 布隆过滤器与缓存穿透
布隆过滤器与缓存穿透
# 概念
- 布隆过滤器(BloomFilter)是由一个叫“布隆”的小伙子在1970年提出的,它是一个很长的二进制向量,主要用于判断一个元素是否在一个集合中。
# 原理
哈希函数有以下特点:
- 如果根据同一个哈希函数得到的哈希值不同,那么这两个哈希值的原始输入值肯定不同。
- 如果根据同一个哈希函数得到的两个哈希值相等,两个哈希值的原始输入值有可能相等,有可能不相等。
布隆过滤器是由一个很长的二进制向量和一系列的哈希函数组成。那么布隆过滤器是怎么判断一个元素是否在一个集合中的呢?假设布隆过滤器的底层存储结构是一个长度为16的位数组,初始状态时,它的所有位置都设置为0。

当有变量添加到布隆过滤器中,通过K个映射函数将变量映射到位数组的K个点,并把这K个点的值设置为1(假设有三个映射函数)。

查询某个变量是否存在的时候,我们只需要通过同样的K个映射函数,找到对应的K个点,判断K个点上的值是否全都是1,如果全都是1则表示很可能存在,如果K个点上有任何一个是0则表示一定不存在。
# 特点
第一个问题,为什么说全都是1的情况是很可能存在,而不是一定存在呢?
还记得前面说的哈希函数的特点,根据同一个哈希函数得到相同的哈希值,输入值不一定相等。类似于Java中两个对象的hashcode相等,但是不一定相等的道理。说白了,映射函数得到位数组上映射点全都是1,不一定是要查询的这个变量之前存进来时设置的,也有可能是其他变量映射的点。
所以这里引出了布隆过滤器的其中一个特点,存在一定的误判。
第二个问题,布隆过滤器能不能删除元素呢?(不能删除布隆过滤器里的元素)
答案是不能的。因为在位数组上的同一个点有可能有多个输入值映射,如果删除了会影响布隆过滤器里其他元素的判断结果。

如上图,如果删除obj1,把4,7,15置为0,那么判断obj2是否存在时就会导致因为映射点7是0,结果判断obj2是不存在的,结果出错。
# 优缺点
# 1. 优点:
- 在空间和时间方面,都有着巨大的优势。因为不是存完整的数据,是一个二进制向量,能节省大量的内存空间,时间复杂度方面,是根据映射函数查询,假设有K个映射函数,那么时间复杂度就是O(K)。
- 因为存的不是元素本身,而是二进制向量,所以在一些对保密性要求严格的场景有一定优势。
# 2. 缺点:
- **存在一定的误判。**存进布隆过滤器里的元素越多,误判率越高。
- **不能删除布隆过滤器里的元素。**随着使用的时间越来越长,因为不能删除,存进里面的元素越来越多,占用内存越来越多,误判率越来越高,最后不得不重置。
# 应用与缓存穿透
**用于缓解缓存穿透。**缓存穿透的问题主要是因为传进来的key在Redis中是不存在的,那么就会直接打在DB上,造成DB压力增大。
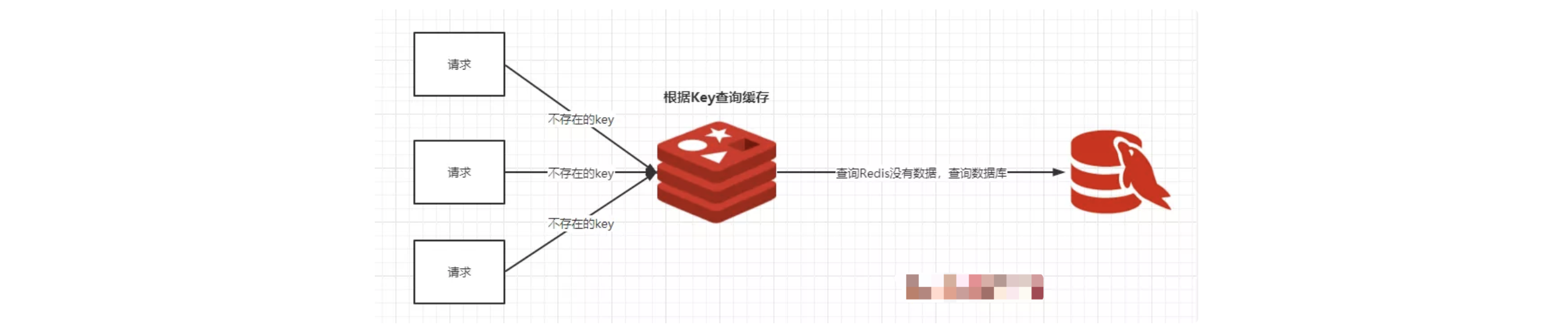
针对这种情况,可以在Redis前加上布隆过滤器,预先把数据库中的数据加入到布隆过滤器中,因为布隆过滤器的底层数据结构是一个二进制向量,所以占用的空间并不是很大。在查询Redis之前先通过布隆过滤器判断是否存在,如果不存在就直接返回,如果存在的话,按照原来的流程还是查询Redis,Redis不存在则查询DB。
这里主要利用的是布隆过滤器判断结果是不存在的话就一定不存在这一个特点,但是由于布隆过滤器有一定的误判,所以并不能说完全解决缓存穿透,但是能很大程度缓解缓存穿透的问题。
