 redis高并发和高可用
redis高并发和高可用
# 主从和集群的区别
# 1. 主从
- 通过持久化功能,Redis保证了即使在服务器重启的情况下也不会损失(或少量损失)数据,因为持久化会把内存中数据保存到硬盘上,重启会从硬盘上加载数据。 。但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。
- 为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务。为此, Redis 提供了复制(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
- 在复制的概念中,数据库分为两类,一类是主数据库(master),另一类是从数据库(slave)。主数据库可以进行读写操作,当写操作导致数据变化时会自动将数据同步给从数据库。而从数据库一般是只读的,并接受主数据库同步过来的数据。一个主数据库可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库。
# 2. 集群
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。 Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
- 集群是一组相互独立的、通过高速网络互联的计算机,它们构成了一个组,并以单一系统的模式加以管理。一个客户与集群相互作用时,集群像是一个独立的服务器。集群配置是用于提高可用性和可缩放性。 当请求到来首先由负载均衡服务器处理,把请求转发到另外的一台服务器上。
# 3. 总结
- 主从服务器分工明确,主服务器用来写,从服务器用来读,一个主服务器,多个从服务器;集群就好比,多个主从服务器,子,比如:全国有多个主从服务器,分别处理各自区域的信息,这样可以减少单个主从服务器中主服务器的压力。
- 例如mysql: 对于mysql来说,按实例区分,1主1从(主读写从只读),或1主2从(主读写一备只读二备延时冷备),组成的整体一般视为一个节点,大于等于2个节点开始,视为一个集群。严格来说,1主2从的方式才算合理的完整节点,发生故障的时候主从可以切换,还有一个冷备是做延时同步,保证大部分数据冗余不会完全丢失。
# redis高并发
- 主从架构,一主多从,一般来说,很多项目其实就足够了,单主用来写入数据,单机几万QPS,多从用来查询数据,多个从实例可以提供每秒10万的QPS。
- redis高并发的同时,还需要容纳大量的数据:一主多从,每个实例都容纳了完整的数据,比如redis主就10G的内存量,其实你就最对只能容纳10g的数据量。如果你的缓存要容纳的数据量很大,达到了几十g,甚至几百g,或者是几t,那你就需要redis集群,而且用redis集群之后,可以提供可能每秒几十万的读写并发。
# 1. redis高并发与整个系统高并发的关系
redis,你要搞高并发的话,不可避免,要把底层的缓存搞得很好
mysql,高并发,做到了,那么也是通过一系列复杂的分库分表,订单系统,事务要求的,QPS到几万,比较高了
要做一些电商的商品详情页,真正的超高并发,QPS上十万,甚至是百万,一秒钟百万的请求量
光是redis是不够的,但是redis是整个大型的缓存架构中,支撑高并发的架构里面,非常重要的一个环节
- 首先,你的底层的缓存中间件,缓存系统,必须能够支撑的起我们说的那种高并发
- 其次,再经过良好的整体的缓存架构的设计(多级缓存架构、热点缓存),支撑真正的上十万,甚至上百万的高并发
# 2. redis高并发的瓶颈
单机redis ,QPS只能在上万左右,成为了支撑高并发的瓶颈。
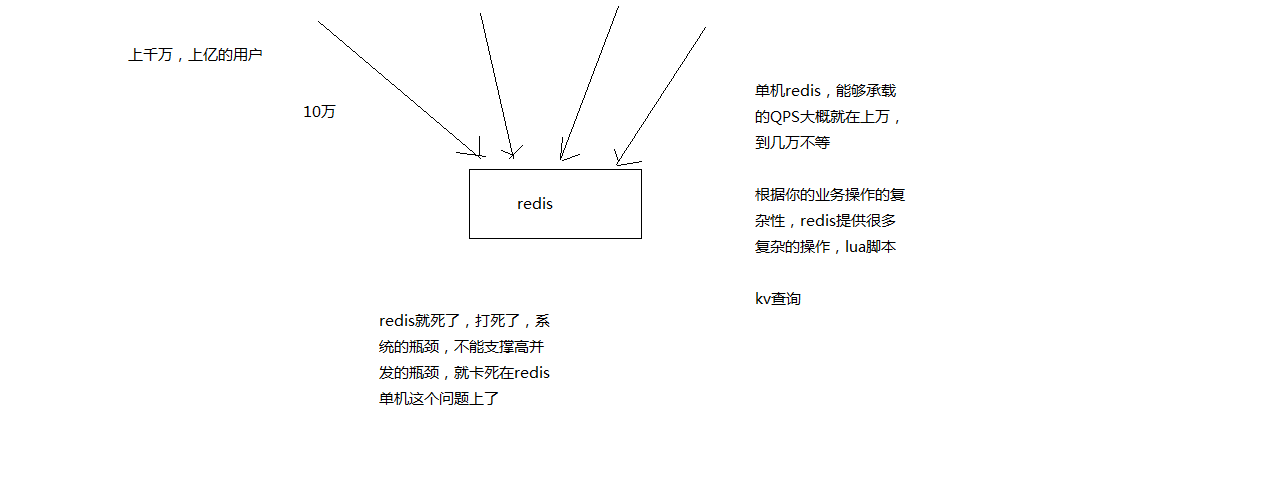
# 3. 高并发方案
如果redis要支撑超过10万+的并发,那应该怎么做?
读写分离(主从架构): 一般来说,对缓存,一般都是用来支撑读高并发的,写的请求是比较少的,可能写请求也就一秒钟几千,一两千。大量的请求都是读,一秒钟二十万次读
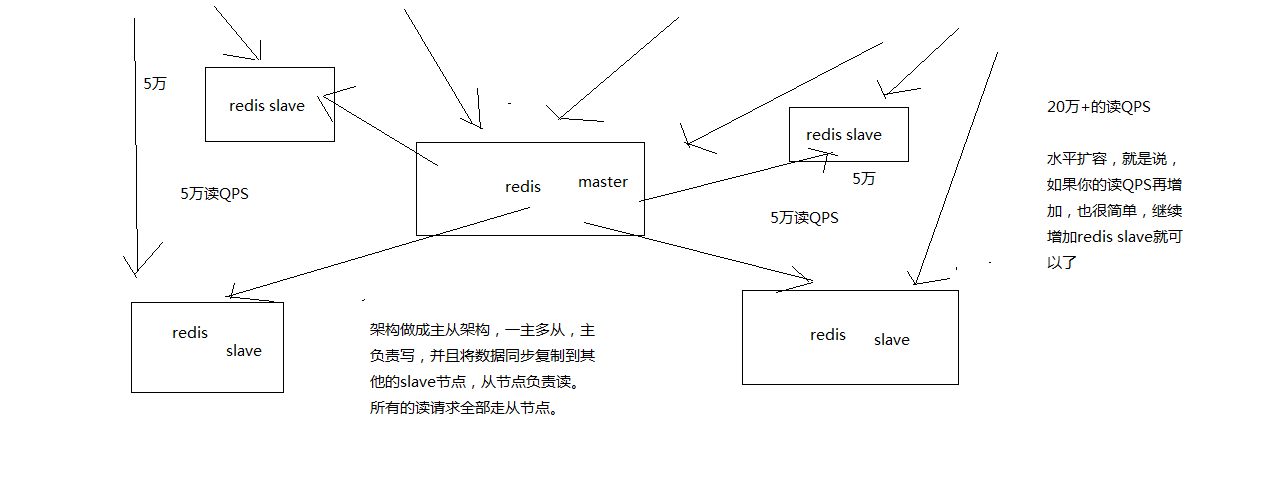
集群架构: 效果为数十万 QPS
# redis高可用
- 如果你做主从架构部署,其实就是加上哨兵就可以了,就可以实现,任何一个实例宕机,自动会进行主备切换。
- 也可以是集群模式
- Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
- Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
上次更新: 2023/04/16, 18:35:33