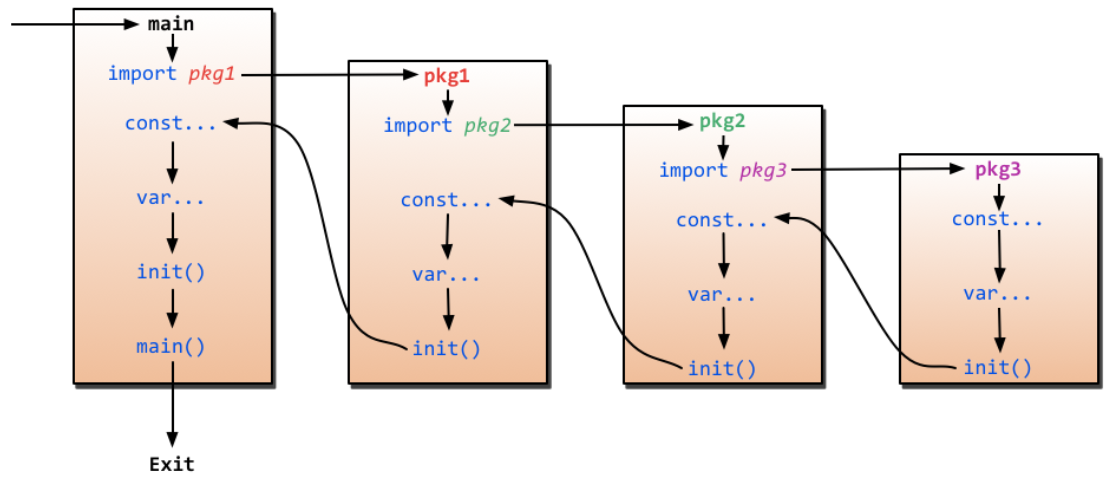
基础语法
基础语法
# 位-字节-字符-编码
1、位:数据存储的最小单位。每个二进制数字0或者1就是1个位;
2、字节:8个位构成一个字节;即:1 byte (字节)= 8 bit(位);
1 KB = 1024 B(字节);
1 MB = 1024 KB; (2^10 B)
1 GB = 1024 MB; (2^20 B)
1 TB = 1024 GB; (2^30 B)
3、字符:a、A、中、+、*、の......均表示一个字符 ;
unioncode 一个汉字4个字节表示
一般 utf-8 编码下,一个汉字 字符 占用 3 个 字节;
一般 gbk 编码下,一个汉字 字符 占用 2 个 字节;
2
3
4
5
6
7
8
9
10
11
12
13
# assic码
| ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 |
|---|---|---|---|---|---|---|---|
| 0 | NUT | 32 | (space) | 64 | @ | 96 | 、 |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | " | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | , | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | HT | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | - | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DCI | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | TB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | / | 124 | | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ` |
| 31 | US | 63 | ? | 95 | _ | 127 | DEL |
# 命名
go语言中的函数名、变量名、常量名、类型名、语句标号和包名等所有的命名,都遵循一个简单的命名规则
- 一个名字必须以一个字母或下划线开头,后面可以跟任意数量的字母、数字或下划线
go语言中有25个关键字,不能用于自定义名字
break default func interface select case defer go map struct chan else goto package switch const fallthrough if range type continue for import return var1
2
3
4
5还有30多个预定义的名字,用于内建的常量、类型和函数
//内建常量: true false iota nil //内建类型: int int8 int16 int32 int64 uint uint8 uint16 uint32 uint64 uintptr float32 float64 complex128 complex64 bool byte rune string error //内建函数: make len cap new append copy close delete complex real imag panic recover1
2
3
4
5
6
7
8
9
10
11
# 变量
package main
import "fmt"
func main() {
var a int
var b , c string
var (/* */
d int
e string
f bool
)
fmt.Println(a,b,c,d,e,f) // 0 0 false
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
第一种,指定变量类型,如果没有初始化,则变量默认为零值。
零值就是变量没有做初始化时系统默认设置的值。
数值类型(包括complex64/128)为 0
布尔类型为 false
字符串为 ""(空字符串)
以下几种类型为 nil:
var a *int var a []int var a map[string] int var a chan int var a func(string) int var a error // error 是接口1
2
3
4
5
6
第二种,根据值自行判定变量类型。
package main import "fmt" func main() { var d = true fmt.Println(d) }1
2
3
4
5
6第三种,省略 var, 注意 := 左侧如果没有声明新的变量,就产生编译错误,格式:
v_name := value //可以将 var f string = "Runoob" 简写为 f := "Runoob":1
2
# 常量
常量的定义格式:
const identifier [type] = value
在定义常量组时,如果不提供初始值,则表示将使用上行的表达式。
常量是一个简单值的标识符,在程序运行时,不会被修改的量。
常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串型。
# iota
iota,特殊常量,可以认为是一个可以被编译器修改的常量, 变量中不可使用。
iota 在 const关键字出现时将被重置为 0(const 内部的第一行之前),const 中每新增一行常量声明将使 iota 计数一次(iota 可理解为 const 语句块中的行索引)。
iota 可以被用作枚举值:
const (
a = iota //0
b = iota //1
c = iota //2
)
2
3
4
5
第一个 iota 等于 0,每当 iota 在新的一行被使用时,它的值都会自动加 1;所以 a=0, b=1, c=2 可以简写为如下形式:
const (
a = iota
b
c
)
2
3
4
5
- iota 只是在同一个 const 常量组内递增,每当有新的 const 关键字时,iota 计数会重新开始。
# iota 用法
package main
import "fmt"
func main() {
const (
a = iota *//0*
b *//1*
c *//2*
d = "ha" *//独立值,iota += 1*
e *//"ha" iota += 1*
f = 100 *//iota +=1*
g *//100 iota +=1*
h = iota *//7,恢复计数*
i *//8*
)
fmt.Println(a,b,c,d,e,f,g,h,i)
}
// 0 1 2 ha ha 100 100 7 8
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- iota 只是在同一个 const 常量组内递增,每当有新的 const 关键字时,iota 计数会重新开始。
# Iota 和左右运算符
package main
import "fmt"
const (
i=1<<iota
j=3<<iota
k
l
)
func main() {
fmt.Println("i=",i)
fmt.Println("j=",j)
fmt.Println("k=",k)
fmt.Println("l=",l)
}
/*
i= 1
j= 6
k= 12
l= 24 */
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
iota 表示从 0 开始自动加 1,所以 i=1<<0, j=3<<1(<< 表示左移的意思),即:i=1, j=6,这没问题,关键在 k 和 l,从输出结果看 k=3<<2,l=3<<3。
简单表述:
i=1:左移 0 位,不变仍为 1;
j=3:左移 1 位,变为二进制 110, 即 6;
k=3:左移 2 位,变为二进制 1100, 即 12;
l=3:左移 3 位,变为二进制 11000,即 24。
注:<<n==*(2^n)。
// 左移运算符 << 是双目运算符。左移 n 位就是乘以 2 的 n 次方。 其功能把 << 左边的运算数的各二进位全部左移若干位,由 << 右边的数指定移动的位数,高位丢弃,低位补 0。
//右移运算符 >> 是双目运算符。右移 n 位就是除以 2 的 n 次方。 其功能是把 >> 左边的运算数的各二进位全部右移若干位, >> 右边的数指定移动的位数。
2
3
# 数据类型
Go 语言按类别有以下几种数据类型:
| 序号 | 类型和描述 |
|---|---|
| 1 | 布尔型布尔型的值只可以是常量 true 或者 false。一个简单的例子:var b bool = true。 |
| 2 | 数字类型整型 int 和浮点型 float32、float64,Go 语言支持整型和浮点型数字,并且支持复数,其中位的运算采用补码。 |
| 3 | **字符串类型:**字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由单个字节连接起来的。Go 语言的字符串的字节使用 UTF-8 编码标识 Unicode 文本。 |
| 4 | 派生类型: 指针类型(Pointer) /数组类型 /结构化类型(struct) / Channel 类型 / 函数类型 /切片类型 /接口类型(interface) /Map 类型 |
字符串格式化

%v是万能的%T查看数据类型,类似reflect.typeOf()
# 字符串类型
a := "hello"
unsafe.Sizeof(a)
/*
输出结果为:16
字符串类型在 go 里是个结构, 包含指向底层数组的指针和长度,这两部分每部分都是 8 个字节,所以字符串类型大小为 16 个字节。
*/
2
3
4
5
6
- 关键字string,用""或者``反引号表示('""支持控制符号,反引号所有的都会原样输出)
- 占位符 '%s
- 万能占位符'%v'
# 字符串常用操作
长度 **len(str) ** ,返回一个int, 返回的是字节的长度, 中文的字节长3
拼接: 使用**+或者fmt.Sprintf()**
分割: strings.Split(str,'分割标识'), 返回一个切片
是否存在:
| 函数|返回值 | 作用 |
|---|---|
| strconv 包: | |
| Atoi(s string) (int, error) | 字符串转整型 |
| strings 包: | |
| Count(s, substr string) int | 计算子串substr在字符串s中出现的次数 |
| Compare(a, b string) int | 比较字符串大小 |
| Contains(s, substr string) bool | 判断字符串s中是否包含子串substr |
| ContainsAny(s, chars string) bool | 判断字符串s中是否包含chars中的某个Unicode字符 |
| ContainsRune(s string, r rune) bool | 判断字符串s中是否包含rune型值为r的字符 |
| Index(s, substr string) int | 查找子串substr在字符串s中第一次出现的位置,如果找不到则返回 -1,如果substr为空,则返回 0 |
| LastIndex(s, substr string) int | 查找子串substr在字符串s中最后出现的位置 |
| IndexRune(s string, r rune) int | 查找rune型值为r的字符在字符串s中出现的起始位置 |
| IndexAny(s, chars string) int | 查找字符串chars中字符,在字符串s中出现的起始位置 |
| LastIndexAny(s, chars string) int | 查找字符串s中出现chars中字符的最后位置 |
| LastIndexByte(s string, c byte) int | 查找byte型字符c在字符串s中的位置 |
| SplitN(s, sep string, n int) []string | 以字符串sep为分隔符,将字符串s切分成n个子串,结果中不包含sep本身。如果sep为空则将s切分为 Unicode 字符列表,如果s中没有sep子串则整个s作为切片 []string 中的第一个元素返回。参数n表示最多切出几个子串,s超出切分大小时,超出部分不再切分。n超出切分子串个数时,返回实际切分子串数。如果n为 0,则返回 nil;如果n小于 0,则不限制切分个数,全部切分 |
| SplitAfterN(s, sep string, n int) []string | 以字符串sep为分隔符,将字符串s切分成n个子串,结果中包含sep本身。如果sep为空则将s切分为 Unicode 字符列表,如果s中没有sep子串则整个s作为切片 []string 中的第一个元素返回。参数n表示最多切出几个子串,s超出切分大小时,超出部分不再切分。n超出切分子串个数时,返回实际切分子串数。如果n为 0,则返回 nil;如果n小于 0,则不限制切分个数,全部切分 |
| Split(s, sep string) []string | 以字符串sep为分隔符,将s切分成多个子串,结果中不包含sep本身。如果sep为空,则将s切分成 Unicode 字符列表,如果s中没有sep子串,则将整个s作为 []string 的第一个元素返回 |
| SplitAfter(s, sep string) []string | 以字符串sep为分隔符,将s切分成多个子串,结果中包含sep本身。如果sep为空则将s切分为 Unicode 字符列表,如果s中没有sep子串则整个s作为切片 []string 中的第一个元素返回。 |
| Fields(s string) []string | 以连续的空白字符为分隔符,将s切分成多个子串,结果中不包含空白字符本身。空白字符有:\t, \n, \v, \f, \r, '', U+0085 (NEL), U+00A0 (NBSP) 。如果s中只包含空白字符,则返回一个空切片 |
| FieldsFunc(s string, f func(rune) bool) []string | 以一个或多个满足函数f(rune)的字符为分隔符,将s切分成多个子串,结果中不包含分隔符本身。如果s中没有满足f(rune)的字符,则返回一个空切片 |
| Join(a []string, sep string) string | 以sep为拼接符,拼接切片a中的字符串 |
| HasPrefix(s, prefix string) bool | 判断字符串s是否以prefix字符串开头,是返回 true,否则返回 false |
| HasSuffix(s, suffix string) bool | 判断字符串s是否以suffix字符串结尾,是返回 true,否则返回 false |
| Map(f func(rune) rune, s string) string | 将字符串s中满足函数f(rune)的字符替换为f(rune)的返回值。如果f(rune)返回负数,则相应的字符将被删除 |
| Repeat(s string, count int) string | 返回字符串s重复count次数后的结果 |
| ToUpper(s string) string | 将字符串s中的小写字符转为大写 |
| ToLower(s string) string | 将字符串s中的大写字符转为小写 |
| ToTitle(s string) string | 将字符串s中的首个单词转为Title形式,大部分字符的Title格式就是Upper格式 |
| ToUpperSpecial(c unicode.SpecialCase, s string) string | 将字符串s中的所有字符修改为其大写格式,优先使用c中的规则进行转换 |
| ToLowerSpecial(c unicode.SpecialCase, s string) string | 将字符串s中的所有字符修改为其小写格式,优先使用c中的规则进行转换 |
| ToTitleSpecial(c unicode.SpecialCase, s string) string | 将字符串s中的所有字符修改为其Title格式,优先使用c中的规则进行转换 |
| Title(s string) string | 将字符串s中的所有单词的首字母修改为其Title格式(BUG: Title 规则不能正确处理 Unicode 标点符号) |
| TrimLeftFunc(s string, f func(rune) bool) string | 删除字符串s左边连续满足f(rune)的字符 |
| TrimRightFunc(s string, f func(rune) bool) string | 删除字符串s右边连续满足f(rune)的字符 |
| TrimFunc(s string, f func(rune) bool) string | 删除字符串s左右两边连续满足f(rune)的字符 |
| IndexFunc(s string, f func(rune) bool) int | 查找字符串s中第一个满足f(rune)的字符的字节位置,没有返回 -1 |
| LastIndexFunc(s string, f func(rune) bool) int | 查找字符串s中最后一个满足f(rune)的字符的字节位置,没有返回 -1 |
| Trim(s string, cutset string) string | 删除字符串s左右两边连续包含cutset的字符 |
| TrimLeft(s string, cutset string) string | 删除字符串s左边连续包含cutset的字符 |
| TrimRight(s string, cutset string) string | 删除字符串s右边连续包含cutset的字符 |
| TrimSpace(s string) string | 删除字符串s左右两边连续的空白字符 |
| TrimPrefix(s, prefix string) string | 删除字符串s 头部的prefix字符串 |
| TrimSuffix(s, suffix string) string | 删除字符串s 尾部的suffix字符串 |
| Replace(s, old, new string, n int) string | 替换字符串s中的old为new,如果old为空则在s中的每个字符间插入new包括首尾,n为替换次数, -1 时替换所有 |
| EqualFold(s, t string) bool | 忽略大小写比较字符串s和t,相同返回 true,反之返回 false |
1. 字符串转数字
- strconv.Atoi:
package main
import (
"fmt"
"strconv"
)
func main() {
var str = "111"
i, _ := strconv.Atoi(str)
fmt.Printf("%d\n", i) // 输出:111
}
2
3
4
5
6
7
8
9
10
11
12
2. 大小写规则转换
strings.ToUpperSpecial:将字符串s中的所有字符修改为其大写格式,优先使用c中的规则进行转换
strings.ToLowerSpecial:将字符串s中的所有字符修改为其小写格式,优先使用c中的规则进行转换
strings.ToTitleSpecial:将字符串s中的所有字符修改为其Title格式,优先使用c中的规则进行转换
c规则说明,以下列语句为例:
unicode.CaseRange{'A', 'Z', [unicode.MaxCase]rune{3, -3, 0}}
- 其中 'A', 'Z' 表示此规则只影响 'A' 到 'Z' 之间的字符。
- 其中
[unicode.MaxCase]rune数组表示: - 当使用 ToUpperSpecial 转换时,将字符的 Unicode 编码与第一个元素值(3)相加
- 当使用 ToLowerSpecial 转换时,将字符的 Unicode 编码与第二个元素值(-3)相加
- 当使用 ToTitleSpecial 转换时,将字符的 Unicode 编码与第三个元素值(0)相加
package main
import (
"fmt"
"strings"
"unicode"
)
func main() {
// 定义转换规则
var _MyCase = unicode.SpecialCase{
// 将半角逗号替换为全角逗号,ToTitle 不处理
unicode.CaseRange{',', ',',
[unicode.MaxCase]rune{',' - ',', ',' - ',', 0}},
// 将半角句号替换为全角句号,ToTitle 不处理
unicode.CaseRange{'.', '.',
[unicode.MaxCase]rune{'。' - '.', '。' - '.', 0}},
// 将 ABC 分别替换为全角的 ABC、abc,ToTitle 不处理
unicode.CaseRange{'A', 'C',
[unicode.MaxCase]rune{'A' - 'A', 'a' - 'A', 0}},
}
s := "ABCDEF,abcdef."
us := strings.ToUpperSpecial(_MyCase, s)
fmt.Printf("%q\n", us) // 输出:"ABCDEF,ABCDEF。"
ls := strings.ToLowerSpecial(_MyCase, s)
fmt.Printf("%q\n", ls) // 输出:"abcdef,abcdef。"
ts := strings.ToTitleSpecial(_MyCase, s)
fmt.Printf("%q\n", ts) // 输出:"ABCDEF,ABCDEF."
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 字符串原理
单引号是字符,双引号是字符串
字符串的底层就是一个byte数组,所以可以和 []byte 类型互相转换
字符串是由byte字节组成的,所以字符串的长度是byte字节的长度
rune类型用来表示utf8字符,一个rune字符由1个或多个byte组成
对包含中文的字符串排序
package main import ( "fmt" ) func main() { str := "ABCDEFGH你好" strRune := []rune(str) for i:=0 ; i<len(strRune)/2;i++{ item := strRune[i] strRune[i] = strRune[len(strRune)-1-i] strRune[len(strRune)-1-i] = item } fmt.Println(len(str)) // 14 fmt.Println(strRune) // [22909 20320 72 71 70 69 68 67 66 65] fmt.Println(string(strRune)) //好你HGFEDCBA }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
扩展
//1、位: 数据存储的最小单位。每个二进制数字0或者1就是1个位; //2、字节: 8个位构成一个字节;即:1 byte (字节)= 8 bit(位); 1 KB = 1024 B(字节); 1 MB = 1024 KB; (2^10 B) 1 GB = 1024 MB; (2^20 B) 1 TB = 1024 GB; (2^30 B) //3、字符: a、A、中、+、*、の......均表示一个字符; unicode,万国码,32位既4个字节表示一个字符; 一般 utf-8 编码下,一个汉字 字符 占用 3 个 字节; 一般 gbk 编码下,一个汉字 字符 占用 2 个 字节; //4、字节和字符: 字节是计算机传输数据的格式,供计算识别的。 字符是供人类观看的内容 //5、编码: 编码(encoding):把…译成密码。==》二进制 解码(decoding):破译(尤指密码) ==》破解密码成可以看的懂的 //6.编码格式: 字节和字符之间转换,参照的规则就是编码格式。 Unicode 编码共有三种具体实现,分别为utf-8,utf-16,utf-32,其中utf-8占用一到四个字节,utf-16占用二或四个字节,utf-32占用四个字节。 Unicode码的前128个字符就是ASCII码,之后是ASCII码的扩展码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 数字类型
Go 也有基于架构的类型,例如:int、uint 和 uintptr。
所有整数初始化为0,所有浮点数初始化为0.0,布尔类型初始化为 false
| 序号 | 类型和描述 |
|---|---|
| 1 | uint8无符号 8 位整型 (0 到 255) |
| 2 | uint16无符号 16 位整型 (0 到 65535) |
| 3 | uint32无符号 32 位整型 (0 到 4294967295) |
| 4 | uint64无符号 64 位整型 (0 到 18446744073709551615) |
| 5 | int8有符号 8 位整型 (-128 到 127) |
| 6 | int16有符号 16 位整型 (-32768 到 32767) |
| 7 | int32有符号 32 位整型 (-2147483648 到 2147483647) |
| 8 | int64有符号 64 位整型 (-9223372036854775808 到 9223372036854775807) |
# 浮点型
| 序号 | 类型和描述 |
|---|---|
| 1 | float32IEEE-754 32位浮点型数 |
| 2 | float64IEEE-754 64位浮点型数 |
| 3 | complex6432 位实数和虚数 |
| 4 | complex12864 位实数和虚数 |
# 其他数字类型
以下列出了其他更多的数字类型:
| 序号 | 类型和描述 |
|---|---|
| 1 | byte类似 uint8 |
| 2 | rune类似 int32 |
| 3 | uint32 或 64 位 |
| 4 | int与 uint 一样大小 |
| 5 | uintptr无符号整型,用于存放一个指针 |
# 时间和日期
time 包
- 时间
now := time.Now() fmt.Println(now) // 分别获取年月日等 year := now.Year() month := now.Month() day := now.Day() hour := now.Hour() minute := now.Minute() send := now.Second()1
2
3
4
5
6
7
8
9
10
// 时间格式化 timer := time.Now() res := timer.Format("2006-01-02 15:04:05")
- `%02d 不足两位的数字在前面补0`
- 时间戳
```go
// 获取时间戳
timeStamp := time.Now().Unix()
fmt.Println(timeStamp)
// 时间戳转时间
nowObj := time.Unix(timeStamp,0)
year =nowObj.Year()
month =nowObj.Month()
day =nowObj.Day()
fmt.Printf("%02d-%02d-%02d ",year,month,day)
// %02d 不足两位的数字在前面补0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 运算符
Go 语言内置的运算符有:
- 算术运算符
- 关系运算符
- 逻辑运算符
- 位运算符
- 赋值运算符
- 其他运算符
# 算术运算符
下表列出了所有Go语言的算术运算符。假定 A 值为 10,B 值为 20。
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 相加 | A + B 输出结果 30 |
| - | 相减 | A - B 输出结果 -10 |
| * | 相乘 | A * B 输出结果 200 |
| / | 相除 | B / A 输出结果 2 |
| % | 求余 | B % A 输出结果 0 |
| ++ | 自增 | A++ 输出结果 11 |
| -- | 自减 | A-- 输出结果 9 |
# 关系运算符
下表列出了所有Go语言的关系运算符。假定 A 值为 10,B 值为 20。
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 检查两个值是否相等,如果相等返回 True 否则返回 False。 | (A == B) 为 False |
| != | 检查两个值是否不相等,如果不相等返回 True 否则返回 False。 | (A != B) 为 True |
| > | 检查左边值是否大于右边值,如果是返回 True 否则返回 False。 | (A > B) 为 False |
| < | 检查左边值是否小于右边值,如果是返回 True 否则返回 False。 | (A < B) 为 True |
| >= | 检查左边值是否大于等于右边值,如果是返回 True 否则返回 False。 | (A >= B) 为 False |
| <= | 检查左边值是否小于等于右边值,如果是返回 True 否则返回 False。 | (A <= B) 为 True |
# 逻辑运算符
下表列出了所有Go语言的逻辑运算符。假定 A 值为 True,B 值为 False。
| 运算符 | 描述 | 实例 |
|---|---|---|
| && | 逻辑 AND 运算符。 如果两边的操作数都是 True,则条件 True,否则为 False。 | (A && B) 为 False |
| || | 逻辑 OR 运算符。 如果两边的操作数有一个 True,则条件 True,否则为 False。 | (A || B) 为 True |
| ! | 逻辑 NOT 运算符。 如果条件为 True,则逻辑 NOT 条件 False,否则为 True。 | !(A && B) 为 True |
# 位运算符
位运算符对整数在内存中的二进制位进行操作。
下表列出了位运算符 &, |, 和 ^ 的计算:
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
假定 A = 60; B = 13; 其二进制数转换为:
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A|B = 0011 1101
A^B = 0011 0001
2
3
4
5
6
7
8
9
10
11
Go 语言支持的位运算符如下表所示。假定 A 为60,B 为13:
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符"&"是双目运算符。 其功能是参与运算的两数各对应的二进位相与。 | (A & B) 结果为 12, 二进制为 0000 1100 |
| | | 按位或运算符"|"是双目运算符。 其功能是参与运算的两数各对应的二进位相或 | (A | B) 结果为 61, 二进制为 0011 1101 |
| ^ | 按位异或运算符"^"是双目运算符。 其功能是参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1。 | (A ^ B) 结果为 49, 二进制为 0011 0001 |
| << | 左移运算符"<<"是双目运算符。左移n位就是乘以2的n次方。 其功能把"<<"左边的运算数的各二进位全部左移若干位,由"<<"右边的数指定移动的位数,高位丢弃,低位补0。 | A << 2 结果为 240 ,二进制为 1111 0000 |
| >> | 右移运算符">>"是双目运算符。右移n位就是除以2的n次方。 其功能是把">>"左边的运算数的各二进位全部右移若干位,">>"右边的数指定移动的位数。 | A >> 2 结果为 15 ,二进制为 0000 1111 |
以下实例演示了位运算符的用法:
package main
import "fmt"
func main() {
var a uint = 60 /* 60 = 0011 1100 */
var b uint = 13 /* 13 = 0000 1101 */
var c uint = 0
c = a & b */\* 12 = 0000 1100 \*/*
fmt.Printf("第一行 - c 的值为 %d**\n**", c )
c = a | b */\* 61 = 0011 1101 \*/*
fmt.Printf("第二行 - c 的值为 %d**\n**", c )
c = a ^ b */\* 49 = 0011 0001 \*/*
fmt.Printf("第三行 - c 的值为 %d**\n**", c )
c = a << 2 */\* 240 = 1111 0000 \*/*
fmt.Printf("第四行 - c 的值为 %d**\n**", c )
c = a >> 2 */\* 15 = 0000 1111 \*/*
fmt.Printf("第五行 - c 的值为 %d**\n**", c )
}
/*
第一行 - c 的值为 12
第二行 - c 的值为 61
第三行 - c 的值为 49
第四行 - c 的值为 240
第五行 - c 的值为 15
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 赋值运算符
下表列出了所有Go语言的赋值运算符。
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,将一个表达式的值赋给一个左值 | C = A + B 将 A + B 表达式结果赋值给 C |
| += | 相加后再赋值 | C += A 等于 C = C + A |
| -= | 相减后再赋值 | C -= A 等于 C = C - A |
| *= | 相乘后再赋值 | C *= A 等于 C = C * A |
| /= | 相除后再赋值 | C /= A 等于 C = C / A |
| %= | 求余后再赋值 | C %= A 等于 C = C % A |
| <<= | 左移后赋值 | C <<= 2 等于 C = C << 2 |
| >>= | 右移后赋值 | C >>= 2 等于 C = C >> 2 |
| &= | 按位与后赋值 | C &= 2 等于 C = C & 2 |
| ^= | 按位异或后赋值 | C ^= 2 等于 C = C ^ 2 |
| |= | 按位或后赋值 | C |= 2 等于 C = C | 2 |
# 其他运算符
下表列出了Go语言的其他运算符。
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 返回变量存储地址 | &a; 将给出变量的实际地址。 |
| * | 指针变量。 | *a; 是一个指针变量 |
package main
import "fmt"
func main() {
var a int = 4
var b int32
var c float32
var ptr *int
/* 运算符实例 */
fmt.Printf("第 1 行 - a 变量类型为 = %T\n", a );
fmt.Printf("第 2 行 - b 变量类型为 = %T\n", b );
fmt.Printf("第 3 行 - c 变量类型为 = %T\n", c );
/* & 和 * 运算符实例 */
ptr = &a /* 'ptr' 包含了 'a' 变量的地址 */
fmt.Printf("a 的值为 %d\n", a);
fmt.Printf("*ptr 为 %d\n", *ptr);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 运算符优先级
有些运算符拥有较高的优先级,二元运算符的运算方向均是从左至右。下表列出了所有运算符以及它们的优先级,由上至下代表优先级由高到低:
| 优先级 | 运算符 |
|---|---|
| 5 | * / % << >> & &^ |
| 4 | + - | ^ |
| 3 | == != < <= > >= |
| 2 | && |
| 1 | || |
# Golang代码执行步骤