 kafka分区规则
kafka分区规则
# 分区规则
- topic的分区数量可以为broker的倍数,可以使每一个Partition平均分布在所有的broker中
- 分区的数量应该大于消费者数量: 多余的消费者会被闲置,会造成资源浪费
- 分区数量可以为消费者数量的倍数: 比如partition个数为40,消费者个数可以为20
- 单个broker上的partition数量不能超过2000个: 因为controller选举和controller重新选举partition leader的大量耗时
- 大量的小消息体(小于100字节)无法有效利用网络带宽,可以采用批量写入的功能
- 单partition 最大容量的建议:控制单个partition 的大小(25GB 以下)
- 副本数会影响生产/消费流量,如3副本则实际流量 = 生产流量 x 3
# 分区过多带来的问题
Zookeeper节点
集群需要在zookeeper上创建节点保存每个分区信息。分区的数量直接决定了zk集群上的节点数。节点数过多,会增加 zookeeper的压力,导致zookeeper不稳定。
分区副本复制
分区复制由独立的复制线程负责,多个分区会共用复制线程。当大量的分区同时有写人时,磁盘上文件的写入也会更分散,写人性能变差,可能出现复制跟不上,导致 ISR 频繁波动,导致系统不稳定。
Controller故障恢复
由于网络或者机器故障等原因,controller节点会自动进行切换,切换时新的controller需要从zookeeper中恢复数据。分区过多,会导致 controller 的恢复时间变长,增加了集群不可用风险。
# 通用分区预估方法
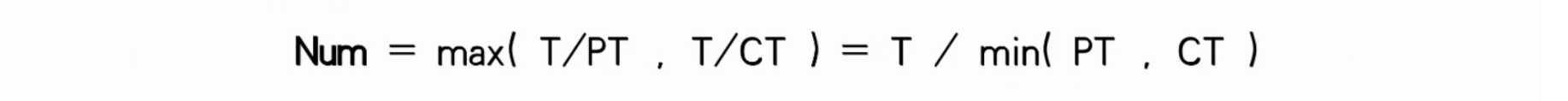
Num代表分区数量T代表目标吞吐量PT代表生产者写入单个分区的最大吞吐CT代表消费者从单个分区消费的最大吞吐。则分区数量应该等于 T/PT 和T/CT 中的较大值。
在实际情况中,生产者写入分区的最大吞吐 PT 的影响因素和批处理的规模、压缩算法、确认机制,副本数有关。消费者从单个分区消费的最大吞吐CT的影响因素和业务逻辑相关, 需要再不同的场景下测出
通常建议分区的数量一定要大于等于消费者的数量来实现最大并发, 如果消费者数量为5,则分区的数且也应该>=5 的. 但需要注意的是:过多的分区会导致生产吞吐的降低和选举耗时的增加,因此也不建议过多分区。
上次更新: 2023/04/16, 18:35:33