 如何保证缓存和数据库双写一致
如何保证缓存和数据库双写一致
- 只要用到了缓存,就可能会涉及到缓存与数据库双存储双写,就一定会有数据一致性的问题
# 先删除缓存
# 1. 问题
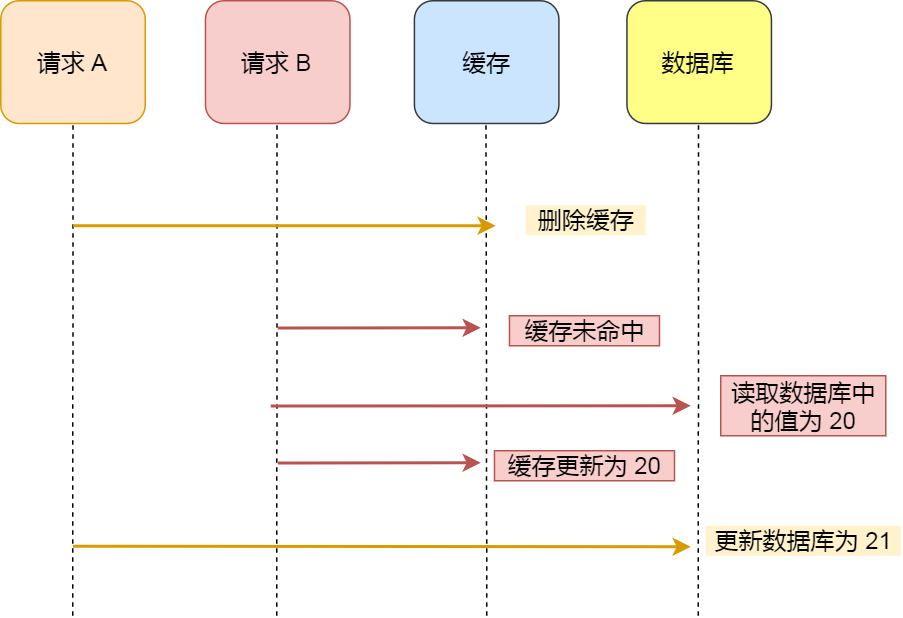
如果先删除Redis缓存数据,然而还没有来得及写入MySQL,另一个线程就来读取。
这个时候发现缓存为空,则去Mysql数据库中读取旧数据写入缓存,此时缓存中为脏数据。
然后数据库更新后发现Redis和Mysql出现了数据不一致的问题。
# 2. 解决策略
数据库与缓存更新与读取操作进行异步串行化
- 缺点: 非常复杂, 效率不高
延时双删策略: 在写库前后都进行redis.del(key)操作,并且设定合理的超时时间
- 增加请求耗时,存在删除失败问题
- 如果删除失败就要引入失败重试机制
参照go的
singleflight,原理参照我的博客: singlefight实现原理 (opens new window)
# 后删除缓存
- 如果先写了库,然后再删除缓存,不幸的写库的线程挂了,导致了缓存没有删除
- 这个时候就会直接读取旧缓存,最终也导致了数据不一致情况
- 因为写和读是并发的,没法保证顺序,就会出现缓存和数据库的数据不一致的问题
# 1. 问题
- 数据库更新完后, 魂村有可能写入失败这个时候就会直接读取旧缓存,最终也导致了数据不一致情况
# 2. 解决办法
如果删除失败就要引入失败重试机制
步骤
1、业务代码去更新数据库 2、数据库的操作进行记录日志。 3、订阅程序提取出所需要的数据以及key 4、获得该信息尝试删除缓存,发现删除失败的时候,发送消息到消息队列 5、继续重试删除缓存的操作,直到删除缓存成功。1
2
3
4
5
# Cache Aside Pattern
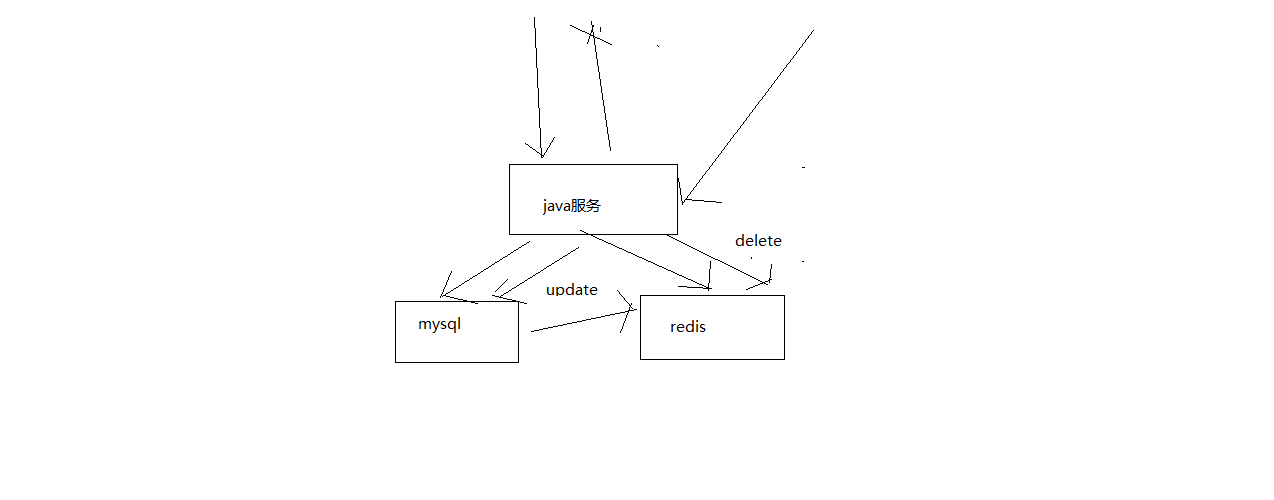
最经典的缓存+数据库读写的模式,cache aside pattern, 先删除缓存
- 读的时候,先读缓存,缓存没有的话,那么就读数据库,然后取出数据后放入缓存,同时返回响应
- 更新的时候,先删除缓存,然后再更新数据库
为什么是删除缓存, 而不是更新缓存呢?
更新缓存的代价是很高: 很多时候,复杂点的缓存的场景,因为缓存有的时候,不简单是数据库中直接取出来的值,
如果你频繁修改一个缓存涉及的多个表,那么这个缓存会被频繁的更新,频繁的更新缓存,但是问题在于,这个缓存到底会不会被频繁访问到?每次数据过来,就只是删除缓存,然后修改数据库,如果这个缓存,在1分钟内只是被访问了1次,那么只有那1次,缓存是要被重新计算的,用缓存才去算缓存
举个例子,一个缓存涉及的表的字段,在1分钟内就修改了20次,或者是100次,那么缓存更新20次,100次; 但是这个缓存在1分钟内就被读取了1次,有大量的冷数据
28法则,黄金法则,20%的数据,占用了80%的访问量
实际上,如果你只是删除缓存的话,那么1分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低
# 造成缓存双写不一致的原因
# 1. 最初级的缓存不一致问题
问题:先修改数据库,再删除缓存,如果删除缓存失败了,那么会导致数据库中是新数据,缓存中是旧数据,数据出现不一致,解决思路是:先删除缓存,再修改数据库,如果删除缓存成功了,如果修改数据库失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致,因为读的时候缓存没有,则读数据库中旧数据,然后更新到缓存中
假设删除缓存成功,但是更新数据库失败了,那么不会出现双写不一致的问题
# 2. 复杂的数据不一致问题
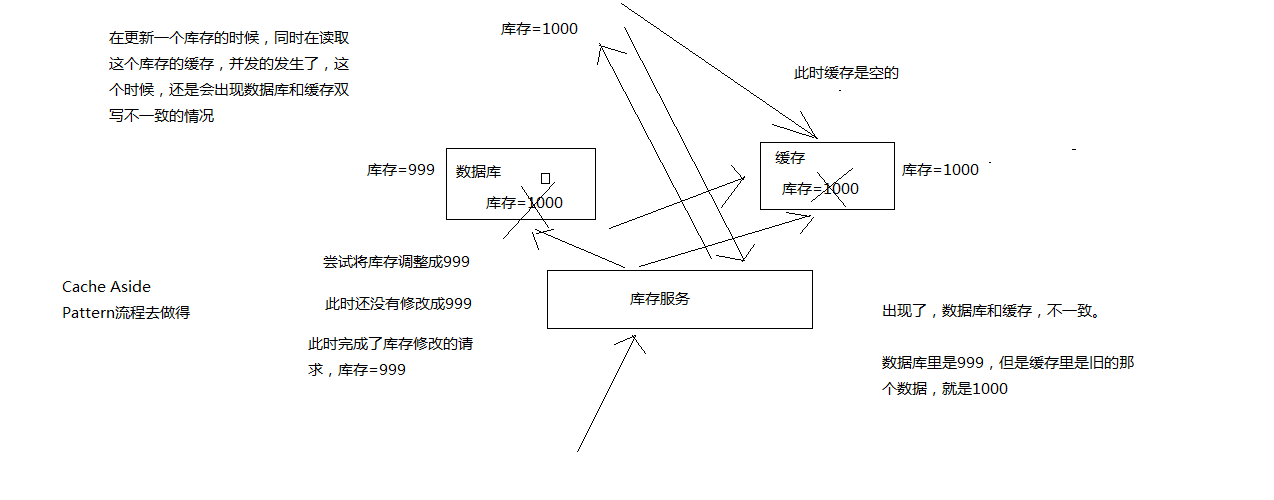
数据发生了变更,先删除了缓存,然后要去修改数据库,此时还没修改
一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中
数据变更的程序完成了数据库的修改, 数据库和缓存中的数据不一样了
# 3. 从库延迟
- 主从模式会造成缓存一致性问题
- 解决办法
- 区分最终一致性很高和不高的缓存数据,查询数据时,将要求很高的数据必须从主库读取,而把要求不高的数据从从库读取。对于使用了rockscache的应用来说,高并发的请求都会在Redis这一层被拦截,对于一个数据,最多只会有一个请求到达数据库,因此数据库的负载已大幅降低,采用主库读取是一个实际可行的方案。
- 主从分离需要采用不分叉的单链架构,那么链条末尾的从库必定是延迟最长的从库,此时采用监听binlog的方案,需要监听链条做末端的从库binlog,当收到数据变更通知时,按照上述方案将缓存标记为删除。
# 不一致问题解决
# 1. 异步串行化
数据库与缓存更新与读取操作进行异步串行化,先删除缓存再操作数据库
更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个队列中,读取数据的时候,如果发现数据不在缓存中,那么将重新读取数据+更新缓存的操作,根据唯一标识路由之后,也发送同一个队列中,一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行
这样的话,一个数据变更的操作,先执行,删除缓存,然后再去更新数据库,但是还没完成更新
此时如果一个读请求过来,读到了空的缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤,如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可
待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中
如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回; 如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值
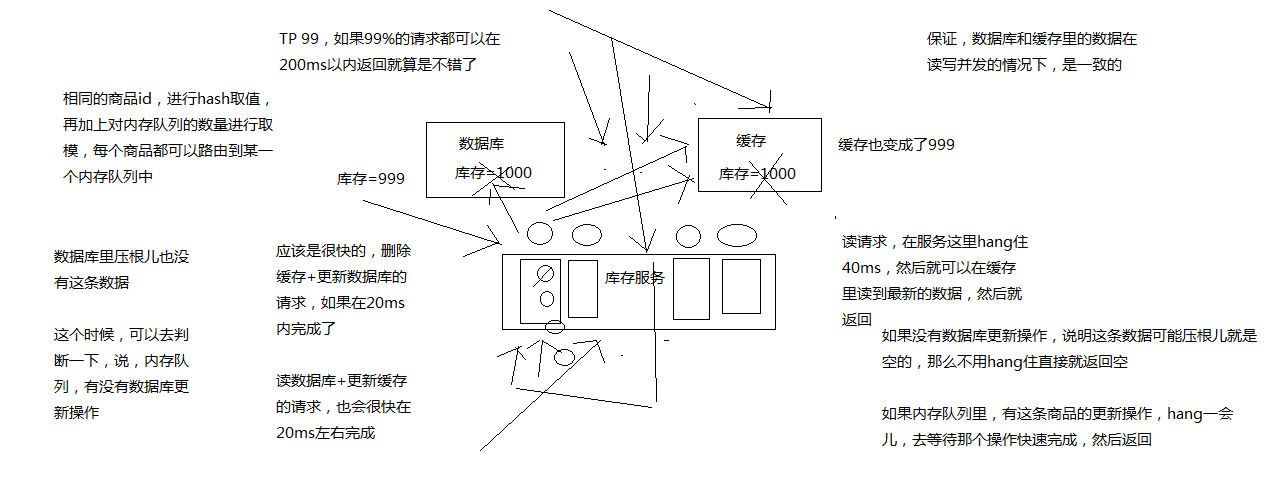
假设出现了数据库没有这条数据的场景时:
这个时候需要判断一下,内存队列中有没有数据库更新操作,如果没有数据库更新操作,说明这条数据压根可能就是空的,那么不用hang住,直接就返回空。
# a. 更新与读取请求串行化缺点
一般来说,如果系统不是严格要求缓存 + 数据库必须一致性的话,缓存可以稍微的跟数据库偶尔有不一致的情况,最好不要使用这个方案,因为读请求 和 写请求 串行化,串到一个内存队列中去,这样就可以保证一定不会出现不一致的情况。
串行化之后,就会导致系统的吞吐量大幅度的降低,用比较正常情况下多几倍的机器去支撑线上的请求。
# b. go实现方案
- 使用内置的系统包singlefight, 实现原理参考: singlefight实现原理 (opens new window)
# 2. 双删
读数据之前删除缓存, 更新数据之后再次删除缓存
- 仍会存在数据不一致情况
- 请求一进来, 删除缓存, 更新数据库
- 数据库在更新过程中,另外的请求二进来, 读取数据库, 写缓存(旧值)
- 请求一更新数据库成功, 但是缓存数据不一致
- 请求三进来发生数据不一致情况(极少)
- 删除缓存
- 请求四进入, 读取数据库, 写缓存, 数据最终一致
# 3. 延时双删
先删除一次缓存,延时几百毫秒再删除一次。这种做法只能够进一步降低不一致的概率,但无法保证
# 4. 缓存更新失败, 重试机制
写缓存
引入mq组件
在缓存更新失败时, 将信息写入mq,
一直异步重试, 直到成功
删缓存一样
# 5. 异步更新缓存
订阅 MySQL binlog,再操作缓存
「先更新数据库,再删缓存」的策略的第一步是更新数据库,那么更新数据库成功,就会产生一条变更日志,记录在 binlog 里。
于是我们就可以通过订阅 binlog 日志,拿到具体要操作的数据,然后再执行缓存删除,阿里巴巴开源的 Canal 中间件就是基于这个实现的。
Canal 模拟 MySQL 主从复制的交互协议,把自己伪装成一个 MySQL 的从节点,向 MySQL 主节点发送 dump 请求,MySQL 收到请求后,就会开始推送 Binlog 给 Canal,Canal 解析 Binlog 字节流之后,转换为便于读取的结构化数据,供下游程序订阅使用。
go语言监听binlog工具
github.com/go-mysql-org/go-mysqlhttps://github.com/wj596/go-mysql-transfer
# 6. dtm解决方案(!!!推荐)
推荐库: https://github.com/dtm-labs/rockscache
示例: https://github.com/dtm-labs/dtm-cases/tree/main/cache
缓存中存入的值数据解雇
value: 数据本身 lockUtil: 数据锁定到期时间,当某个进程查询缓存无数据,那么先锁定缓存一小段时间,然后查询DB,然后更新缓存 owner: 数据锁定者uuid,用于校验缓存者身份1
2
3
# a. 流程原理
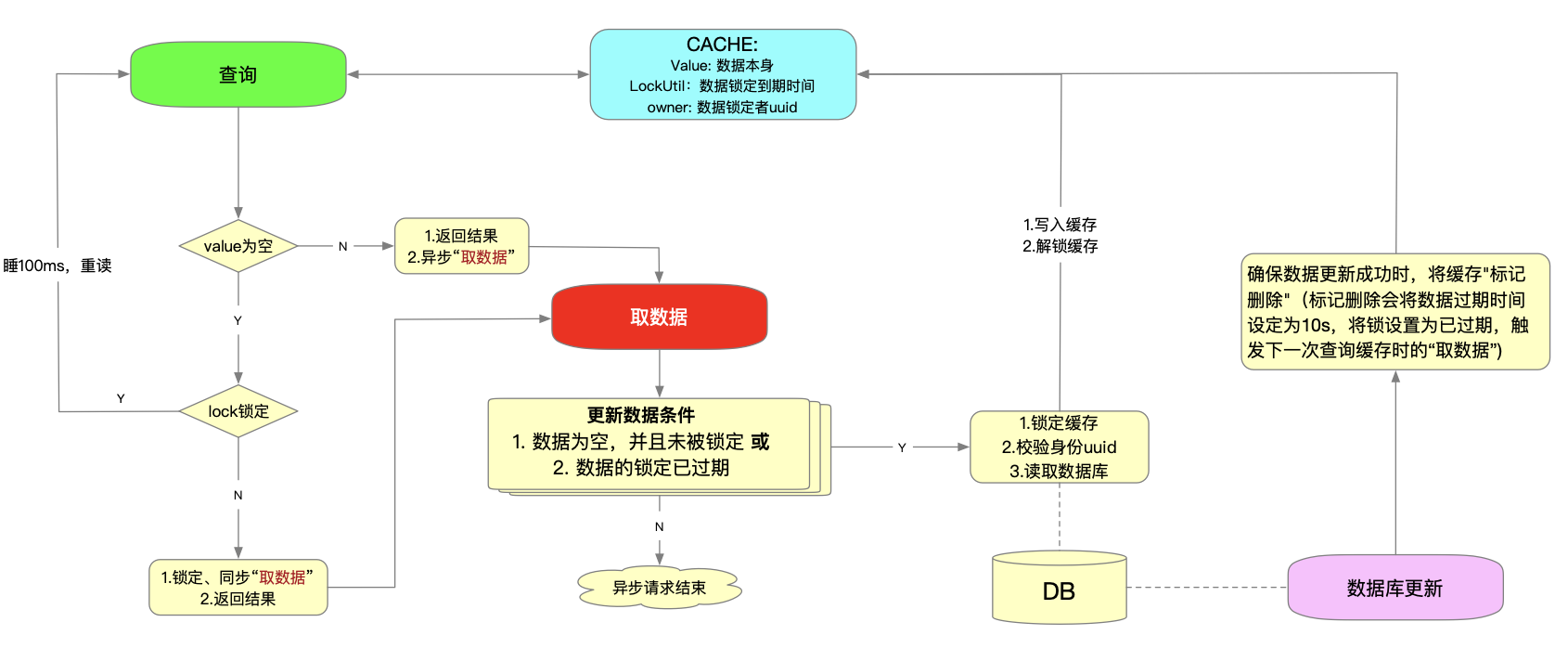
查询数据流程:
- 如果数据为空,且被锁定,则睡眠100ms后,重新查询
- 如果数据为空,且未被锁定,同步执行"取数据",返回结果
- 如果数据不为空,那么立即返回结果,并异步执行"取数据"
"取数据"流程:
- 判断是否需要更新缓存,下面两个条件满足其一,则需要更新缓存
- 数据为空,并且未被锁定
- 数据的锁定已过期
- 如果需要更新,则锁定缓存,查询DB,校验锁持有者无变化,写入缓存,解锁缓存
DB数据更新流程:
- DB数据更新时,确保数据更新成功时,将缓存"标记删除"(标记删除会将数据过期时间设定为10s,将锁设置为已过期,触发下一次查询缓存时的“取数据”)