 Mysql数据库中间件kingshard
Mysql数据库中间件kingshard
# kingshard简介
kingshard doc: https://github.com/flike/kingshard/blob/master/README_ZH.md
kingshard是一个由Go开发高性能MySQL Proxy项目,kingshard在满足基本的读写分离的功能上,致力于简化MySQL分库分表操作;能够让DBA通过kingshard轻松平滑地实现MySQL数据库扩容。 kingshard的性能是直连MySQL性能的80%以上
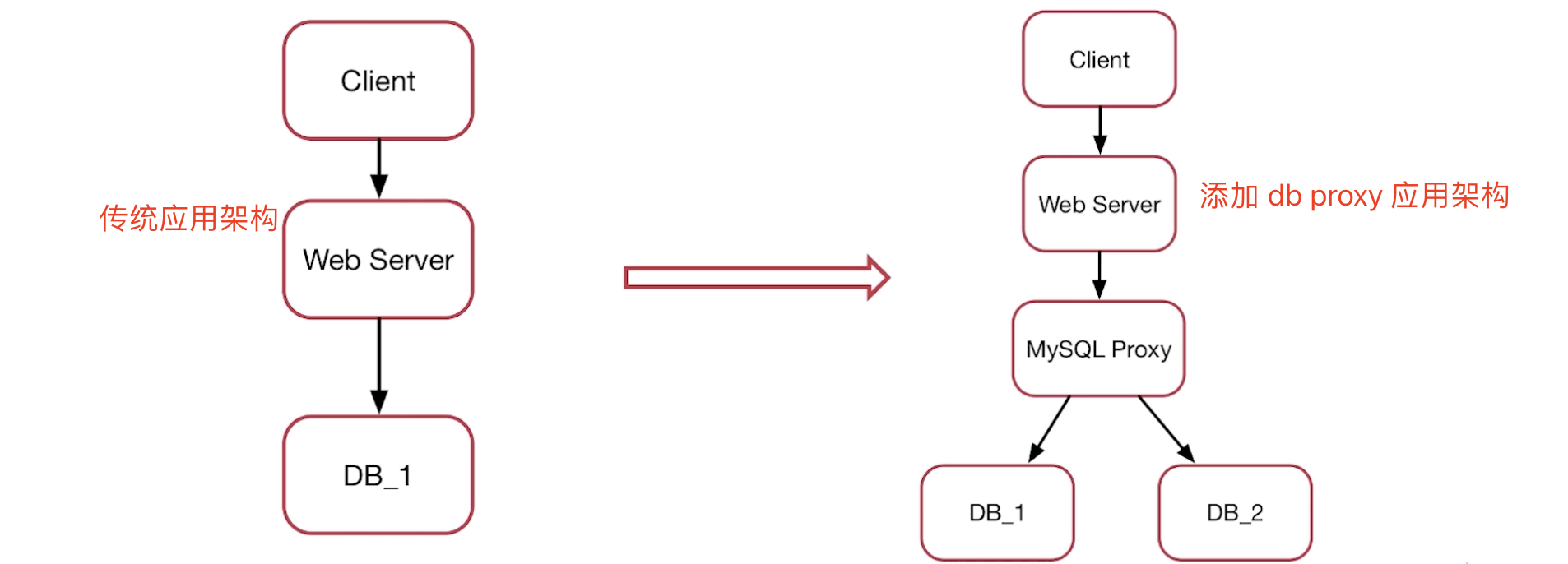
现在开源的MySQL Proxy已经有几款了,并且有的已经在生产环境上广泛应用。但这些proxy在sharding方面,都是不能分子表的。也就是说一个node节点只能分一张表。但我们的线上需求通常是这样的:
我有一张非常大的表,行数超过十亿,需要进行拆分处理。假设拆分因子是512。 如果采用单node单数据库的分表方式,那其实这512个子表还是存在一个物理节点上,意义不大。 如果采用他们的sharding功能,就需要512个物理节点,也不现实。 面对这种需求,现有的proxy就不能很好地满足要求了。通常我们希望将512张子表均分在几个MySQL节点上,从而达到系统的横向扩展。
然而kingshard较好地实现了这种典型的需求。简单来说,kingshard的分表方案采用两级映射的方式:
1.kingshard将该表分成512张子表,例如:test_0000,test_0001,... test_0511。 2.将shardKey通过hash或range方式定位到其要操作的记录在哪张子表上。 3.子表落在哪个node上通过配置文件设置。1
2
3
4
# MySQL Proxy解决的问题
SQL请求的读写分离

DB运维与业务代码严重耦合
# kingshard架构
# 1. 基础架构
kingshard采用Go开发,充分地利用了Go语言的并发特性。Go语言在并发方面,做了很好的封装,这大大简化了kingshard的开发工作。kingshard的整体工作流程如下所述:
- 读取配置文件并启动,在配置文件中设置的监听端口监听客户端请求。
- 收到客户端连接请求后,启动一个goroutine单独处理该请求。
- 首选进行登录验证,验证过程完全兼容MySQL认证协议,由于用户名和密码在配置文件中已经设置好,所以可以利用该信息验证连接请求是否合法。 当用户名和密码都正确时,转入下面的步骤,否则返回出错信息给客户端。
- 认证通过后,客户端发送SQL语句。
- kingshard对客户端发送过来的SQL语句,进行词法和语义分析,识别出SQL的类型和生成SQL的路由计划。如果有必要还会改写SQL,然后转发到相应的DB。也有可能不做词法和语义分析直接转发到相应的后端DB。如果转发SQL是分表且跨多个DB,则每个DB对应启动一个goroutine发送SQL和接收该DB返回的结果。
- 接收并合并结果,然后转发给客户端。
工作流程
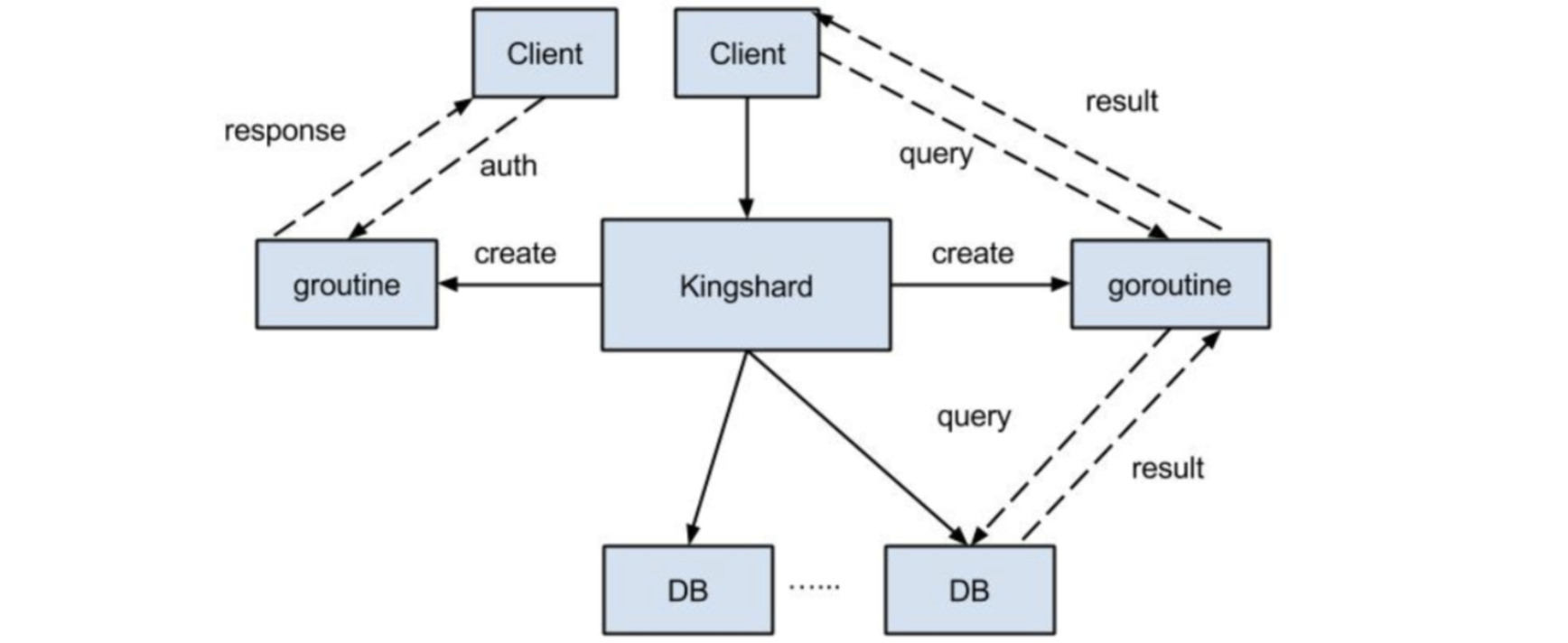
kingshard整体架构
# 2. 词法和语义分析
要将kingshard的功能做的足够强大,就不得不进行SQL的词法和语义分析。SQL语句的词法分析指的是将SQL语句切分成一个一个的关键字。例如对SQL语句:select name from stu where id < 13进行词法分析,得到的结果是:{"select","name","from","stu","where","id","<","13"}。 这样做的目的主要为了生成一棵抽象语法树,也就是大家常说的AST(abstract syntax tree),语义分析就是基于这棵语法树来操作的。语义分析的目的主要有以下几个方面:
- 读写分离,只有识别出SQL语句的类型,才能进行正确的读写分离操作。
- 数据分片,解析出表名和查询条件,将SQL路由到正确的DB。
- SQL黑名单,通过词法和语义分析,也可以快速识别出需要屏蔽的SQL语句。例如,检测到delete语句不带where操作,就可以直接阻断该SQL的转发。
kingshard并没有考虑完全兼容MySQL所有语法,因为完全兼容MySQL语法会使得词法和语义分析模块变得异常复杂,而且低效。对于DDL语句其实没必要解析,只要能正确转发到后端相应的DB上就可以。
kingshard只对部分DML语句(select,update,insert,delete,replace)进行了解析,这样可以满足绝大部分的分表操作。对于其他语句,kingshard会将其发送到一个默认的DB,或者通过kingshard特有的方式将其发送到指定的DB上,例如: /*node2*/insert into stu(id,name) values(12,'xiaoming'),对于这种带有注释的的sql语句,kingshard能够识别出,然后将这条sql语句发送到node2节点的Master DB上。
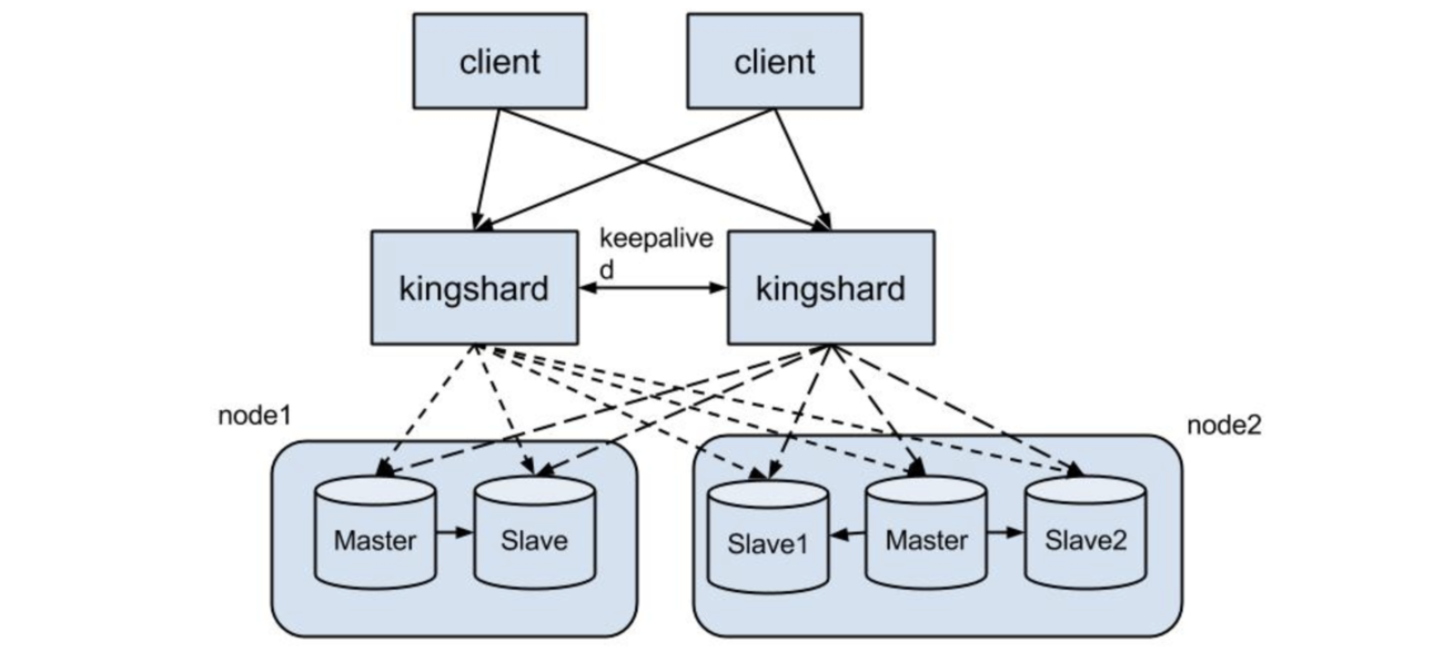
# 3. 负载均衡
用户使用Mysql Proxy目的很大一部分就是为了降低单台DB的负载,将读压力分担到多台DB上。kingshard支持多个slave,不同的slave可以配置不同的读权重,权重越大分担的读请求越多。kingshard读请求负载均衡采用的是权重轮询调度算法。
大部分系统采用该算法时,都是转发SQL语句时,动态地计算出本次选取DB的序号。然后将读请求的SQL语句发送到该DB。仔细分析一下,这样做其实是没有必要的。因为DB的权重是相对固定的,不会经常变动,所以完全可以计算出一个固定的轮询序列,然后将这个序列保存在一个数组中。这样不需要动态计算,每次读取数组就可以。举个例子来说,在kingshard的node配置项中配置slave选项:slave:192.168.0.12@2,192.168.0.13@3 kingshard在读取配置信息初始化系统的时候,就生成了一个轮询数组:[0,0,1,1,1]。在kingshard中会将这个数组打乱顺序,变成:[0,1,1,0,1]。这样就避免了动态计算DB下标的问题,对性能提升有一定帮助。
# 4.sharding实现
首选需要介绍两个概念:
- 子表,在kingshard中一张逻辑上的大表由若干张小的子表组成。例如:将stu表分成stu_0000,stu_0001,stu_0002,stu_0003。 在数据库中stu表是不存在的,它只是一张逻辑上的表。数据库中只存在四张子表(stu_0000,stu_0001,stu_0002,stu_0003)。 发送SQL语句时,kingshard会识别出需要分表的SQL语句,并改写该SQL。例如,客户端发送过来的SQL语句是
:select name from stu where id =10;kingshard收到该SQL语句后,从配置信息中识别出该表是一个Hash类型的分表。根据分表规则,将该SQL改写成:select name from stu_2 where id =10;然后发送给对应的DB。 - Node,子表分布在各个node上,每个node包含一个maser server和若干个slave server(slave个数可以为0)。写请求会发往该node中master server,读请求会发往该node中的slave server。
kingshard的sharding采用了两级映射的思想,首选根据SQL语句的分表条件计算出这条SQL语句落在哪个子表上,然后再根据配置信息找到该子表 落在哪个node上。采用两级映射的思想,对于MySQL的扩容和缩容都能很方便地支持。目前kingshard sharding支持insert, delete, select, update和replace语句, 所有这五类操作都支持跨子表。但写操作仅支持单node上的跨子表,select操作则可以跨node,跨子表。
对于有些表没有分表,操作该表的SQL语句会发往default node。或者用户可以选择在SQL语句前面加上注释,指定该SQL要发往的node,kingshard接收到语句后,识别出注释中指定的node,然后将该SQL发往对应node中合适的DB。例如用户发送/*node1*/select * from member where id=100,kingshard接收到该SQL后会将其发送到node1的salve上。这样kingshard就能很好地兼容分表和不分表的各种应用场景了。
# 5. 事务的实现
所有proxy支持shard后都会面临一个问题:支不支持分布式事务?出于性能和可用性考虑, kingshard只支持单台DB上的事务,不允许跨DB的事务。kingshard处理单DB上的事务流程如下:
- 用户发送begin语句。
- kingshard接收到SQL语句后,将该连接的状态设置为事务。
- 用户发送DML语句,kingshard识别出语句需要发送到的DB,然后kingshard新建一个与后端DB的连接,利用该连接发送语句。
- 收取SQL语句的结果后,将连接放回。
- kingshard收到下一条SQL语句,判断该SQL是不是发往同一个DB,如果不是则报错。如果是发往同一个DB,则利用该连接发送语句。
- 收到用户发送的commit语句,将该连接的状态设置为非事务,事务结束。
# 6. 后端DB存活检测
kingshard每个node启动了一个goroutine用于检测后端master和slave的状态。当goroutine持续一段时间(由配置文件中down_after_noalive参数设置)ping不通后端的DB后,会将该DB的状态设置为down,后续kingshard就不会将sql语句发往该DB了。
# 7. 客户端白名单机制
有时候用户为了安全考虑,希望只只允许某几台server连接kingshard。在kingshard的配置文件中有一个参数:allow_ips,用于实现客户端白名单机制。当管理员设置了该参数,则意味着只有allow_ips指定的IP能够连接kingshard,其他IP都会被kingshard拒绝连接。如果不设置该参数,则连接kingshard的客户端不受限制。
# 8. 管理端设计和实现
kingshard的管理端口复用了工作端口,通过特定的关键字(admin)来标示。kingshard是通过对管理端特定的SQL进行词法和语义分析,将SQL语句解析为一条kingshard可以识别的命令。目前支持平滑上下线master和slave,和查看kingshard配置和后端DB状态。后续打算将web页面集成到管理端,这样用户就可以不用输入命令行操作,而是在网页上操作。大大降低用户使用kingshard的门槛。
上述各个模块都是kingshard中比较核心的模块,通过这篇文章的介绍,我想读者应该对kingshard的架构和实现有了初步的了解。很多功能的设计和实现,都是作者慢慢地摸索和实践。如果有读者对kingshard的设计或实现感兴趣或者对上述设计有不同的想法,欢迎发邮件(flikecn#126.com)给我。
# 主要功能
# 1. 基础功能
- 支持SQL读写分离。
- 支持透明的MySQL连接池,不必每次新建连接。
- 支持平滑上线DB或下线DB,前端应用无感知。
- 支持多个slave,slave之间通过权值进行负载均衡。
- 支持强制读主库。
- 支持主流语言(java,php,python,C/C++,Go)SDK的mysql的prepare特性。
- 支持到后端DB的最大连接数限制。
- 支持SQL日志及慢日志输出。
- 支持SQL黑名单机制。
- 支持客户端IP访问白名单机制,只有白名单中的IP才能访问kingshard(支持IP 段)。
- 支持字符集设置。
- 支持last_insert_id功能。
- 支持热加载配置文件,动态修改kingshard配置项(具体参考管理端命令)。
- 支持以Web API调用的方式管理kingshard。
- 支持多用户模式,不同用户之间的表是权限隔离的,互不感知。
# 2. sharding(分片)功能
- 支持按整数的hash和range分表方式。
- 支持按年、月、日维度的时间分表方式。
- 支持跨节点分表,子表可以分布在不同的节点。
- 支持跨节点的count,sum,max和min等聚合函数。
- 支持单个分表的join操作,即支持分表和另一张不分表的join操作。
- 支持跨节点的order by,group by,limit等操作。
- 支持将sql发送到特定的节点执行。
- 支持在单个节点上执行事务,不支持跨多节点的分布式事务。
- 支持非事务方式更新(insert,delete,update,replace)多个node上的子表。
# 3. 支持的操作
- 目前kingshard sharding支持insert, delete, select, update和replace语句, 所有这五类操作都支持跨子表。但写操作仅支持单node上的跨子表,select操作则可以跨node,跨子表。
# 应用场景
- mysql实例的读扩展: 解决master和slave数据不一致问题
- mysql实例的单表水平扩展: 解决单表数据量过大的问题,支持单个分表的join操作,即支持分表和另一张不分表的join操作。
# 安装kingshard
安装Go语言环境(请使用最新版),具体步骤请Google。
git clone https://github.com/flike/kingshard.git $GOPATH/src/github.com/flike/kingshard
cd src/github.com/flike/kingshard
source ./dev.sh
make
设置配置文件
# kingshard的地址和端口 addr : 0.0.0.0:9696 # 连接kingshard的用户名和密码的用户列表 user_list: - user : kingshard password : kingshard #kingshard的web API 端口 web_addr : 0.0.0.0:9797 #调用API的用户名和密码 web_user : admin web_password : admin # log级别,[debug|info|warn|error],默认是error log_level : debug # 打开SQL日志,设置为on;关闭SQL日志,设置为off log_sql : on #如果设置了该项,则只输出SQL执行时间超过slow_log_time(单位毫秒)的SQL日志,不设置则输出全部SQL日志 slow_log_time : 100 #日志文件路径,如果不配置则会输出到终端。 log_path : /Users/flike/log # sql黑名单文件路径 # 所有在该文件中的sql都会被kingshard拒绝转发 #blacklist_sql_file: /Users/flike/blacklist # 只允许下面的IP列表连接kingshard,如果不配置则对连接kingshard的IP不做限制。 allow_ips: 127.0.0.1 # kingshard使用的字符集,如果不设置该选项,则kingshard使用utf8作为默认字符集 #proxy_charset: utf8mb4 # 一个node节点表示mysql集群的一个数据分片,包括一主多从(可以不配置从库) nodes : - #node节点名字 name : node1 # 连接池中最大空闲连接数,也就是最多与后端DB建立max_conns_limit个连接 max_conns_limit : 16 # kingshard连接该node中mysql的用户名和密码,master和slave的用户名和密码必须一致 user : kingshard password : kingshard # master的地址和端口 master : 127.0.0.1:3306 # slave的地址、端口和读权重,@后面的表示该slave的读权重。可不配置slave #slave : 192.168.0.12@2,192.168.0.13@3 #kingshard在300秒内都连接不上mysql,kingshard则会下线该mysql down_after_noalive : 300 - name : node2 max_conns_limit : 16 user : kingshard password : kingshard master : 192.168.59.103:3307 slave : down_after_noalive: 100 # 各用户的分表规则 schema_list : - #schema的所属用户名 user: kingshard nodes: [node1,node2] #分表分布的node名字 nodes: [node1,node2] #所有未分表的SQL,都会发往默认node。 default: node1 shard: - #分表使用的db db : kingshard #分表名字 table: test_shard_hash #分表字段 key: id #分表分布的node nodes: [node1, node2] #分表类型 type: hash #子表个数分布,表示node1有4个子表, #node2有4个子表。 locations: [4,4] - #分表使用的db db : kingshard #分表名字 table: test_shard_range #分表字段 key: id #分表类型 type: range #分表分布的node nodes: [node1, node2] #子表个数分布,表示node1有4个子表, #node2有4个子表。 locations: [4,4] #表示每个子表包含的最大记录数,也就是说每 #个子表最多包好10000条记录。即子表1对应的id为[0,10000),子表2[10000,20000).... table_row_limit: 100001
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105运行kingshard。
./bin/kingshard -config=etc/ks.yaml