Kafka消费问题记录
Kafka消费问题记录
# 1. 消息顺序的保证
为什么需要保证消息顺序
订单有很多状态,比如:下单、支付、完成、撤销等,不可能下单的消息都没读取到,就先读取支付或撤销的消息吧,如果真的这样,数据不是会产生错乱?
如何保证消息顺序?
kafka的topic是无序的,但是一个topic包含多个partition,每个partition内部是有序的。
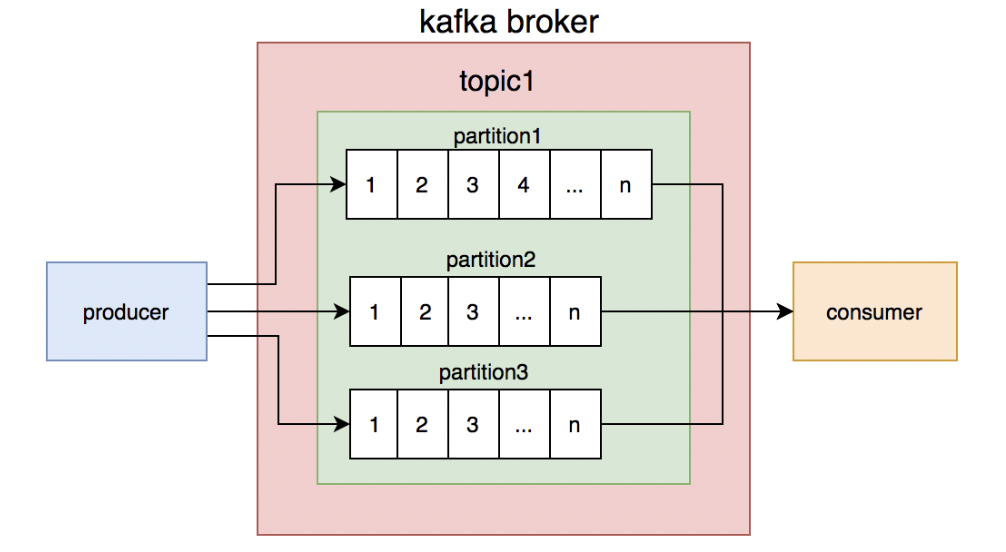
只要保证生产者写消息时,按照一定的规则写到同一个partition,不同的消费者读不同的partition的消息,就能保证生产和消费者消息的顺序。
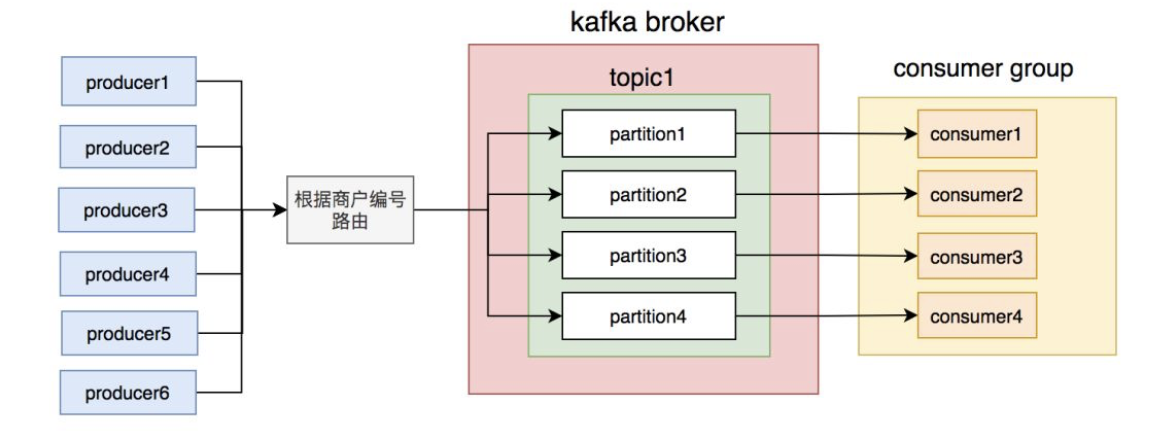
我们刚开始就是这么做的,同一个商户编号的消息写到同一个partition,topic中创建了4个partition,然后部署了4个消费者节点,构成消费者组,一个partition对应一个消费者节点。从理论上说,这套方案是能够保证消息顺序的。
# 2. 消费失败
消费端消费失败后不要commit, 以保证数据不会丢的问题, 需要消费端确认手动commit机制,保证消息准确性
# 3. 消息积压
消息的数量越来越大,导致消费者处理不过来,经常出现消息积压的情况。对于需要实时的数据来说是致命的.
# 3.1 消息体过大
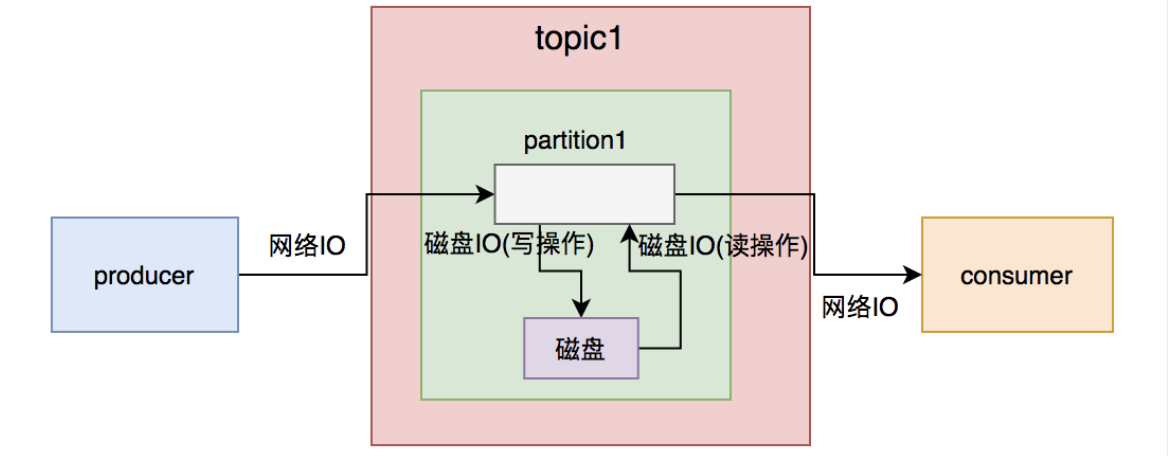
虽说kafka号称支持百万级的TPS,但从producer发送消息到broker需要一次网络IO,broker写数据到磁盘需要一次磁盘IO(写操作),consumer从broker获取消息先经过一次磁盘IO(读操作),再经过一次网络IO。
一次简单的消息从生产到消费过程,需要经过2次网络IO和2次磁盘IO。如果消息体过大,势必会增加IO的耗时,进而影响kafka生产和消费的速度。消费者速度太慢的结果,就会出现消息积压情况。
解决办法:
尽可能存入关键信息, 优化数据结构, 使消息对象尽可能简洁
# 3.2 路由规则不合理
路由规则设置不合理会导致消息到parttion不均衡, 有的 partition 消息过多,造成数据积压
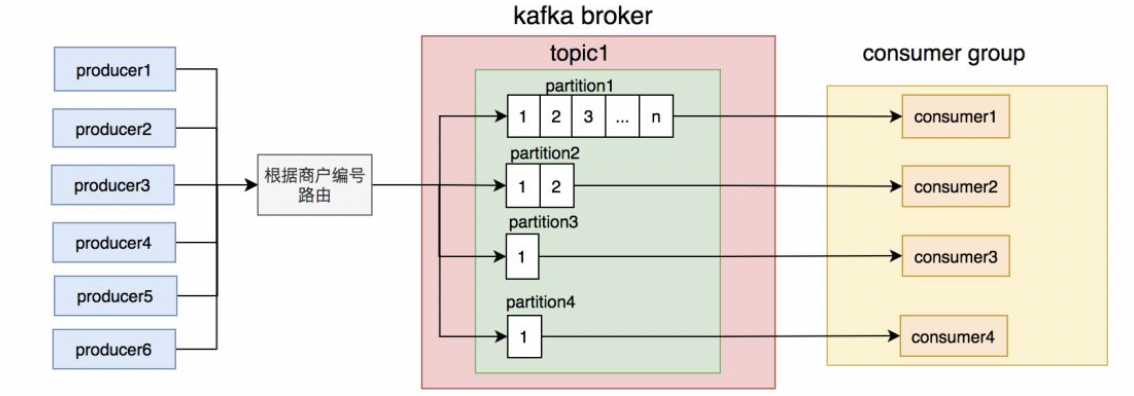
优化路由理想数据分布
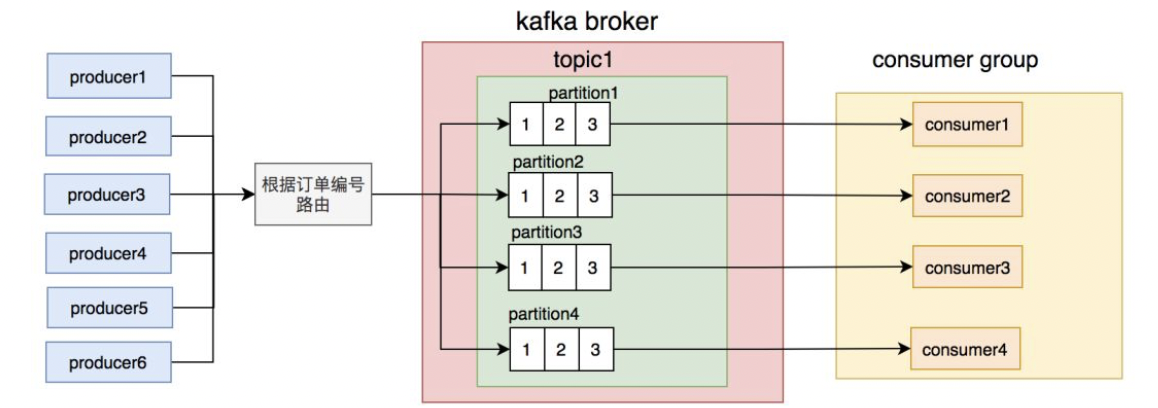
# 3.3 批量操作引起的连锁反应
批量插入到partition(税务征期或者活动促销等原因)
- 不要盲目增加消费并发数, 会导致节点崩溃, 下游系统团队多线程调用接口一定要做压测。
- 批量操作一定提前通知下游系统
- 对消息积压情况加监控。
# 3.4 表过大
- 数据表过大到时数据查询和保存耗时增加;
- 建议将多余数据归档处理, 数据表保存近期数据;
# 4. 重复消费
kafka消费消息时支持三种模式:
at most once模式 最多一次。保证每一条消息commit成功之后,再进行消费处理。消息可能会丢失,但不会重复。
at least once模式 至少一次。保证每一条消息处理成功之后,再进行commit。消息不会丢失,但可能会重复。
exactly once模式 精确传递一次。将offset作为唯一id与消息同时处理,并且保证处理的原子性。消息只会处理一次,不丢失也不会重复。但这种方式很难做到。
消费者从节点读取到数据后处理完业务再去修改偏移量 这样可以确保数据不会丢失, 但是有可能出现重复消费, 在后续修改偏移量的时候可能失败; consumer在从broker读取消息后等消费完再commit,如果consumer还没来得及消费或消费时crash,导致offset未提交,该consumer下一次读取的开始位置会跟上一次commit之后的开始位置相同,导致重复消费问题
kafka默认的模式是at least once,但这种模式可能会产生重复消费的问题,所以我们的业务逻辑必须做幂等设计。
- 可以通过将每次消费的数据的唯一标识存入Redis中,每次消费前先判断该条消息是否在Redis中,如果有则不再消费,如果没有再消费,消费完再将该条记录的唯一标识存入Redis中,并设置失效时间,防止Redis数据过多、垃圾数据问题。
- 在偏移量存入redis, 每次消费前判断redis的偏移量(双重保证,看业务接收程度 )
- 业务端保持幂等机制, 而我们的业务场景保存数据时使用了
INSERT INTO ...ON DUPLICATE KEY UPDATE语法,不存在时插入,存在时更新,是天然支持幂等性的。
# 5. 消息丢失
producer把消息发送给broker,因为网络抖动,消息没有到达broker,且开发人员无感知。
解决方案:
producer设置acks参数,消息同步到master之后返回ack信号,否则抛异常使应用程序感知到并在业务中进行重试发送。这种方式一定程度保证了消息的可靠性,producer等待broker确认信号的时延也不高。
producer把消息发送给broker-master,master接收到消息,在未将消息同步给follower之前,挂掉了,且开发人员无感知。
解决方案:
producer设置acks参数,消息同步到master且同步到所有follower之后返回ack信号,否则抛异常使应用程序感知到并在业务中进行重试发送。这样设置,在更大程度上保证了消息的可靠性,缺点是producer等待broker确认信号的时延比较高。
producer把消息发送给broker-master,master接收到消息,master未成功将消息同步给每个follower,有消息丢失风险。
解决方案:
同2.
某个broker消息尚未从内存缓冲区持久化到磁盘,就挂掉了,这种情况无法通过ack机制感知。
解决方案:
设置参数,加快消息持久化的频率,能在一定程度上减少这种情况发生的概率。但提高频率自然也会影响性能。
consumer成功拉取到了消息,consumer挂了, consumer写入失败等.
解决方案:
设置手动sync,消费成功才提交。
- 意见
- producer端确认消息是否到达集群,若有异常,进行重发。
- consumer端保障消费幂等性。
# 5.1 生产端丢消息问题解决
producer设置acks参数,消息同步到master之后返回ack信号,否则抛异常使应用程序感知到并在业务中进行重试发送。
go 生产者设置
config := sarama.NewConfig() config.Producer.RequiredAcks = sarama.WaitForAll // -11
2
# 5.2 消费端消息丢失问题解决
设置手动sync,消费成功才提交。
通常消费端丢消息都是因为Offset自动提交了,但是数据并没有插入到mysql(比如出现BUG或者进程Crash),导致下一次消费者重启后,消息漏掉了,自然数据库中也查不到。这个时候,我们可以通过手动提交解决,甚至在一些复杂场景下,还要使用二阶段提交。
package main import ( "context" "fmt" sarama "github.com/Shopify/sarama" ) type consumerGroupHandler struct { name string } func (consumerGroupHandler) Setup(_ sarama.ConsumerGroupSession) error { return nil } func (consumerGroupHandler) Cleanup(_ sarama.ConsumerGroupSession) error { return nil } func (h consumerGroupHandler) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error { i := 0 for msg := range claim.Messages() { fmt.Println(msg.Offset) sess.MarkMessage(msg, "") i++ if i%15 == 0 { sess.Commit() } } return nil } func main() { fmt.Println("consumer_test") config := sarama.NewConfig() config.Consumer.Return.Errors = false config.Version = sarama.V0_11_0_2 config.Consumer.Offsets.AutoCommit.Enable = false config.Consumer.Offsets.Initial = sarama.OffsetOldest group, err := sarama.NewConsumerGroup([]string{"192.168.1.125:9092"}, "t", config) //sarama.NewConsumerGroupFromClient() if err != nil { panic(err) } defer group.Close() for { handler := consumerGroupHandler{name: "sera"} err := group.Consume(context.Background(), []string{"test"}, handler) if err != nil { fmt.Println(err.Error()) } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# 6. 主键冲突
代码逻辑会先根据主键从表中查询订单是否存在,如果存在则更新状态,不存在才插入数据. 这种判断在并发量不大时,是有用的。但是如果在高并发的场景下,两个请求同一时刻都查到订单不存在,一个请求先插入数据,另一个请求再插入数据时就会出现主键冲突的异常。
解决办法: 加锁
数据库悲观锁:太影响性能
数据库乐观锁,基于版本号判断,一般用于更新操作,插入操作基本上不会用。
分布式锁:可以加基于redis的分布式锁,锁定订单号。
- 消费者依赖于redis,如果redis出现网络超时,服务就悲剧了。
- 加分布式锁也可能会影响消费者的消息处理速度。
使用mysql的INSERT INTO ...ON DUPLICATE KEY UPDATE语法, 推荐使用!!!!!!!!
- 先尝试把数据插入表,如果主键冲突的话那么更新字段。
INSERTINTOtable (column_list) VALUES (value_list) ON DUPLICATEKEY UPDATE c1 = v1, c2 = v2, ...;1
2
3
4
5
6
# 7. 数据库主从延迟
主从延迟会导致数据成功写入, 但是读库尚未同步数据, 导致数据异常! 该问题会存在于数据实时性较高的场景中
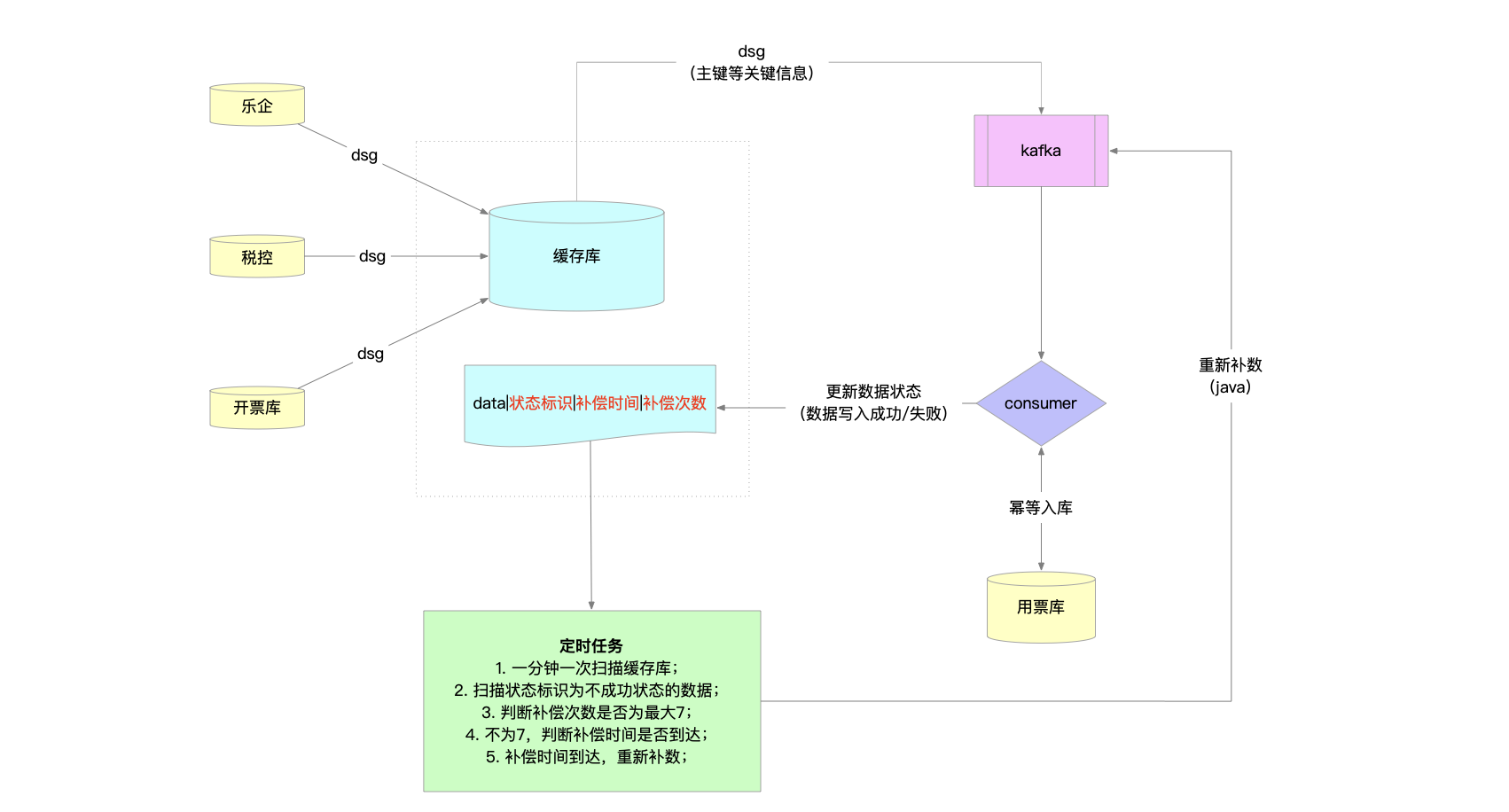
# 8. 税务场景架构设计