 es倒排索引
es倒排索引
# 写入数据的工作原理
# 1. 过程
客户端选择一个 node 发送请求过去,这个 node 就是
coordinating node(协调节点)。coordinating node对 document 进行路由,将请求转发给对应的 node(有 primary shard)。实际的 node 上的
primary shard处理请求,然后将数据同步到replica node。coordinating node如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端。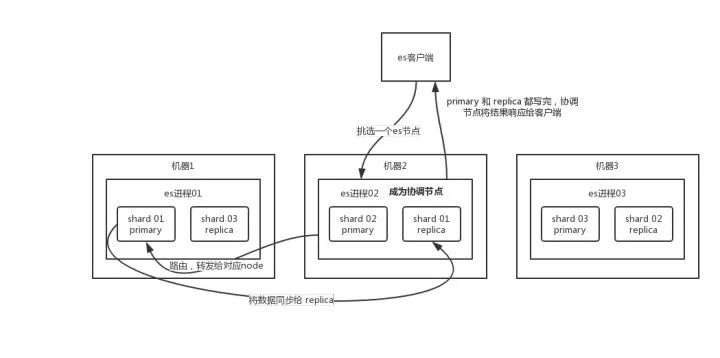
# 2. 原理
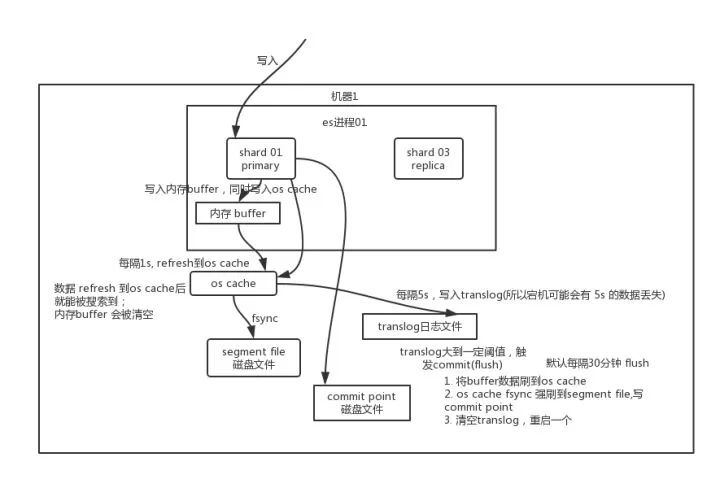
- 先写入内存 buffer,在 buffer 里的时候数据是搜索不到的;同时将数据写入 translog 日志文件。
- 如果 buffer 快满了,或者到一定时间,就会将内存 buffer 数据
refresh到一个新的segment file中 - 但是此时数据不是直接进入
segment file磁盘文件,而是先进入os cache。这个过程就是refresh。 - 每隔 1 秒钟,es 将 buffer 中的数据写入一个新的
segment file,每秒钟会产生一个新的磁盘文件segment file 这个segment file` 中就存储最近 1 秒内 buffer 中写入的数据。- 但是如果 buffer 里面此时没有数据,那当然不会执行 refresh 操作
- 如果 buffer 里面有数据,默认 1 秒钟执行一次 refresh 操作,刷入一个新的 segment file 中。
- 操作系统里面,磁盘文件其实都有一个东西,叫做
os cache,即操作系统缓存 - 就是说数据写入磁盘文件之前,会先进入
os cache,先进入操作系统级别的一个内存缓存中去。只要buffer中的数据被 refresh 操作刷入os cache中,这个数据就可以被搜索到了。
# 查询数据的工作原理
可以通过
doc id来查询,会根据doc id进行 hash,判断出来当时把doc id分配到了哪个 shard 上面去,从那个 shard 去查询。
- 写请求是写入 primary shard,然后同步给所有的 replica shard;
- 读请求可以从 primary shard 或 replica shard 读取,采用的是随机轮询算法。
搜索过程
户端发送请求到任意一个 node,成为
coordinate node。coordinate node对doc id进行哈希路由,将请求转发到对应的 node,此时会使用round-robin随机轮询算法,在primary shard以及其所有 replica 中随机选择一个,让读请求负载均衡。接收请求的 node 返回 document 给
coordinate node。coordinate node返回 document 给客户端。客户端发送请求到一个 coordinate node。 协调节点将搜索请求转发到所有的 shard 对应的 primary shard 或 replica shard,都可以。 query phase:每个 shard 将自己的搜索结果(其实就是一些 doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。 fetch phase:接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端。1
2
3
4
5
6
7
8
9
# 倒排索引
# 1. 正向索引和反向索引
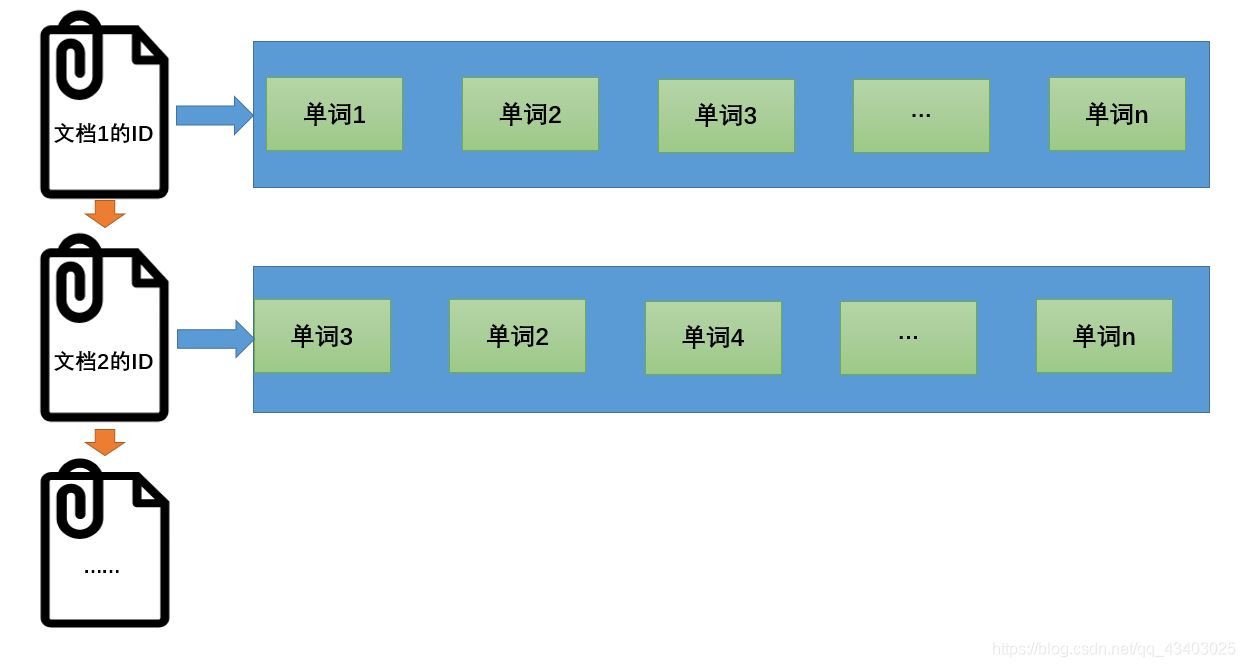
先介绍一下正向索引: 当用户发起查询时(假设查询为一个关键词),搜索引擎会扫描索引库中的所有文档,找出所有包含关键词的文档,这样依次从文档中去查找是否含有关键词的方法叫做正向索引。互联网上存在的网页(或称文档)不计其数,这样遍历的索引结构效率低下,无法满足用户需求。
正向索引结构如下: 文档1的ID→单词1的信息;单词2的信息;单词3的信息… 文档2的ID→单词3的信息;单词2的信息;单词4的信息… …
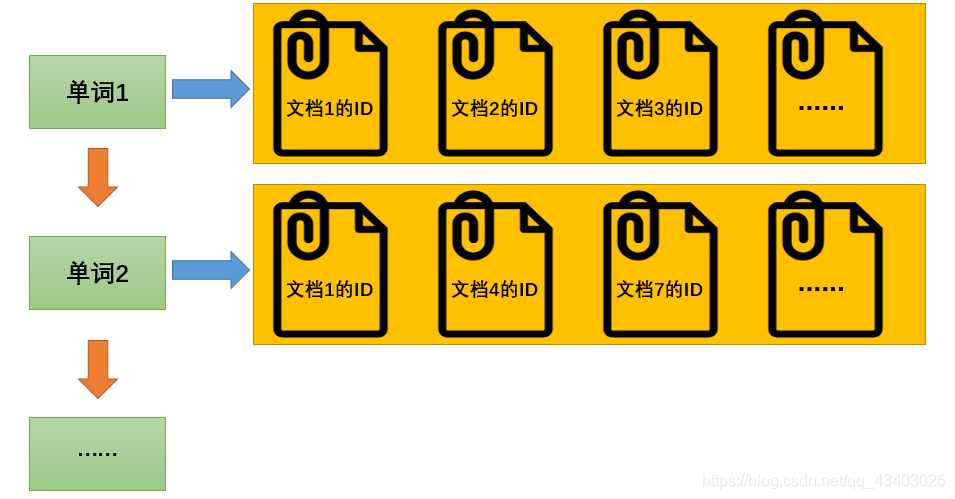
为了增加效率,搜索引擎会把正向索引变为反向索引(倒排索引)即把“文档→单词”的形式变为“单词→文档”的形式。倒排索引具体机构如下: 单词1→文档1的ID;文档2的ID;文档3的ID… 单词2→文档1的ID;文档4的ID;文档7的ID… …
# 2. 单词-文档矩阵
单词-文档矩阵是表达两者之间所具有的一种包含关系的概念模型。 现有以下几个文档:
D1:乔布斯去了中国。
D2:苹果今年仍能占据大多数触摸屏产能。
D3:苹果公司首席执行官史蒂夫·乔布斯宣布,iPad2将于3月11日在美国上市。
D4:乔布斯推动了世界,iPhone、iPad、iPad2,一款一款接连不断。
D5:乔布斯吃了一个苹果。
此时用户查询为“苹果 And (乔布斯 Or iPad2)”,表示包含单词“苹果”,同时还包含“乔布斯”或“iPad2”的其中一个。
则“单词-文档”矩阵为:
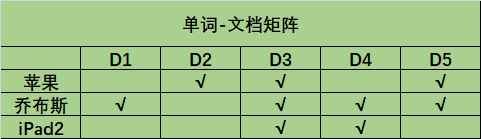
该矩阵可以从两个方向进行解读:
纵向: 表示每个单独的文档包含了哪些单词,比如D1包含了“乔布斯这个词”,D4包含了“乔布斯”和“iPad2”。
横向: 表示哪些文档包含了该单词,比如D2、D3、D5包含了“苹果”这个词。
搜索引擎的索引其实就是实现“单词-文档”矩阵的具体数据结构。可以有不同的方式来实现上述概念模型,比如“倒排索引”、“签名文件”、“后缀树”等方式,但是“倒排索引”是实现单词到文档映射关系的最佳实现方式。
# 3. 倒排索引
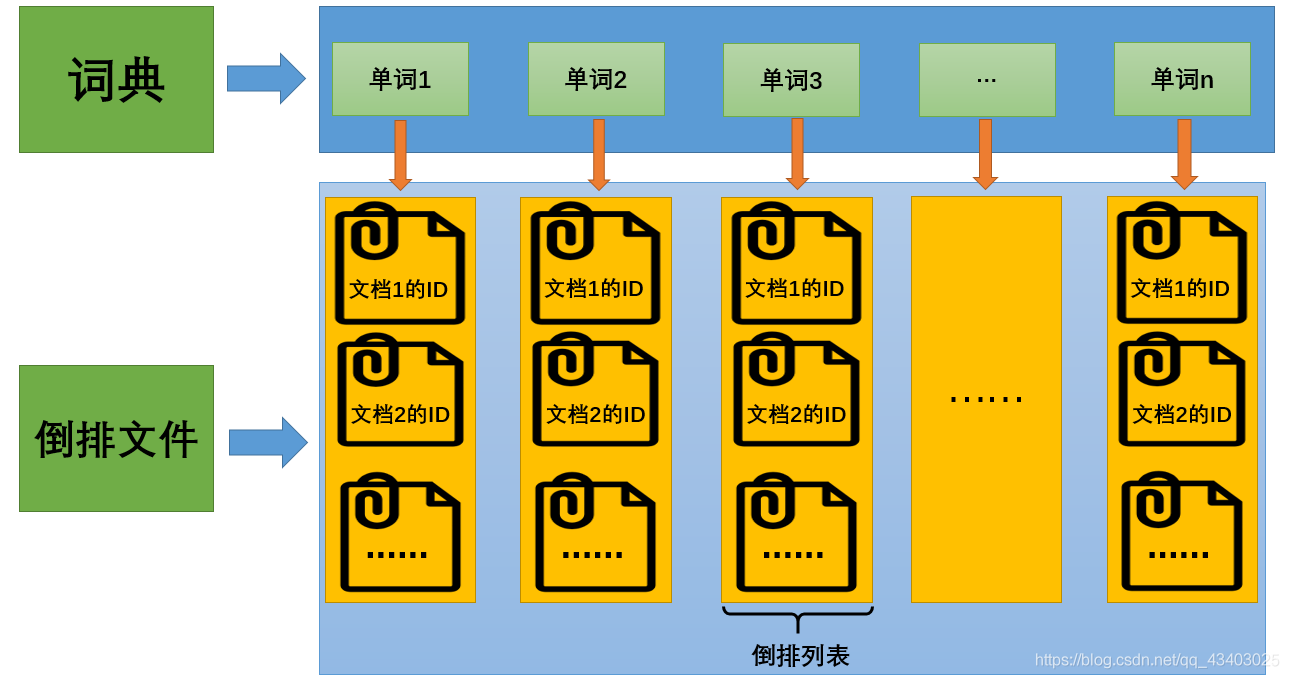
倒排索引(Inverted Index):倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
- 单词词典(Lexicon):搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
- 倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
- 倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
参考:
https://blog.csdn.net/qq_43403025/article/details/114779166
https://mp.weixin.qq.com/s/j-Rk9T_YAssy_EfTdGUs0Q
深入学习:
https://juejin.cn/post/6947984489960177677#heading-16