 Go面向对象的思维理解interface
Go面向对象的思维理解interface
# 一. interface
- interface 是方法声明的集合
- 任何类型的对象实现了在interface 接口中声明的全部方法,则表明该类型实现了该接口。
- interface 可以作为一种数据类型,实现了该接口的任何对象都可以给对应的接口类型变量赋值。
- interface 可以被任意对象实现,一个类型/对象也可以实现多个 interface
- 方法不能重载,如
eat(), eat(s string)不能同时存在
接口(interface)定义了一个对象的行为规范,只定义规范不实现,由具体的对象来实现规范的细节。
牢记接口(interface)是一种类型。
接口类型是一种抽象的类型, 不会暴露出他所代表的内部属性的结构, 只会展示出他自己的方法,因此接口不能被实例化;
**Golang中的接口没有数据字段, 只有定义的方法;**接口是方法的集合
接口命名规范:
- 单个函数的接口名以"er"作为后缀, 接口的实现则去掉"er"
- 两个函数的接口名综合两个函数名, 以"er"作为后缀, 接口的实现则去掉"er"
- 三个以上函数以上的接口名, 抽象这个接口的功能, 类似于结构体命名;
结构体嵌入接口值,结构体初始化后可以返回嵌入的接口值类型
# 二. 面向对象原则
- 面向对象尽量遵从一下原则
开闭原则: 面向扩展开放, 面向修改关闭. 简单的说就是在修改需求的时候,应该尽量通过扩展来实现变化,而不是通过修改已有代码来实现变化。
依赖倒转原则: 抽象层暴露出来的接口就是我们业务层可以使用的方法,然后可以通过多态的线下,接口指针指向哪个实现模块,调用了就是具体的实现方法; 依赖倒置原则的核心就是要我们面向接口编程,理解了面向接口编程,也就理解了依赖倒置。低层模块尽量都要有抽象类或接口,或者两者都有。变量的声明类型尽量是抽象类或接口。
单一原则: 单一职责,从字面意思其实就很好理解,只做一件事,不去多揽其他的事使自己烦心;单一职责原则可以看做是低耦合高内聚思想的延伸,提高高内聚来减少引起变化的原因。
里氏替换原则: 里氏替换原则对继承进行了规则上的约束,这种约束主要体现在四个方面:
\1. 子类必须实现父类的抽象方法,但不得重写(覆盖)父类的非抽象(已实现)方法。
\2. 子类中可以增加自己特有的方法。
\3. 当子类覆盖或实现父类的方法时,方法的前置条件(即方法的形参)要比父类方法的输入参数更宽松。
\4. 当子类的方法实现父类的抽象方法时,方法的后置条件(即方法的返回值)要比父类更严格。
就是要求继承是严格的is-a关系。所有引用基类的地方必须能透明地使用其子类的对象。在软件中将一个基类对象替换成它的子类对象,程序将不会产生任何错误和异常,反过来则不成立,如果一个软件实体使用的是一个子类对象的话,那么它不一定能够使用基类对象。例如:我喜欢动物,那我一定喜欢狗,因为狗是动物的子类;但是我喜欢狗,不能据此断定我喜欢动物,因为我并不喜欢老鼠,虽然它也是动物。
接口隔离原则: 接口端不应该依赖它不需要的接口,一个类对另一个类的依赖应该建立在最小的接口上。一个类对另一个类的依赖应该建立在最小的接口上,通俗的讲就是需要什么就提供什么,不需要的就不要提供。接口中的方法应该尽量少,不要使接口过于臃肿,不要有很多不相关的逻辑方法。
# 三. 面向对象中的开闭原则
开闭原则: 一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。
简单的说就是在修改需求的时候,应该尽量通过扩展来实现变化,而不是通过修改已有代码来实现变化。
# 1. 平铺式的模块设计 (垃圾)
那么作为
interface数据类型,他存在的意义在哪呢? 实际上是为了满足一些面向对象的编程思想。我们知道,软件设计的最高目标就是
高内聚,低耦合。那么其中有一个设计原则叫开闭原则。什么是开闭原则呢,接下来我们看一个例子:- 一个银行业务员,他可能拥有很多的业务,比如
Save()存款、Transfer()转账、Pay()支付等。那么如果这个业务员模块只有这几个方法还好,但是随着我们的程序写的越来越复杂,银行业务员可能就要增加方法,会导致业务员模块越来越臃肿。
package main import "fmt" //我们要写一个类,Banker银行业务员 type Banker struct { } //存款业务 func (this *Banker) Save() { fmt.Println( "进行了 存款业务...") } //转账业务 func (this *Banker) Transfer() { fmt.Println( "进行了 转账业务...") } //支付业务 func (this *Banker) Pay() { fmt.Println( "进行了 支付业务...") } func main() { banker := &Banker{} banker.Save() banker.Transfer() banker.Pay() }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30- 一个银行业务员,他可能拥有很多的业务,比如
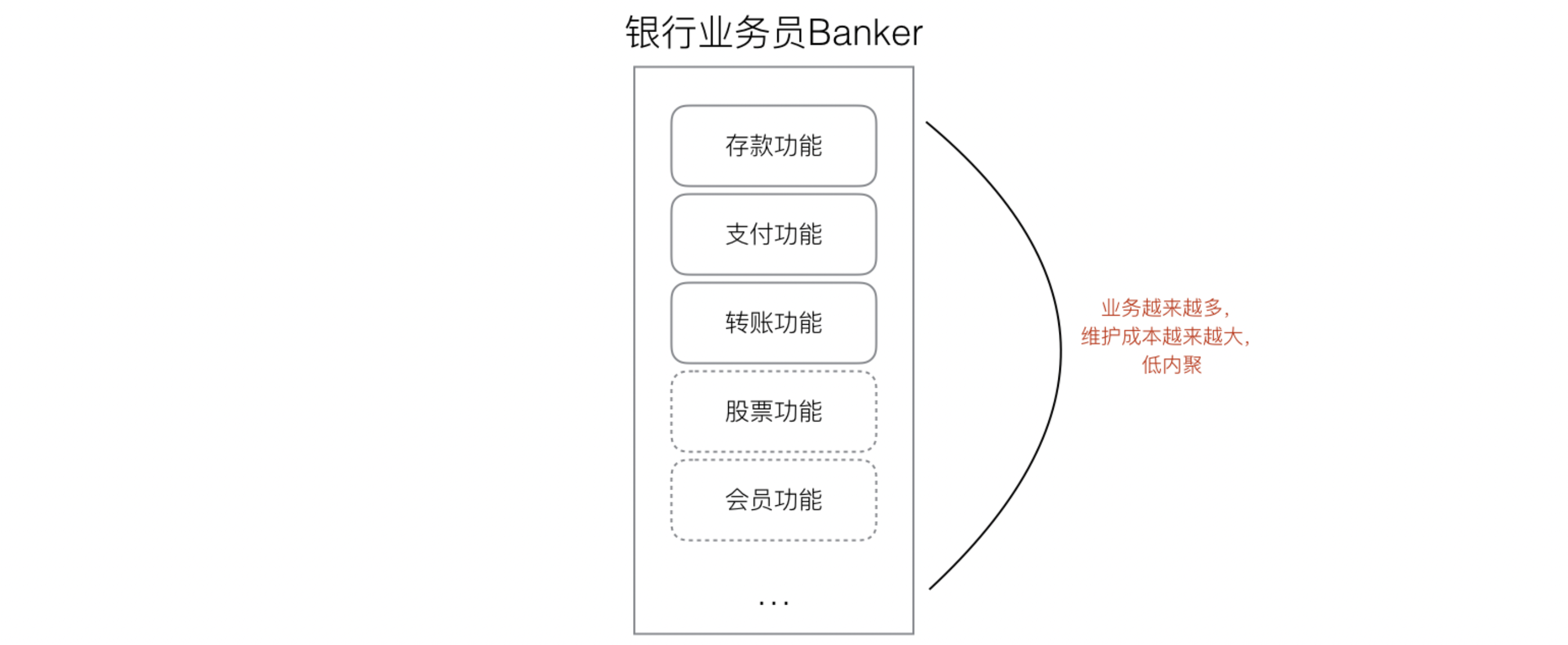
- 这样的设计会导致,当我们去给Banker添加新的业务的时候,会直接修改原有的Banker代码,那么Banker模块的功能会越来越多,出现问题的几率也就越来越大,假如此时Banker已经有99个业务了,现在我们要添加第100个业务,可能由于一次的不小心,导致之前99个业务也一起崩溃,因为所有的业务都在一个Banker类里,他们的耦合度太高,Banker的职责也不够单一,代码的维护成本随着业务的复杂正比成倍增大。
# 2. 开闭原则设计 (优化)
开闭原则: 设计代码时应该对功能扩展开放, 对修改功能关闭;
简单的说就是在修改需求的时候,应该尽量通过扩展来实现变化,而不是通过修改已有代码来实现变化。
如果我们拥有接口,
interface这个东西,那么我们就可以抽象一层出来,制作一个抽象的Banker模块,然后提供一个抽象的方法。 分别根据这个抽象模块,去实现支付Banker(实现支付方法),转账Banker(实现转账方法)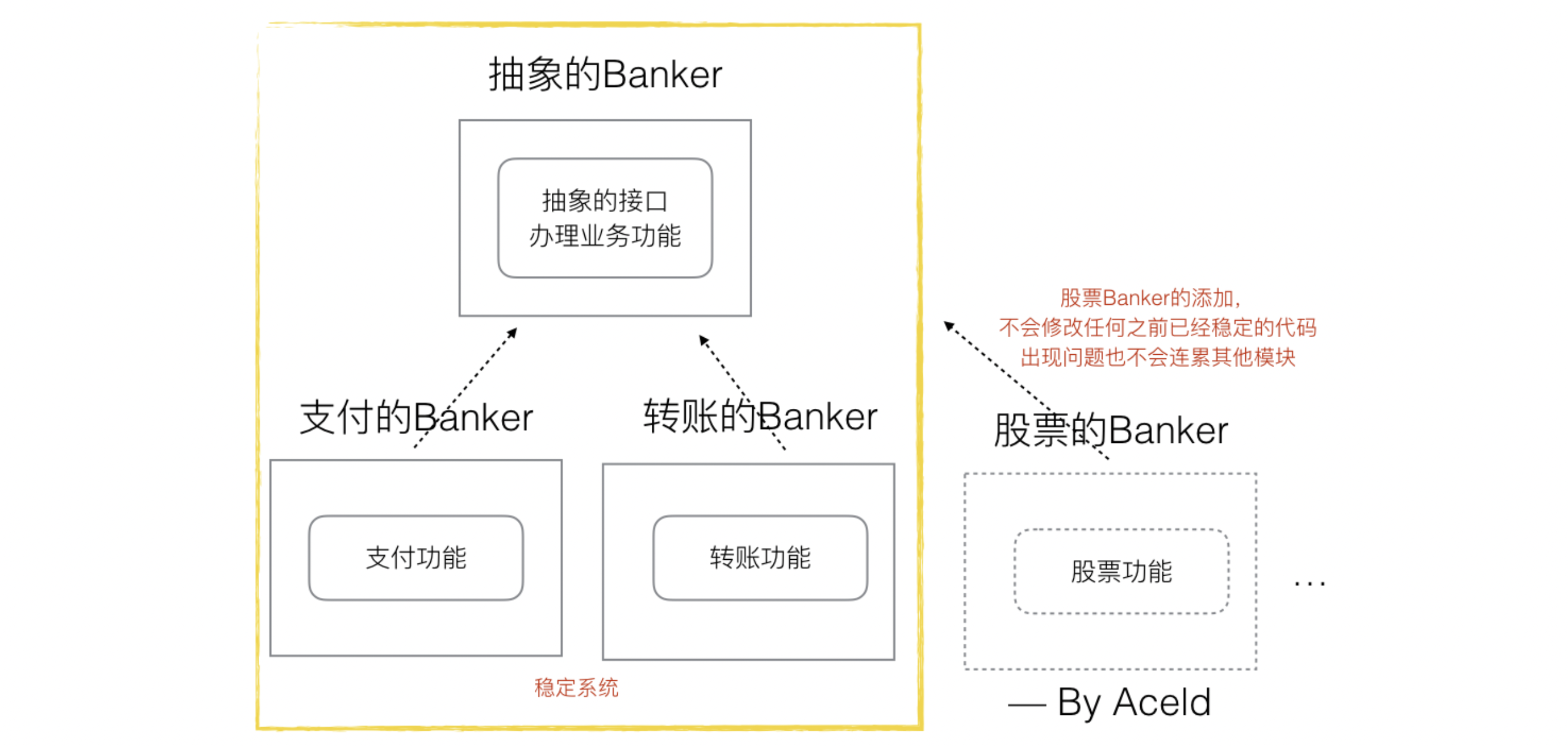
开闭原则设计代码
package main import "fmt" //抽象的银行业务员 type AbstractBanker interface{ DoBusi() //抽象的处理业务接口 } //存款的业务员 type SaveBanker struct { //AbstractBanker } func (sb *SaveBanker) DoBusi() { fmt.Println("进行了存款") } //转账的业务员 type TransferBanker struct { //AbstractBanker } func (tb *TransferBanker) DoBusi() { fmt.Println("进行了转账") } //支付的业务员 type PayBanker struct { //AbstractBanker } func (pb *PayBanker) DoBusi() { fmt.Println("进行了支付") } func main() { //进行存款 sb := &SaveBanker{} sb.DoBusi() //进行转账 tb := &TransferBanker{} tb.DoBusi() //进行支付 pb := &PayBanker{} pb.DoBusi() }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51当然我们也可以根据
AbstractBanker设计一个小框架//实现架构层(基于抽象层进行业务封装-针对interface接口进行封装) func BankerBusiness(banker AbstractBanker) { //通过接口来向下调用,(多态现象) banker.DoBusi() }1
2
3
4
5那么main中可以如下实现业务调用:
func main() { //进行存款 BankerBusiness(&SaveBanker{}) //进行存款 BankerBusiness(&TransferBanker{}) //进行存款 BankerBusiness(&PayBanker{}) }1
2
3
4
5
6
7
8
9
10
# 四. 面向对象中的依赖倒转原则
# 1. 耦合度极高的模块关系设计
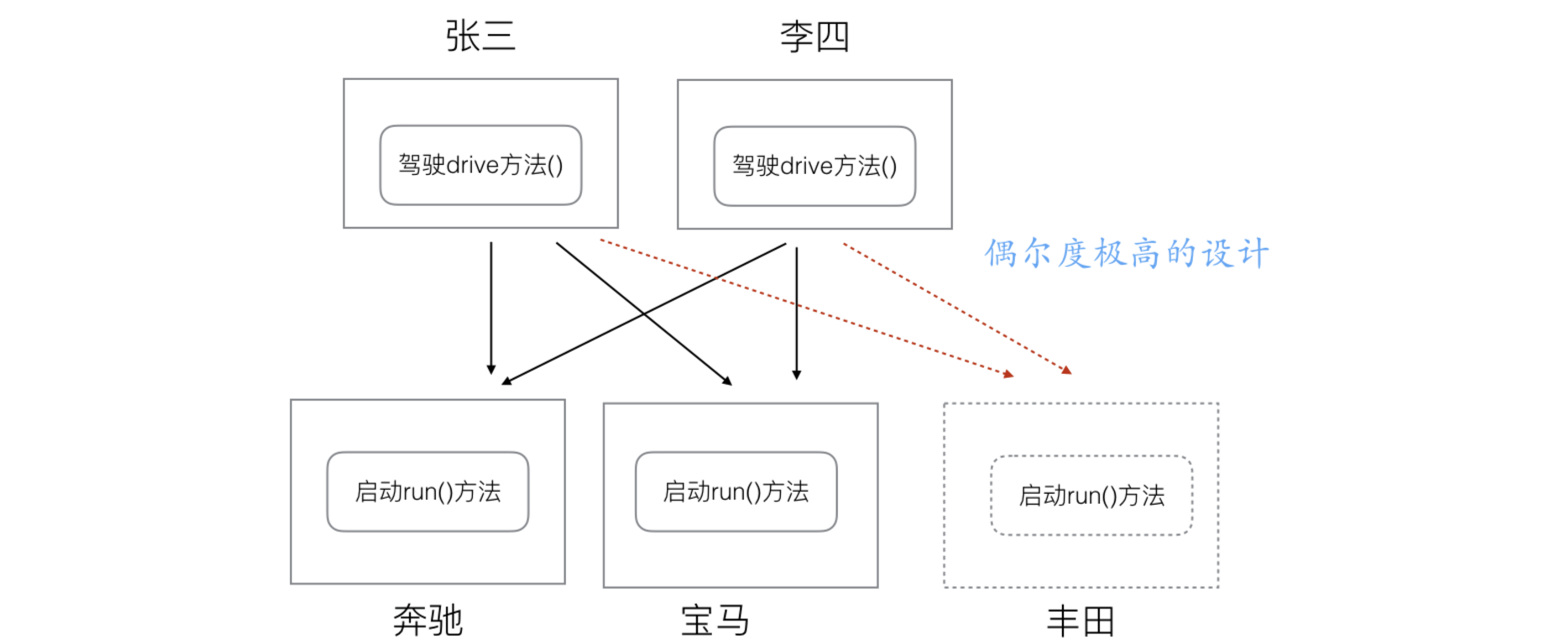
package main
import "fmt"
// === > 奔驰汽车 <===
type Benz struct {
}
func (this *Benz) Run() {
fmt.Println("Benz is running...")
}
// === > 宝马汽车 <===
type BMW struct {
}
func (this *BMW) Run() {
fmt.Println("BMW is running ...")
}
//===> 司机张三 <===
type Zhang3 struct {
//...
}
func (zhang3 *Zhang3) DriveBenZ(benz *Benz) {
fmt.Println("zhang3 Drive Benz")
benz.Run()
}
func (zhang3 *Zhang3) DriveBMW(bmw *BMW) {
fmt.Println("zhang3 drive BMW")
bmw.Run()
}
//===> 司机李四 <===
type Li4 struct {
//...
}
func (li4 *Li4) DriveBenZ(benz *Benz) {
fmt.Println("li4 Drive Benz")
benz.Run()
}
func (li4 *Li4) DriveBMW(bmw *BMW) {
fmt.Println("li4 drive BMW")
bmw.Run()
}
func main() {
//业务1 张3开奔驰
benz := &Benz{}
zhang3 := &Zhang3{}
zhang3.DriveBenZ(benz)
//业务2 李四开宝马
bmw := &BMW{}
li4 := &Li4{}
li4.DriveBMW(bmw)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
# 2. 面向抽象层依赖倒转
- 抽象层依赖倒转原则: 在指定业务逻辑也是一样,只需要参考抽象层的接口来业务就好了,抽象层暴露出来的接口就是我们业务层可以使用的方法,然后可以通过多态的线下,接口指针指向哪个实现模块,调用了就是具体的实现方法,这样我们业务逻辑层也是依赖抽象成编程。我们就将这种的设计原则叫做
依赖倒转原则。
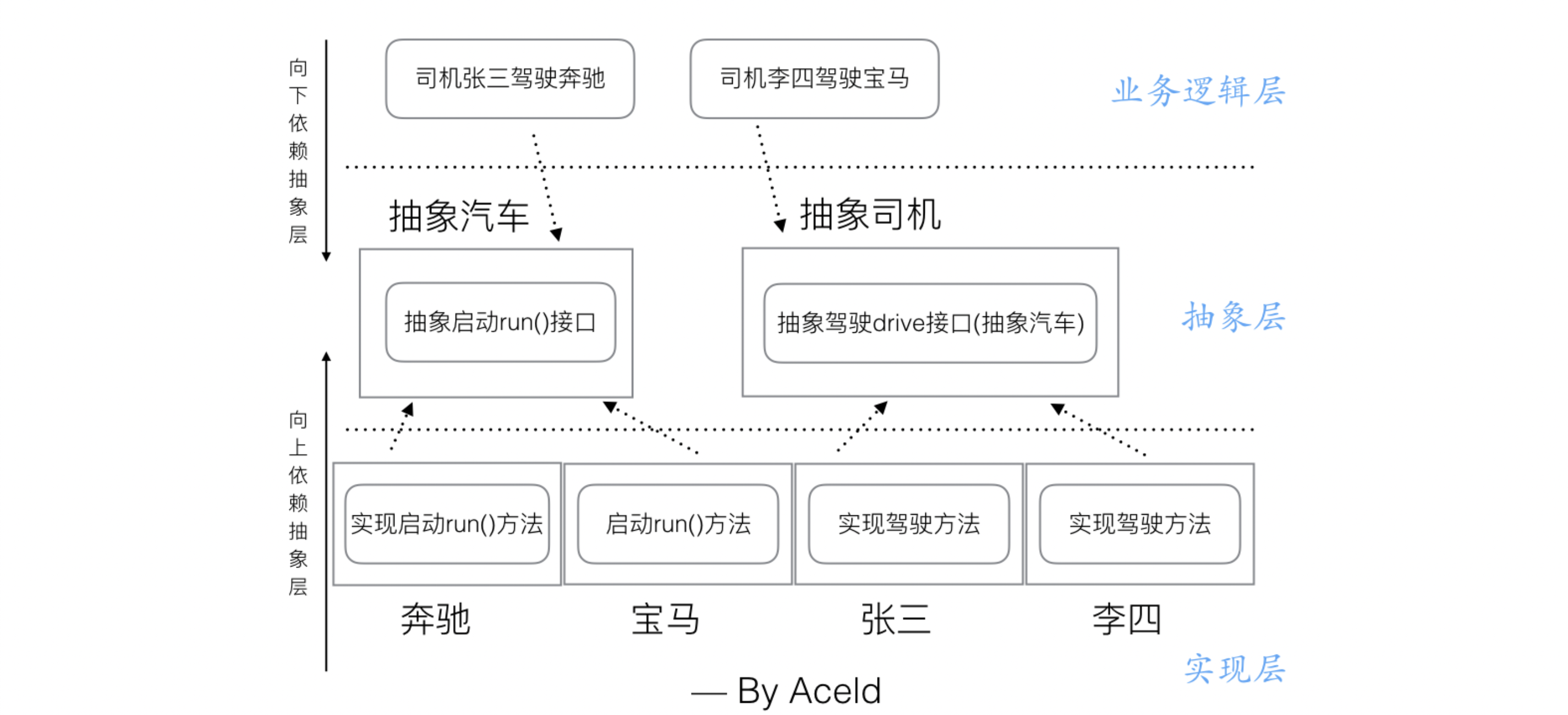
如上图所示,如果我们在设计一个系统的时候,将模块分为3个层次,抽象层、实现层、业务逻辑层。那么,我们首先将抽象层的模块和接口定义出来,这里就需要了
interface接口的设计,然后我们依照抽象层,依次实现每个实现层的模块,在我们写实现层代码的时候,实际上我们只需要参考对应的抽象层实现就好了,实现每个模块,也和其他的实现的模块没有关系,这样也符合了上面介绍的开闭原则。这样实现起来每个模块只依赖对象的接口,而和其他模块没关系,依赖关系单一。系统容易扩展和维护。package main import "fmt" // ===== > 抽象层 < ======== type Car interface { Run() } type Driver interface { Drive(car Car) } // ===== > 实现层 < ======== type BenZ struct { //... } func (benz * BenZ) Run() { fmt.Println("Benz is running...") } type Bmw struct { //... } func (bmw * Bmw) Run() { fmt.Println("Bmw is running...") } type Zhang_3 struct { //... } func (zhang3 *Zhang_3) Drive(car Car) { fmt.Println("Zhang3 drive car") car.Run() } type Li_4 struct { //... } func (li4 *Li_4) Drive(car Car) { fmt.Println("li4 drive car") car.Run() } // ===== > 业务逻辑层 < ======== func main() { //张3 开 宝马 var bmw Car bmw = &Bmw{} var zhang3 Driver zhang3 = &Zhang_3{} zhang3.Drive(bmw) //李4 开 奔驰 var benz Car benz = &BenZ{} var li4 Driver li4 = &Li_4{} li4.Drive(benz) }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
# 3. 依赖倒转小练习
结构体嵌入接口值,结构体初始化后可以返回嵌入的接口值类型
需求
- 模拟组装2台电脑 --- 抽象层 ---有显卡Card 方法display,有内存Memory 方法storage,有处理器CPU 方法calculate --- 实现层层 ---有 Intel因特尔公司 、产品有(显卡、内存、CPU),有 Kingston 公司, 产品有(内存3),有 NVIDIA 公司, 产品有(显卡) --- 逻辑层 ---1. 组装一台Intel系列的电脑,并运行,2. 组装一台 Intel CPU Kingston内存 NVIDIA显卡的电脑,并运行
实现
/* 模拟组装2台电脑 --- 抽象层 --- 有显卡Card 方法display 有内存Memory 方法storage 有处理器CPU 方法calculate --- 实现层层 --- 有 Intel因特尔公司 、产品有(显卡、内存、CPU) 有 Kingston 公司, 产品有(内存3) 有 NVIDIA 公司, 产品有(显卡) --- 逻辑层 --- 1. 组装一台Intel系列的电脑,并运行 2. 组装一台 Intel CPU Kingston内存 NVIDIA显卡的电脑,并运行 */ package main import "fmt" //------ 抽象层 ----- type Card interface{ Display() } type Memory interface { Storage() } type CPU interface { Calculate() } type Computer struct { cpu CPU mem Memory card Card } func NewComputer(cpu CPU, mem Memory, card Card) *Computer{ return &Computer{ cpu:cpu, mem:mem, card:card, } } func (this *Computer) DoWork() { this.cpu.Calculate() this.mem.Storage() this.card.Display() } //------ 实现层 ----- //intel type IntelCPU struct { CPU } func (this *IntelCPU) Calculate() { fmt.Println("Intel CPU 开始计算了...") } type IntelMemory struct { Memory } func (this *IntelMemory) Storage() { fmt.Println("Intel Memory 开始存储了...") } type IntelCard struct { Card } func (this *IntelCard) Display() { fmt.Println("Intel Card 开始显示了...") } //kingston type KingstonMemory struct { Memory } func (this *KingstonMemory) Storage() { fmt.Println("Kingston memory storage...") } //nvidia type NvidiaCard struct { Card } func (this *NvidiaCard) Display() { fmt.Println("Nvidia card display...") } //------ 业务逻辑层 ----- func main() { //intel系列的电脑 com1 := NewComputer(&IntelCPU{}, &IntelMemory{}, &IntelCard{}) //结构体嵌入接口值,结构体初始化后可以返回嵌入的接口值类型 com1.DoWork() //杂牌子 com2 := NewComputer(&IntelCPU{}, &KingstonMemory{}, &NvidiaCard{}) com2.DoWork() }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
# 五. 接口的意义
接口的意义就是为了实现解耦为了实现多态
- 接口的最大的意义就是实现多态的思想,就是我们可以根据interface类型来设计API接口,那么这种API接口的适应能力不仅能适应当下所实现的全部模块,也适应未来实现的模块来进行调用。
调用未来可能就是接口的最大意义所在吧,这也是为什么架构师那么值钱,因为良好的架构师是可以针对interface设计一套框架,在未来许多年却依然适用。