 Go异常处理
Go异常处理
# panic和recover使用场景
# 1. panic
程序报错退出,返回码是os.exit(0)
- 对于真正意外的情况,那些表示不可恢复的程序错误,例如索引越界、不可恢复的环境问题、栈溢出,我们才使用 panic。对于其他的错误情况,我们应该是期望使用 error 来进行判定。
- 速错推荐panic
# 2. recover
从 panic 恢复
tip场景: 别人写的panic 但是不符合你的场景, 你想恢复 ,使用recover
func main() {
// defer 先进后出
defer func() {
data := recover()
if data!=nil{
fmt.Println("recover",data) // recover 34
}
}()
panic("34")
// 以下代码不再执行
fmt.Println("不执行")
}
2
3
4
5
6
7
8
9
10
11
12
13
# Error vs Exception
Panic使用场景
对于真正意外的情况,那些表示不可恢复的程序错误,例如索引越界、不可恢复的环境问题、栈溢出,我们才使用 panic。对于其他的错误情况,我们应该是期望使用 error 来进行判定。
Golang error 处理方式的优点
- 简单
- 考虑失败,而不是成功(plan for failure, not success)
- 没有隐藏的控制流
- 完全交给你来控制 error
- Error are values
# Error Type (处理错误的方式)
# 1. Sentinel Error
- 预定义的特定错误,我们叫为 sentinel error,这个名字来源于计算机编程中使用一个特定值来表示不可能进行进一步处理的做法。所以对于 Go,我们使用特定的值来表示错误。 if err == ErrSomething { … } 类似的 io.EOF,更底层的 syscall.ENOENT。
结论:
- 使用 sentinel 值是最不灵活的错误处理策略,因为调用方必须使用 == 将结果与预先声明的值进行比较。当您想要提供更多的上下文时,这就出现了一个问题,因为返回一个不同的错误将破坏相等性检查。
- 不依赖检查 error.Error 的输出。不应该依赖检测 error.Error 的输出,Error 方法存在于 error 接口主要用于方便程序员使用,但不是程序(编写测试可能会依赖这个返回)。这个输出的字符串用于记录日志、输出到 stdout 等。
- 尽可能避免 sentinel errors。
# 2. Error types
Error type 是实现了 error 接口的自定义类型。例如 MyError 类型记录了文件和行号以展示发生了什么。
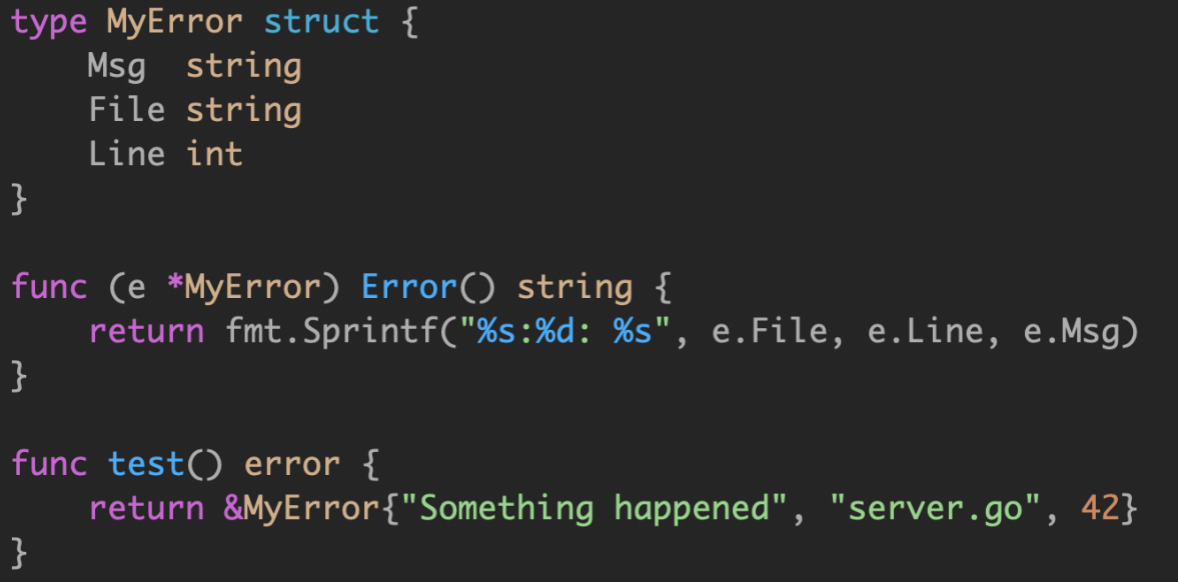
结论:
尽量避免使用 error types,虽然错误类型比 sentinel errors 更好,因为它们可以捕获关于出错的更多上下文,但是 error types 共享 error values 许多相同的问题。 因此,我的建议是避免错误类型,或者至少避免将它们作为公共 API 的一部分。
# 3. Opaque errors (推荐使用!!)
这是最灵活的错误处理策略,因为它要求代码和调用者之间的耦合最少。
- 这种风格称为不透明错误处理,因为虽然您知道发生了错误,但您没有能力看到错误的内部。作为调用者,关于操作的结果,您所知道的就是它起作用了,或者没有起作用(成功还是失败)。
- 这就是不透明错误处理的全部功能–只需返回错误而不假设其内容。
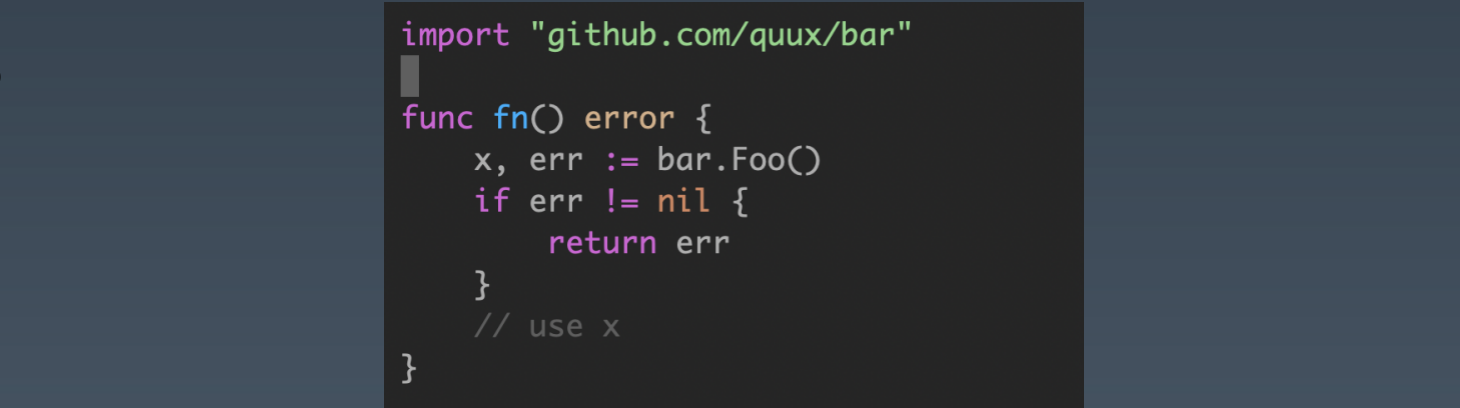
# Handling Error
读取文件多少行
func CountLines(r io.Reader) (int,error){ sc := bufio.NewScanner(r) lines := 0 for sc.Scan(){ lines++ } return lines , sc.Err() }1
2
3
4
5
6
7
8
# Errors
- err := errors.New(string) //创建errors
- err := errors.Errorf(string) //创建errors并记录堆栈信息, 通过'%v'获取
- err2 := fmt.Errorf("我错了%w", err) // 包装error
- err0 := errors.Unwrap(err2) //解包装error
- resBool := errors.Is(err2,err0) // 判断是不是同一个error
- errors.As(err2,&err3) //类型转为特定的error
# Warp Error(!!!)
使用 pkg/errors 包
我们经常发现类似的代码,在错误处理中,带了两个任务: 记录日志并且再次返回错误。
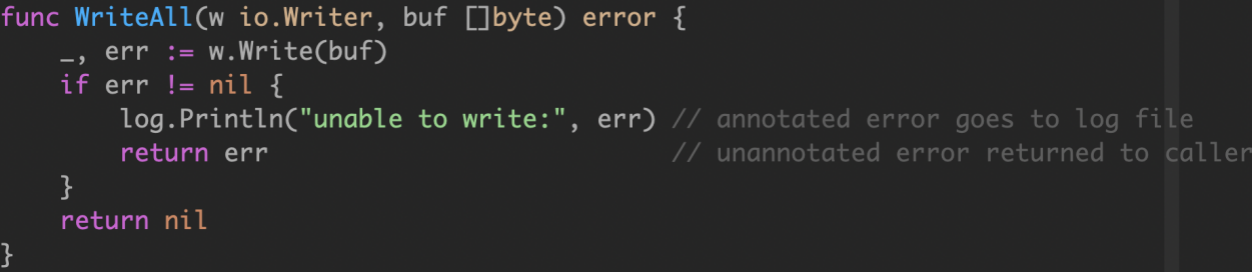
应该只处理一次错误。处理错误意味着检查错误值,并做出单一决策。
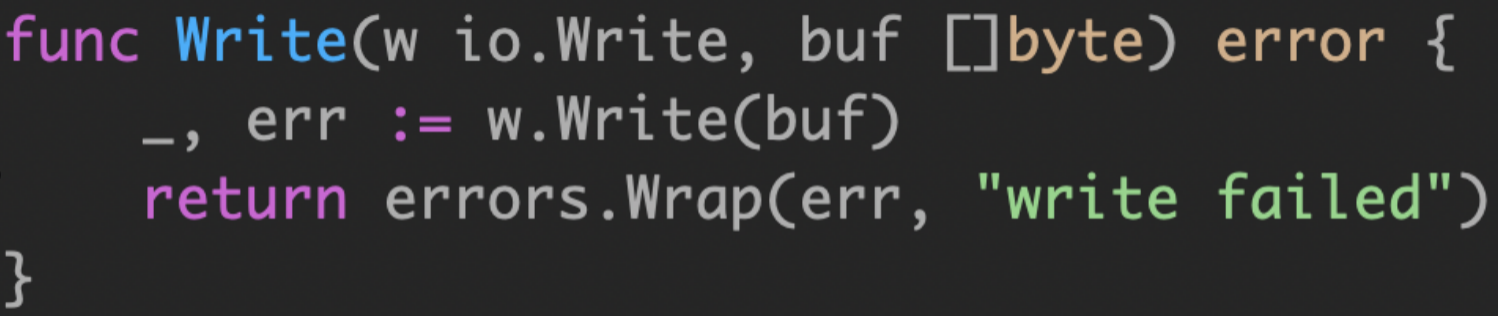
# 1. pkg/errors
package main
import (
"fmt"
"github.com/pkg/errors"
)
func main() {
r := errors.New("我错了")
r2 := errors.Wrapf(r,"我真的错了")
fmt.Println(r2.Error())
}
2
3
4
5
6
7
8
9
10
11
12
# 2. pkg/errors 使用技巧
在你的应用代码中,使用 errors.New 或者 erros.Errorf 返回错误。其中erros.Errorf 可以记录堆栈信息.
import ( "fmt" "github.com/pkg/errors" ) func main() { r := errors.New("我错了") //r := erros.Errorf("我错了") r2 := errors.Wrapf(r,"我真的错了") fmt.Println(r2.Error()) // 我真的错了: 我错了 }1
2
3
4
5
6
7
8
9
10
11如果调用其他包内的函数,通常简单的直接返回。
直接返回错误,而不是每个错误产生的地方到处打日志。
在程序的顶部或者是工作的 goroutine 顶部(请求入口),使用 %+v 把堆栈详情记录。
import ( "fmt" "github.com/pkg/errors" ) func main() { r := errors.Errorf("我错了") r2 := errors.Wrapf(r,"我真的错了") fmt.Printf("%v",r2.Error()) }1
2
3
4
5
6
7
8
9
10
# 处理error的正确姿势
# 失败的原因只有一个时,不使用error
案例:
func (self *AgentContext) CheckHostType(host_type string) error { switch host_type { case "virtual_machine": return nil case "bare_metal": return nil } return errors.New("CheckHostType ERROR:" + host_type) }1
2
3
4
5
6
7
8
9重构一下代码:
func (self *AgentContext) IsValidHostType(hostType string) bool { return hostType == "virtual_machine" || hostType == "bare_metal" }1
2
3说明:大多数情况,导致失败的原因不止一种,尤其是对I/O操作而言,用户需要了解更多的错误信息,这时的返回值类型不再是简单的bool,而是error。
# 没有失败不使用error
// 错误示例 func (self *CniParam) setTenantId() error { self.TenantId = self.PodNs return nil }1
2
3
4
5# error应放在返回值类型列表的最后
# 错误值统一定义
很多人写代码时,到处return errors.New(value),而错误value在表达同一个含义时也可能形式不同,比如“记录不存在”的错误value可能为:
- "record is not existed." - "record is not exist!" - "###record is not existed!!!"1
2
3这使得相同的错误value撒在一大片代码里,当上层函数要对特定错误value进行统一处理时,需要漫游所有下层代码,以保证错误value统一,不幸的是有时会有漏网之鱼,而且这种方式严重阻碍了错误value的重构。
于是,我们可以参考C/C++的错误码定义文件,在Golang的每个包中增加一个错误对象定义文件,如下所示:
var ERR_EOF = errors.New("EOF") var ERR_CLOSED_PIPE = errors.New("io: read/write on closed pipe") var ERR_NO_PROGRESS = errors.New("multiple Read calls return no data or error") var ERR_SHORT_BUFFER = errors.New("short buffer") var ERR_SHORT_WRITE = errors.New("short write") var ERR_UNEXPECTED_EOF = errors.New("unexpected EOF")1
2
3
4
5
6# 错误逐层传递时,层层都加日志
层层都加日志非常方便故障定位。不过存在争议!
# 当尝试几次可以避免失败时,不要立即返回错误
# 当上层函数不关心错误时,建议不返回error
对于一些资源清理相关的函数(destroy/delete/clear),如果子函数出错,打印日志即可,而无需将错误进一步反馈到上层函数,因为一般情况下,上层函数是不关心执行结果的,或者即使关心也无能为力,于是我们建议将相关函数设计为不返回error。
# 当发生错误时,不忽略有用的返回值
通常,当函数返回non-nil的error时,其他的返回值是未定义的(undefined),这些未定义的返回值应该被忽略。然而,有少部分函数在发生错误时,仍然会返回一些有用的返回值。比如,当读取文件发生错误时,Read函数会返回可以读取的字节数以及错误信息。对于这种情况,应该将读取到的字符串和错误信息一起打印出来。
# 处理异常的正确姿势
# 在程序开发阶段,坚持速错
速错推荐panic
# 在程序部署后,应恢复异常避免程序终止
# 对于不应该出现的分支,使用异常处理 panic
switch s := suit(drawCard()); s { case "Spades": // ... case "Hearts": // ... case "Diamonds": // ... case "Clubs": // ... default: panic(fmt.Sprintf("invalid suit %v", s)) }1
2
3
4
5
6
7
8
9
10
11
12# 针对入参不应该有问题的函数,使用panic设计
func MustCompile(str string) *Regexp { regexp, error := Compile(str) if error != nil { panic(`regexp: Compile(` + quote(str) + `): ` + error.Error()) } return regexp }1
2
3
4
5
6
7