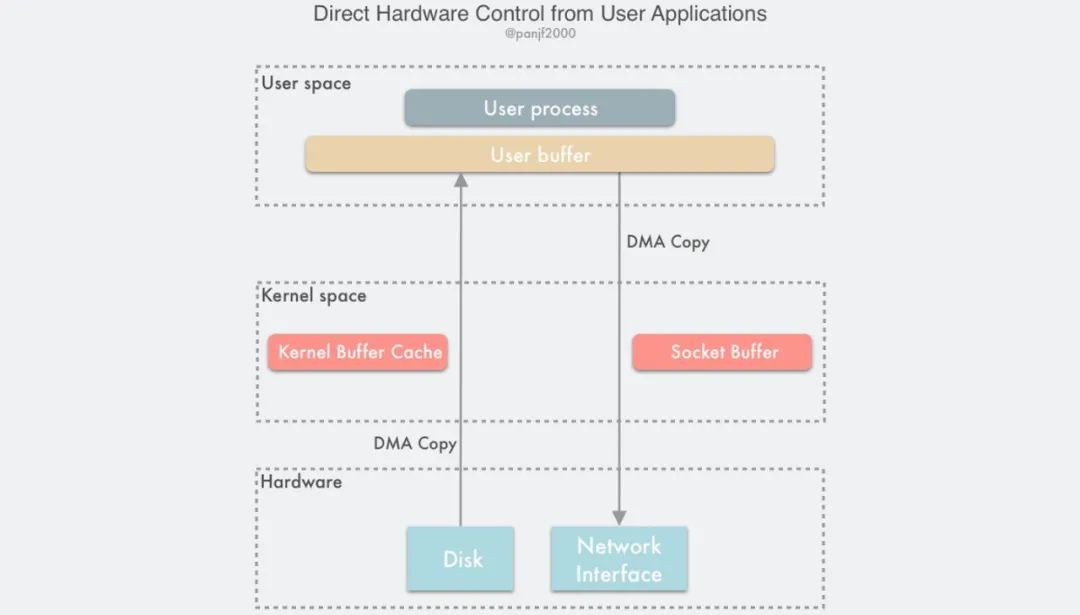
Direct I/O 的读写非常有特点:
- Write 操作:由于其不使用 page cache,所以其进行写文件,如果返回成功,数据就真的落盘了(不考虑磁盘自带的缓存);
- Read 操作:由于其不使用 page cache,每次读操作是真的从磁盘中读取,不会从文件系统的缓存中读取。
# kafka零拷贝技术
Kafka 作为一个消息队列,涉及到磁盘 I/O 主要有两个操作:
Provider 向 Kakfa 发送消息,Kakfa 负责将消息以日志的方式持久化落盘;
Consumer 向 Kakfa 进行拉取消息,Kafka 负责从磁盘中读取一批日志消息,然后再通过网卡发送;
Kakfa 服务端接收 Provider 的消息并持久化的场景下使用 mmap 机制,能够基于顺序磁盘 I/O 提供高效的持久化能力,使用的 Java 类为 java.nio.MappedByteBuffer。
Kakfa 服务端向 Consumer 发送消息的场景下使用 sendfile 机制,这种机制主要两个好处:
sendfile 避免了内核空间到用户空间的 CPU 全程负责的数据移动;
sendfile 基于 Page Cache 实现,因此如果有多个 Consumer 在同时消费一个主题的消息,那么由于消息一直在 page cache 中进行了缓存,因此只需一次磁盘 I/O,就可以服务于多个 Consumer;