数据库分库分表
数据库分库分表
# 为什么要分库分表
比如你单表都几千万数据了,你确定你能抗住么?绝对不行,单表数据量太大,会极大影响你的sql执行的性能,到了后面你的sql可能就跑的很慢了。一般来说,就以我的经验来看,单表到几百万的时候,性能就会相对差一些了,你就得分表了。
分表: 就是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户id来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在200万以内。
分库: 就是你一个库一般我们经验而言,最多支撑到并发2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒1000左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
# 分库分表中间件
数据库中间件分为两类
- proxy:中间经过一层代理,需要独立部署
- client:在客户端就知道指定到那个数据库
各个中间件: cobar、TDDL、atlas、sharding-jdbc、mycat
cobar:阿里b2b团队开发和开源的,属于proxy层方案。早些年还可以用,但是最近几年都没更新了,基本没啥人用,差不多算是被抛弃的状态吧。而且不支持读写分离、存储过程、跨库join和分页等操作。
TDDL:淘宝团队开发的,属于client层方案。不支持join、多表查询等语法,就是基本的crud语法是ok,但是支持读写分离。目前使用的也不多,因为还依赖淘宝的diamond配置管理系统。
atlas:360开源的,属于proxy层方案,以前是有一些公司在用的,但是确实有一个很大的问题就是社区最新的维护都在5年前了。所以,现在用的公司基本也很少了。
kingshard是一个由Go开发高性能MySQL Proxy项目,kingshard在满足基本的读写分离的功能上,致力于简化MySQL分库分表操作;能够让DBA通过kingshard轻松平滑地实现MySQL数据库扩容。 kingshard的性能是直连MySQL性能的80%以上。线上使用kingshard,请从release页面 (opens new window)获取最新版!!
DBProxy是美团点评DBA团队针对公司内部需求,在奇虎360公司开源的Atlas做了很多改进工作,形成了新的高可靠、高可用企业级数据库中间件
其特性主要有:读写分离、负载均衡、支持分表、IP过滤、sql语句黑名单、DBA平滑下线DB、从库流量配置、动态加载配置项
项目的Github地址是https://github.com/Meituan-Dianping/DBProxy
sharding-jdbc:当当开源的,属于client层方案。确实之前用的还比较多一些,因为SQL语法支持也比较多,没有太多限制,而且目前推出到了2.0版本,支持分库分表、读写分离、分布式id生成、柔性事务(最大努力送达型事务、TCC事务)。而且确实之前使用的公司会比较多一些(这个在官网有登记使用的公司,可以看到从2017年一直到现在,是不少公司在用的),目前社区也还一直在开发和维护,还算是比较活跃,个人认为算是一个现在也可以选择的方案。
mycat:基于cobar改造的,属于proxy层方案,支持的功能非常完善,而且目前应该是非常火的而且不断流行的数据库中间件,社区很活跃,也有一些公司开始在用了。但是确实相比于sharding jdbc来说,年轻一些,经历的锤炼少一些。
现在其实建议考量的,就是sharding-jdbc和mycat,这两个都可以去考虑使用。
sharding-jdbc这种client层方案的优点在于不用部署,运维成本低,不需要代理层的二次转发请求,性能很高,但是如果遇到升级啥的需要各个系统都重新升级版本再发布,各个系统都需要耦合sharding-jdbc的依赖;
mycat这种proxy层方案的缺点在于需要部署,自己及运维一套中间件,运维成本高,但是好处在于对于各个项目是透明的,如果遇到升级之类的都是自己中间件那里搞就行了。
通常来说,这两个方案其实都可以选用,但是我个人建议中小型公司选用sharding-jdbc,client层方案轻便,而且维护成本低,不需要额外增派人手,而且中小型公司系统复杂度会低一些,项目也没那么多;
但是中大型公司最好还是选用mycat这类proxy层方案,因为可能大公司系统和项目非常多,团队很大,人员充足,那么最好是专门弄个人来研究和维护mycat,然后大量项目直接透明使用即可。
kingshard是一个由Go开发高性能MySQL Proxy项目,kingshard在满足基本的读写分离的功能上,致力于简化MySQL分库分表操作;能够让DBA通过kingshard轻松平滑地实现MySQL数据库扩容。 kingshard的性能是直连MySQL性能的80%以上。线上使用kingshard,请从release页面 (opens new window)获取最新版!!
# 垂直拆分与水平拆分
# 1. 水平拆分
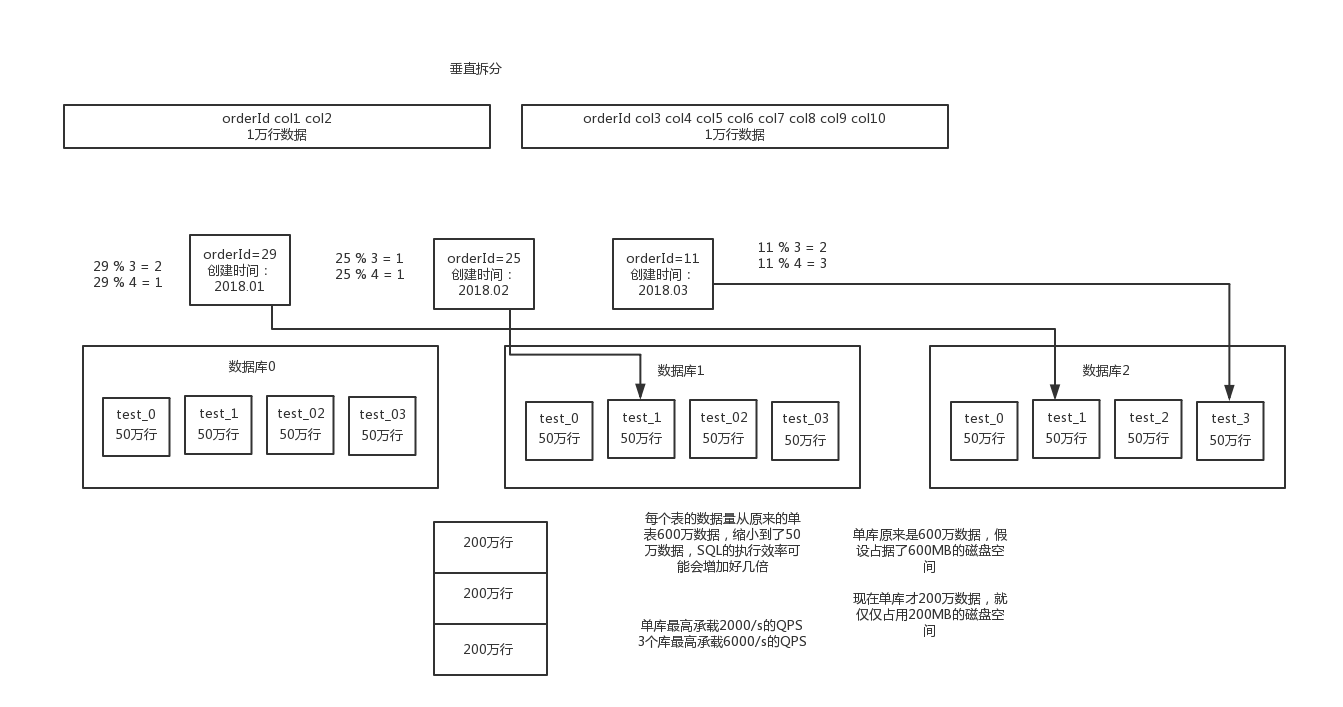
- 水平拆分的意思,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。
- 水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来抗更高的并发,还有就是用多个库的存储容量来进行扩容。
# 2. 垂直拆分
垂直拆分的意思,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。
还有表层面的拆分,就是分表,将一个表变成N个表,就是让每个表的数据量控制在一定范围内,保证SQL的性能。否则单表数据量越大,SQL性能就越差。一般是200万行左右,不要太多,但是也得看具体你怎么操作,也可能是500万,或者是100万。你的SQL越复杂,就最好让单表行数越少。
而且这儿还有两种分库分表的方式,一种是按照range来分,就是每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了;或者是按照某个字段hash一下均匀分散,这个较为常用。
range来分,好处在于说,后面扩容的时候,就很容易,因为你只要预备好,给每个月都准备一个库就可以了,到了一个新的月份的时候,自然而然,就会写新的库了;缺点,但是大部分的请求,都是访问最新的数据。实际生产用range,要看场景,你的用户不是仅仅访问最新的数据,而是均匀的访问现在的数据以及历史的数据
hash分法,好处在于说,可以平均分配没给库的数据量和请求压力;坏处在于说扩容起来比较麻烦,会有一个数据迁移的这么一个过程
# 分库分表后ID主键如何处理
# 1. UUID
好处就是本地生成,不要基于数据库来了;
缺点就是,uuid太长了,作为主键性能太差了,不适合用于主键。
适合的场景:如果你是要随机生成个什么文件名了,编号之类的,你可以用uuid,但是作为主键是不能用uuid的。
# 2. 获取系统时间戳
这个就是获取当前时间即可,但是问题是,并发很高的时候,比如一秒并发几千,会有重复的情况,这个是肯定不合适的。基本就不用考虑了。
适合的场景:一般如果用这个方案,是将当前时间跟很多其他的业务字段拼接起来,作为一个id,如果业务上你觉得可以接受,那么也是可以的。你可以将别的业务字段值跟当前时间拼接起来,组成一个全局唯一的编号,订单编号,时间戳 + 用户id + 业务含义编码
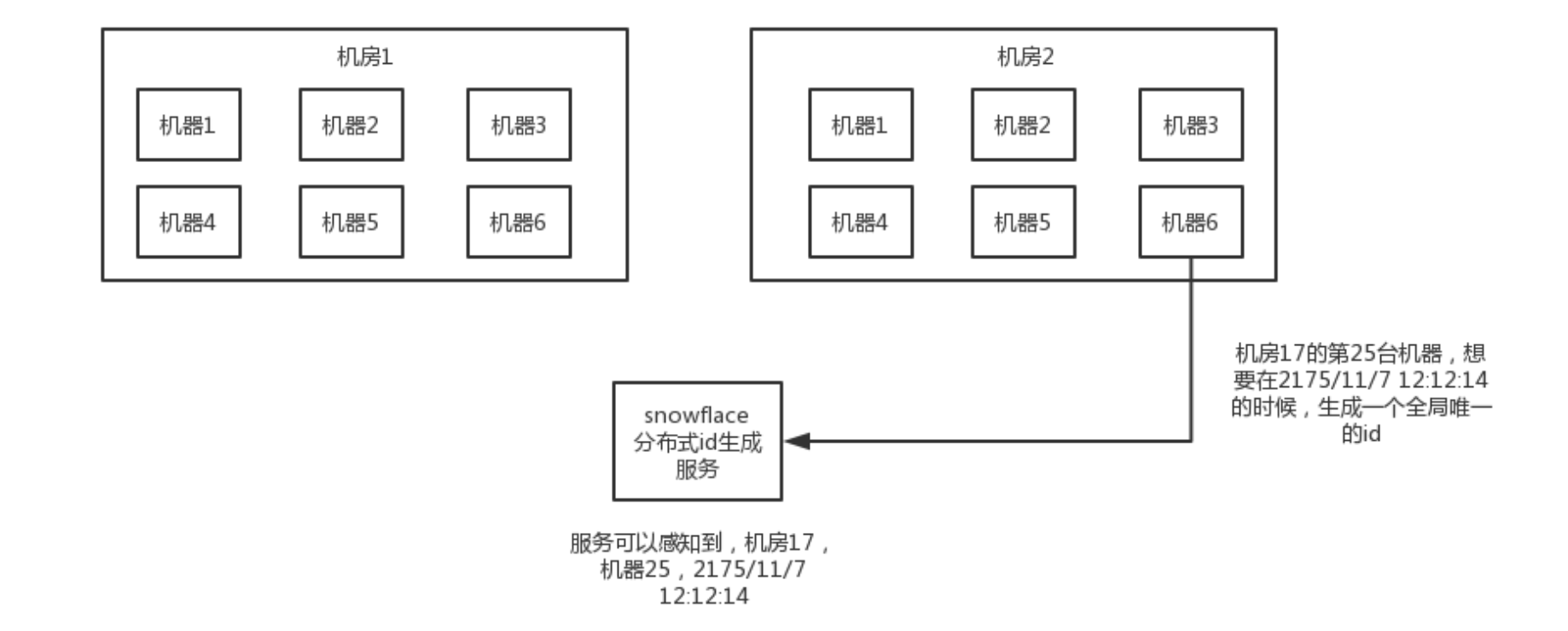
# 3. Snowflake算法(雪花算法)
twitter开源的分布式id生成算法,就是把一个64位的long型的id,1个bit是不用的,用其中的41 bit作为毫秒数,用10 bit作为工作机器id,12 bit作为序列号
1 bit:不用,为啥呢?因为二进制里第一个bit为如果是1,那么都是负数,但是我们生成的id都是正数,所以第一个bit统一都是0
41 bit:表示的是时间戳,单位是毫秒。41 bit可以表示的数字多达2^41 - 1,也就是可以标识2 ^ 41 - 1个毫秒值,换算成年就是表示69年的时间。
10 bit:记录工作机器id,代表的是这个服务最多可以部署在2^10台机器上哪,也就是1024台机器。但是10 bit里5个bit代表机房id,5个bit代表机器id。意思就是最多代表2 ^ 5个机房(32个机房),每个机房里可以代表2 ^ 5个机器(32台机器)。
12 bit:这个是用来记录同一个毫秒内产生的不同id,12 bit可以代表的最大正整数是2 ^ 12 - 1 = 4096,也就是说可以用这个12bit代表的数字来区分同一个毫秒内的4096个不同的id
64位的long型的id,64位的long -> 二进制
0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 1 1001 | 0000 00000000
比如我们来观察上面的那个,就是一个典型的二进制的64位的id,换算成10进制就是910499571847892992。