 函数
函数
# 3.Go中的指针
要搞明白Go语言中的指针需要先知道三个概念
- 指针地址
- 指针类型
- 指针取值
Go语言中的指针操作非常简单,我们只需要记住两个符号:&:取地址,*:根据地址取值
# 关于指针
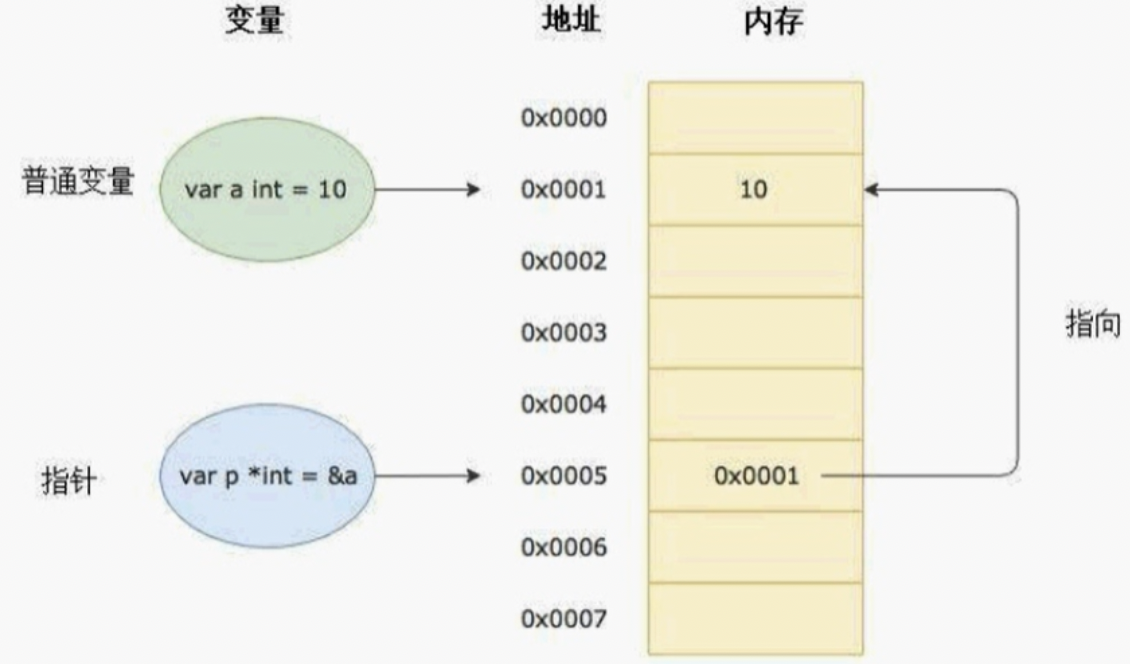
我们知道变量是用来存储数据的,变量的本质是给存储数据的内存地址起了一个好记的别名。比如我们定义了一个变量a:=10,这个时候可以直接通过a这个变量来读取内存中保存的10这个值。在计算机底层a这个变量其实对应了一个内存地址。
指针也是一个变量,但它是一种特殊的变量,它存储的数据不是一个普通的值,而是另一个变量的内存地址。
# 指针地址和指针类型
每个变量在运行时都拥有一个地址,这个地址代表变量在内存中的位置。
Go 语言中使用&字符放在变量前面对变量进行取地址操作。Go语言中的值类型(int、float、bool、string、array、struct)都有对应的指针类型,如:
*int、,*int64、*string等
取变量指针的语法如下:
ptr := &v
其中:
- v:代表被取地址的变量,类型为T
- ptr:用于接收地址的变量,ptr的类型就为*T,被称做T的指针类型。* 代表指针
举个例子:
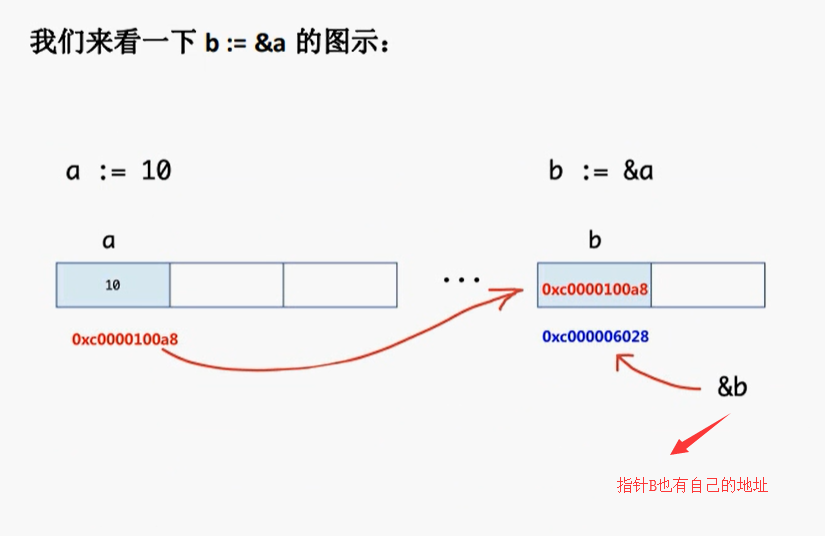
package main
func main() {
var a = 10
var b = &a
println(&a) //0xc00003df60
println(&b) //0xc00003df68
println(b) //0xc00003df60
println(*(&b)) //0xc00003df60
}
2
3
4
5
6
7
8
9
10
# 指针取值
在对普通变量进行&操作符取地址后,会获得这个变量指针,然后可以对指针使用*操作,也就是指针取值
// 指针取值
var c = 20
// 得到c的地址,赋值给d
var d = &c
// 打印d的值,也就是c的地址
fmt.Println(d)
// 取出d指针所对应的值
fmt.Println(*d)
// c对应地址的值,改成30
*d = 30
// c已经变成30了
fmt.Println(c)
2
3
4
5
6
7
8
9
10
11
12
改变内存中的值,会直接改变原来的变量值
// 这个类似于值传递
func fn4(x int) {
x = 10
}
// 这个类似于引用数据类型
func fn5(x *int) {
*x = 20
}
func main() {
x := 5
fn4(x)
fmt.Println(x)
fn5(&x)
fmt.Println(x)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
我们创建了两个方法,一个是传入局部变量,一个是传入指针类型,最后运行得到的结果
5
20
2
# new和make函数
需要注意的是,指针必须在创建内存后才可以使用,这个和 slice 和 map是一样的
// 引用数据类型map、slice等,必须使用make分配空间,才能够使用
var userInfo = make(map[string]string)
userInfo["userName"] = "zhangsan"
fmt.Println(userInfo)
var array = make([]int, 4, 4)
array[0] = 1
fmt.Println(array)
2
3
4
5
6
7
8
对于指针变量来说
// 指针变量初始化
var a *int
*a = 100
fmt.Println(a)
2
3
4
执行上面的代码会引发panic,为什么呢?在Go语言中对于引用类型的变量,我们在使用的时候不仅要声明它,还要为它分配内存空间,否则我们的值就没办法存储。而对于值类型的声明不需要分配内存空间,是因为它们在声明的时候已经默认分配好了内存空间。要分配内存,就引出来今天的new和make。Go 语言中new和make是内建的两个函数,主要用来分配内存。
这个时候,我们就需要使用new关键字来分配内存,new是一个内置的函数,它的函数签名如下:
func new(Type) *Type
其中
- Type表示类型,new函数只接受一个参数,这个参数是一个类型
- *Type表示类型指针,new函数返回一个指向该类型内存地址的指针
实际开发中new函数不太常用,使用new函数得到的是一个类型的指针,并且该指针对应的值为该类型的零值。举个例子:
// 使用new关键字创建指针
aPoint := new(int)
bPoint := new(bool)
fmt.Printf("%T \n", aPoint)
fmt.Printf("%T \n", bPoint)
fmt.Println(*aPoint)
fmt.Println(*bPoint)
2
3
4
5
6
7
本节开始的示例代码中 var a *int 只是声明了一个指针变量a但是没有初始化,指针作为引用类型需要初始化后才会拥有内存空间,才可以给它赋值。应该按照如下方式使用内置的
# make和new的区别
- 两者都是用来做内存分配的
- make只能用于slice、map以及channel的初始化,返回的还是这三个引用类型的本身
- 而new用于类型的内存分配,并且内存赌赢的值为类型的零值,返回的是指向类型的指针
# 函数
函数是基本的代码块,Go 语言最少有个 main() 函数。
函数如果使用参数,该变量可称为函数的形参。
- 形参就像定义在函数体内的局部变量。
调用函数,可以通过两种方式来传递参数:
传递类型 描述 值传递 (opens new window) 值传递是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。 引用传递 (opens new window) 引用传递是指在调用函数时将实际参数的地址传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数。 默认情况下,Go 语言使用的是值传递,即在调用过程中不会影响到实际参数。
# 匿名函数
函数也是一种类型, 可以定义一个函数类型的变量
匿名函数就是一个没有名字的函数
f1 := func(a,b int) { fmt.Println(a+b) } f1(1,2)1
2
3
4
# 值传递
传递是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
Go 语言使用的是值传递,即在调用过程中不会影响到实际参数。
package main import "fmt" func main() { /* 定义局部变量 */ var a int = 100 var b int = 200 fmt.Printf("交换前 a 的值为 : %d\n", a ) fmt.Printf("交换前 b 的值为 : %d\n", b ) /* 通过调用函数来交换值 */ swap(a, b) fmt.Printf("交换后 a 的值 : %d\n", a ) fmt.Printf("交换后 b 的值 : %d\n", b ) } /* 定义相互交换值的函数 */ func swap(x, y int) int { var temp int temp = x /* 保存 x 的值 */ x = y /* 将 y 值赋给 x */ y = temp /* 将 temp 值赋给 y*/ return temp; } /** 输出 交换前 a 的值为 : 100 交换前 b 的值为 : 200 交换后 a 的值 : 100 交换后 b 的值 : 200 */1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 引用传递
引用传递是指在调用函数时将实际参数的地址传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数。
package main import "fmt" func main() { /* 定义局部变量 */ var a int = 100 var b int= 200 fmt.Printf("交换前,a 的值 : %d\n", a ) fmt.Printf("交换前,b 的值 : %d\n", b ) /* 调用 swap() 函数 * &a 指向 a 指针,a 变量的地址 * &b 指向 b 指针,b 变量的地址 */ swap(&a, &b) fmt.Printf("交换后,a 的值 : %d\n", a ) fmt.Printf("交换后,b 的值 : %d\n", b ) } func swap(x *int, y *int) { var temp int temp = *x /* 保存 x 地址上的值 */ *x = *y /* 将 y 值赋给 x */ *y = temp /* 将 temp 值赋给 y */ } /** 交换前,a 的值 : 100 交换前,b 的值 : 200 交换后,a 的值 : 200 交换后,b 的值 : 100 */1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 传值 VS 传指针
传值会拷贝整个对象,而传指针只会拷贝指针地址,指向的对象是同一个。
传指针可以减少值的拷贝,但是会导致内存分配逃逸到堆中,增加垃圾回收(GC)的负担。在对象频繁创建和删除的场景下,传递指针导致的 GC 开销可能会严重影响性能。
一般情况下,对于需要修改原对象值,或占用内存比较大的结构体,选择传指针。对于只读的占用内存较小的结构体,直接传值能够获得更好的性能。
# 变量作用域
局部变量:在函数体内声明的变量称之为局部变量,它们的作用域只在函数体内,参数和返回值变量也是局部变量。
全局变量:在函数体外声明的变量称之为全局变量,全局变量可以在整个包甚至外部包(被导出后)使用。
可通过花括号来控制变量的作用域,花括号中的变量是单独的作用域,同名变量会覆盖外层。
a := 5 { a := 3 fmt.Println("in a = ", a) } fmt.Println("out a = ", a) /** in a = 3 out a = 5 */1
2
3
4
5
6
7
8
9
10
# defer关键字
- defer 定义的语句不会立即执行, 会在函数return之前执行
- 一般用作资源释放
- 多个defer 语句会以栈的规则执行
# 内置函数
- close:主要用来关闭 channel
- len:用来求长度,比如 string、 array、 slice、map、 channe
- cap: 获取容器的容量大小
- new:用来分配内存,主要用来分配值类型,比如iηt、 struct。返回的是指针
- make:用来分配内存,主要用来分配引用类型,比如chan、map、 slice
- append:用来追加元素到数组、slice中
- copy: 将一个slice拷贝到另一个slice中
- delete: 删除map中的键值对
- panic和 recover:用来做错误处理
# 闭包函数
闭包函数的两个必要条件: 1.嵌套函数 2. 外部引用
闭包函数的机制类似于面向对象的实例; 每一个实例对象内部的变量在实例生命周期内一直存在,只有重新创建实例时,内部变量才会被重置
package main import "fmt" func getSequence() func() int { i:=0 return func() int { i+=1 return i } } func main(){ /* nextNumber 为一个函数,函数 i 为 0 */ nextNumber := getSequence() /* 调用 nextNumber 函数,i 变量自增 1 并返回 */ fmt.Println(nextNumber()) fmt.Println(nextNumber()) fmt.Println(nextNumber()) /* 创建新的函数 nextNumber1,并查看结果 */ nextNumber1 := getSequence() fmt.Println(nextNumber1()) fmt.Println(nextNumber1()) } /** 1 2 3 1 2 */1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# defer 和闭包函数
defer 直接返回函数调用
func OutputNum(num int) { fmt.Println(num) } func main() { for i := 0; i < 5; i++ { defer OutputNum(i) // 4 3 2 1 0 } }1
2
3
4
5
6
7
8
9defer OutputNum(i) 时, 系统会将OutputNum(i) 函数压入栈, 在main函数结束之前从栈中取出并调用,但是OutputNum(i) 函数是值传递, 将i的拷贝直接入栈, 所以传递给OutputNum 的是var i int的i值.
defer 返回匿名函数
func main() { for i := 0; i < 5; i++ { defer func() { fmt.Println(i) // 5 5 5 5 5 }() } }1
2
3
4
5
6
7defer 匿名函数: 匿名函数中引用了外部变量i, 系统在把i 压入栈的时候记录的是i的内存地址, 所以多个匿名函数使用的是同一个i的内存地址
Python 闭包
道理和golang一样
# 题1 info = [] def func(i): def inner(): print(i) return inner for item in range(10): info.append(func(item)) info[0]() # 0 info[1]() # 1 info[4]() # 4 # 题2 def fun(): temp=[lambda x:x*i for i in range(4)] return temp for every in fun(): print(every(2)) # 66661
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 数组
数组是具有相同唯一类型的一组已编号且长度固定的数据项序列,这种类型可以是任意的原始类型例如整型、字符串或者自定义类型。
声明数组的时候必须声明长度或者用[...], 不然就是切片.
初始化数组:
var balance = [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
- 如果数组长度不确定,可以使用 ... 代替数组的长度,编译器会根据元素个数自行推断数组的长度:
balance := [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
- 如果设置了数组的长度,我们还可以通过指定下标来初始化元素:
// 将索引为 1 和 3 的元素初始化
balance := [5]float32{1:2.0,3:7.0}
2
# 切片(slice)
Go 语言切片是对数组的抽象。也可以被看做为"动态数组",数组的长度不可改变,切片长度可变
在做函数调用时,slice 按引用传递,array 按值传递:
切片是对数组的引用,切片本身并不包含任何元素
切片的结构包括三个部分:
- 地址: 切片的地址一般指切片中的第一个元素所指向的内存地址, 用十六进制表示;
- 长度: 切片实际存在元素的个数;
- 容量: 从切片的起始元素开始到其底层数组中最后一个元素的个数;
切片的长度和容量都不是固定的,追加元素会使切片的长度和容量都增大
切片如果是从其他数组或者切片中来的话, 切片容量增加但是所引用数组容量不变
- 切片如果是从其他数组或者切片中来的话, 当切片长度大于多引用的数组容量时; 切片容量会以 切片新容量=2*切片当前容量 的速度扩容
切片如果是从其他数组或者切片中来的话, 当前片长量大于所引用数组的容量时, 切片中的第一个元素所指向的内存地址会发生改变;
定义切片
- 声明一个未指定大小的数组来定义切片(切片不需要说明长度):
var identifier []type
- 使用 make() 函数来创建切片:
var slice1 []type = make([]type, len)
也可以简写为
slice1 := make([]type, len)
2
3
4
5
- 也可以指定容量,其中 capacity 为可选参数。
make([]T, length, capacity)
//这里 len 是数组的长度并且也是切片的初始长度。
2
特殊
a := []int{2: 1} // 声明切片索引为2的写入11
# 切片函数
len() 获取长度
cap() 获取切片容量,即最大长度
append() 往切片尾部添加一个元素
copy() 拷贝 numbers 的内容到 numbers1
/* 拷贝 numbers 的内容到 numbers1 */ copy(numbers1,numbers)1
2合并多个数组:
package main import "fmt" func main() { var arr1 = []int{1,2,3} var arr2 = []int{4,5,6} var arr3 = []int{7,8,9} var s1 = append(append(arr1, arr2...), arr3...) fmt.Printf("s1: %v\n", s1) } // s1: [1 2 3 4 5 6 7 8 9]1
2
3
4
5
6
7
8
9
10
11从切片中删除元素
package main import "fmt" func main() { sli1:=[]int{1,2,3} c:=append(sli1[0:1],sli1[2:]...) fmt.Println(c) } // [1 3]1
2
3
4
5
6
7
8
9
10
# 映射(map)
Map 是一种无序的键值对的集合。Map 最重要的一点是通过 key 来快速检索数据,key 类似于索引,指向数据的值。
Map 是无序的,这是因为 Map 是使用 hash 表来实现的。
类似python中的字典dict,
可以使用内建函数 make 也可以使用 map 关键字来定义 Map:
/* 声明变量,默认 map 是 nil */
var map_variable map[key_data_type]value_data_type
/* 使用 make 函数 */
map_variable := make(map[key_data_type]value_data_type)
2
3
4
5
- 如果不初始化 map,那么就会创建一个 nil map。nil map 不能用来存放键值对
# 删除键值对
- delete(map,key) 删除键值对
# sync.Map
map不是携程安全的,在同一时刻只能由一个携程操作map; 并发操作map时要加锁; 因为加锁会消耗性能, 所以推荐使用go1.9中的sync.Map
sync.Map的特点
- 内部通过冗余的数据结构降低加锁对性能的影响;
- 使用前无需初始化, 直接声明即可
- sync.Map不使用map中的方式进行读取和赋值等操作
package main import ( "fmt" "sync" ) func main() { var GoMap sync.Map for i := 0; i < 10000; i++ { fmt.Println(i, "\n") go writeMap(GoMap, i, i) go readMap(GoMap, i) } } func readMap(goMap sync.Map, key int) int { res, ok := goMap.Load(key) //线程安全提取 if ok == true { fmt.Println(1) return res.(int) } else { return 0 } } func writeMap(goMap sync.Map, key int, value int) { goMap.Store(key, value) }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31Sync.Map 不能使用make()方法创建
Load() 方法的第一个返回值是一个接口类型,需要将其转换为map值得类型
syny.mao为了保证安全还是会有性能损耗,单线程推荐使用map
# range
- range 关键字用于 for 循环中迭代数组(array)、切片(slice)、通道(channel)或集合(map)的元素。在数组和切片中它返回元素的索引和索引对应的值,在集合中返回 key-value 对。
| range表达式 | 第一分返回值 | 第二返回值 |
|---|---|---|
| 数组 | index | value |
| 切片 | index | value |
| 映射 | key | value |
| 通道 | value | - |
# 结构体
Go 语言中数组可以存储同一类型的数据,但在结构体中我们可以为不同项定义不同的数据类型;
lgo语言没有class类,只是个结构体struct;
结构体传参以值方式传递;
结构体注意要点:
- 同一个包内结构体名称不能重复
- 同一个结构体内成员名不能重复
- 同类型的成员可以写在同一行
- 结构体|方法名|变量名的首字母大写时可以在当前包外使用
结构体定义需要使用 type 和 struct 语句。struct 语句定义一个新的数据类型,结构体中有一个或多个成员。type 语句设定了结构体的名称。结构体的格式如下:
type struct_variable_type struct {
member definition
member definition
...
member definition
}
2
3
4
5
6
- 一旦定义了结构体类型,它就能用于变量的声明,语法格式如下:
variable_name := structure_variable_type {value1, value2...valuen}
或
variable_name := structure_variable_type { key1: value1, key2: value2..., keyn: valuen}
2
3
# 结构体指针
你可以定义指向结构体的指针类似于其他指针变量,格式如下:
var struct_pointer *Books
以上定义的指针变量可以存储结构体变量的地址。查看结构体变量地址,可以将 & 符号放置于结构体变量前:
struct_pointer = &Book1
使用结构体指针访问结构体成员,使用 "." 操作符:
struct_pointer.title
# 实例化结构体
实例化的方式:
标准实例化
new()函数实例化
取地址实例化
package main import "fmt" type Boy struct{ name string age int } func main() { // 标准实例化 var boy Boy boy.name="Evan" fmt.Println(boy.name) //Evan //new() 函数实例化 newBoy := new(Boy) newBoy.age = 1 fmt.Println(newBoy) //取地址实例化 addrBoy := &Boy{} addrBoy.name = "Evan" fmt.Println(addrBoy) //&{Evan 0} fmt.Println(addrBoy.name) //Evan }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
取值方式:
无论哪种取值方式都可以通过.的方式取值
# 初始化结构体
初始化方式
初始化成员最后一定要有逗号- 键值对初始化
- 类似map
- 列表初始化
- 必须按顺序初始化结构体中的全部成员
- 与键值对初始化方法不能混用
package main import "fmt" type Boy struct{ name string age int } func main() { // 初始化实例 boy :=Boy{ name: "evan", } boy2 :=Boy{ "bigox", 18, } fmt.Println(boy) fmt.Println(boy2) } /** {evan 0} {bigox 18} */1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25- 键值对初始化
# 结构体方法
方法: 包含了接收者的函数
结构体方法: 接收者可以使结构体类型的值后者指针
package main import "fmt" type Boy struct{ name string age int } // 指针类型接收 func (boy *Boy) changeName(){ boy.name = "bigox" } // 值类型接收 func (boy Boy) changeAge(){ boy.age = 18 } func main() { // 初始化实例 boy :=Boy{ "evan",17, } fmt.Println(boy) boy.changeName() fmt.Println(boy) boy.changeAge() fmt.Println(boy) } /** {evan 17} {bigox 17} {bigox 17} */1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 结构体内嵌
结构体内嵌可以构建面向对象编程思想中的继承关系, 结构体实例化之后可以直接访问内嵌结构体中的所有成员变量和方法
package main import "fmt" type Book struct { title string author string num int id int } type BookBorrow struct { Book borrowTime string } type BookNotBorrow struct { Book readTime string } func main() { bookBorrow := &BookBorrow{ } bookNotBorrow := &BookNotBorrow{ } fmt.Println(bookBorrow) fmt.Println(bookNotBorrow) } /** &{{ 0 0} } &{{ 0 0} } */1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34内嵌结构体实例化
package main import "fmt" type Book struct { title string author string num int id int } type BookBorrow struct { Book borrowTime string } type BookNotBorrow struct { Book readTime string } func main() { bookBorrow := &BookBorrow{ Book:Book{ title :"go", author :"Tom", num :1, id :110, }, } fmt.Println(bookBorrow) bookBorrow.author = "Jerry" fmt.Println(bookBorrow) } /** &{{go Tom 1 110} } &{{go Jerry 1 110} } */1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 匿名结构体
没有名字的结构体
无需使用type关键字, 但是创建匿名结构体的时候也要创建对象
book := struct { title string id int }{ "go", 110, } fmt.Println(book)1
2
3
4
5
6
7
8匿名函数一般可用于组织全局变量| 构建数据模板|和解析JSON使用;
经常使用匿名结构体来临时存储经过解析后的JSON数据;
# 结构体匿名字段
创建结构体时, 字敦可以只有类型, 而没有字段名, 这样的字段成为匿名字段;
type Person struct { Name string Age int `json:"age"` string // 匿名字段 }1
2
3
4
5
6