 Go中逃逸现象, 变量+堆栈
Go中逃逸现象, 变量+堆栈
# 一. 栈和堆
栈内存: 栈内存首先是一片内存区域,存储的都是局部变量,凡是定义在方法中的都是局部变量(方法外的是全局变量),for循环内部定义的也是局部变量,是先加载函数才能进行局部变量的定义,所以方法先进栈,然后再定义变量,变量有自己的作用域,一旦离开作用域,变量就会被释放。栈内存的更新速度很快,因为局部变量的生命周期都很短。但是可分配的内存有限
Go语言中的引用类型有func(函数类型),interface(接口类型),slice(切片类型),map(字典类型),channel(管道类型),*(指针类型)等。
堆内存: 存储的是数组和对象(其实数组就是对象),凡是new建立的都是在堆中,堆中存放的都是实体(对象),实体用于封装数据,而且是封装多个(实体的多个属性),如果一个数据消失,这个实体也没有消失,还可以用,所以堆是不会随时释放的,但是栈不一样,栈里存放的都是单个变量,变量被释放了,那就没有了。堆里的实体虽然不会被释放,但是会被当成垃圾通过GC回收.
# 1.原理
在main函数中
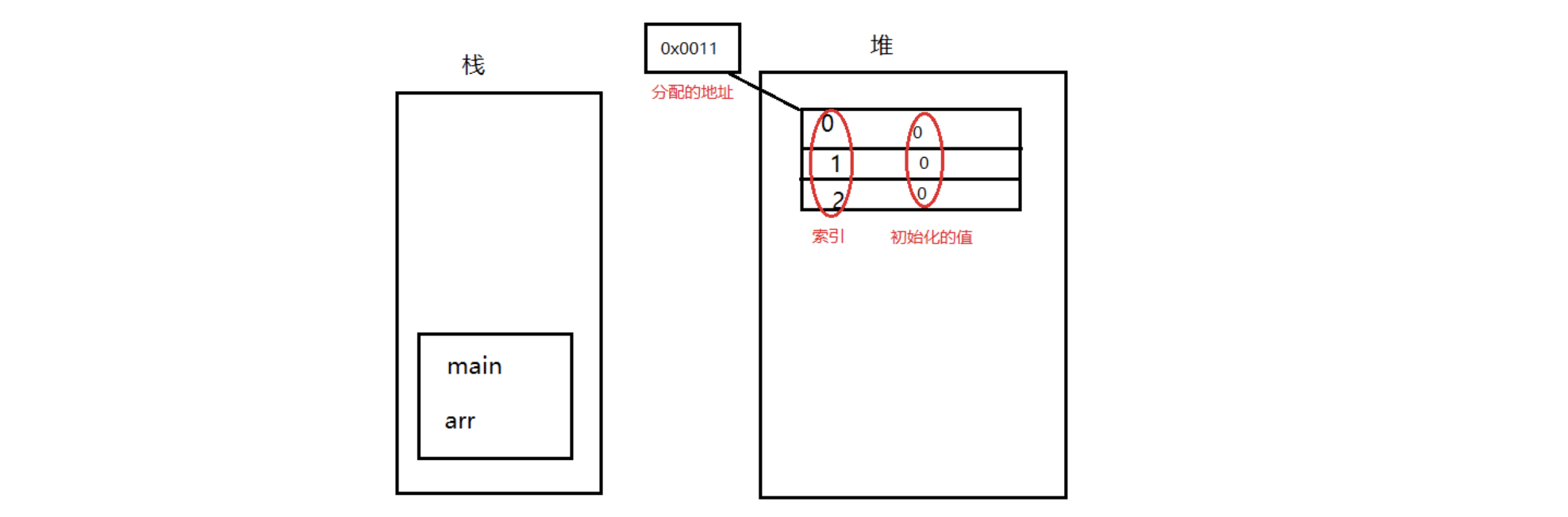
var arr = make([]int,9)的定义流程:主函数先进栈,在栈中定义一个变量arr,接下来为arr赋值,但是右边不是一个具体值,是一个实体。实体创建在堆里,在堆里首先通过new关键字开辟一个空间,内存在存储数据的时候都是通过地址来体现的,地址是一块连续的二进制,然后给这个实体分配一个内存地址。数组都是有一个索引,数组这个实体在堆内存中产生之后每一个空间都会进行默认的初始化(这是堆内存的特点,未初始化的数据是不能用的),不同的类型初始化的值不一样。所以堆和栈里就创建了变量和实体:
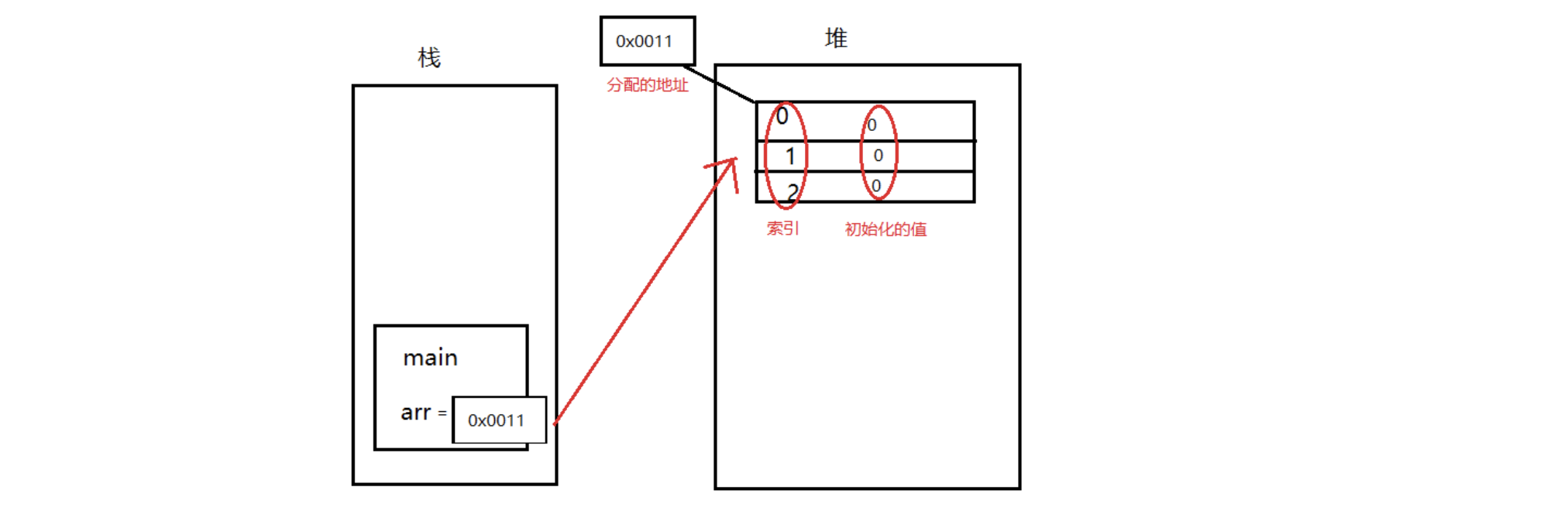
给堆分配了一个地址,把堆的地址赋给arr,arr就通过地址指向了数组。所以arr想操纵数组时,就通过地址,而不是直接把实体都赋给它。这种我们不再叫他基本数据类型,而叫引用数据类型。称为arr引用了堆内存当中的实体。(指针)
如果当int [] arr=null;arr不做任何指向,null的作用就是取消引用数据类型的指向。
# 2.区别
栈内存存储的是局部变量而堆内存存储的是实体;
栈内存的更新速度要快于堆内存,因为局部变量的生命周期很短;
栈内存存放的变量生命周期一旦结束就会被释放,而堆内存存放的实体会被垃圾回收机制不定时的回收。
# 二. make和new的区别
- 变量的声明我们可以通过var关键字,然后就可以在程序中使用。当我们不指定变量的默认值时,这些变量的默认值是他们的零值,比如int类型的零值是0,string类型的零值是
"",引用类型的零值是nil。 - 引用类型的变量,我们不光要声明它,还要为它分配内容空间
# 1. new
- new分配内存。
new只接受一个参数,这个参数是一个类型,分配好内存后,返回一个指向该类型内存地址的指针。同时请注意它同时把分配的内存置为零,也就是类型的零值。new返回的永远是类型的指针,指向分配类型的内存地址。
// 示例一
func main() {
var i *int
i=new(int)
*i=10
fmt.Println(*i) //打印10
}
2
3
4
5
6
7
8
9
// 示例2
package main
import (
"fmt"
"sync"
)
type user struct {
lock sync.Mutex
name string
age int
}
func main() {
u := new(user) //默认给u分配到内存全部为0
u.lock.Lock() //可以直接使用,因为lock为0,是开锁状态
u.name = "张三"
u.lock.Unlock()
fmt.Println(u) //&{{0 0} 张三 0}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 2. make
make也是用于内存分配的,但是和new不同。
只用于chan, map, slice 的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。
注意,因为这三种类型是引用类型,所以必须得初始化,但是不是置为零值,这个和new是不一样的。
func make(t Type, size ...IntegerType) Type1从函数声明中可以看到,返回的还是该类型。
# 3. make与new的异同
相同
- 堆空间分配
不同
- make: 只用于slice、map以及channel的初始化, 无可替代
- new: 用于类型内存分配(初始化值为0), 不常用
new不常用
所以有new这个内置函数,可以给我们分配一块内存让我们使用,但是现实的编码中,它是不常用的。我们通常都是采用短语句声明以及结构体的字面量达到我们的目的,比如:
i : =0 u := user{}1
2
make 无可替代
我们在使用slice、map以及channel的时候,还是要使用make进行初始化,然后才才可以对他们进行操作。
# 三. Golang中逃逸现象
栈(Stack)内存: 栈内存首先是一片内存区域,存储的都是局部变量,凡是定义在方法中的都是局部变量(方法外的是全局变量)
堆(heap)内存: 存储的是数组和对象(其实数组就是对象),凡是new建立的都是在堆中,堆中存放的都是实体(对象),实体用于封装数据,而且是封装多个(实体的多个属性),如果一个数据消失,这个实体也没有消失,还可以用,所以堆是不会随时释放的,但是栈不一样,栈里存放的都是单个变量,变量被释放了,那就没有了。堆里的实体虽然不会被释放,但是会被当成垃圾通过GC回收.
示例代码
package main func foo(arg_val int)(*int) { var foo_val int = 11; return &foo_val; } func main() { main_val := foo(666) println(*main_val) }1
2
3
4
5
6
7
8
9
10
11
12
13
14- 函数foo 返回了一个函数内部变量, 在c++中直接报错, 在C/C++中, 外部函数使用了子函数的局部变量, 理论来说,子函数的
foo_val的声明周期早就销毁了才对
- 函数foo 返回了一个函数内部变量, 在c++中直接报错, 在C/C++中, 外部函数使用了子函数的局部变量, 理论来说,子函数的
# 1. Golang编译器得逃逸分析
- go语言编译器会自动决定把一个变量放在栈还是放在堆,编译器会做逃逸分析(escape analysis),当发现变量的作用域没有跑出函数范围,就可以在栈上,反之则必须分配在堆。
- go语言声称这样可以释放程序员关于内存的使用限制,更多的让程序员关注于程序功能逻辑本身。
示例代码
package main func foo(arg_val int) (*int) { var foo_val1 int = 11; var foo_val2 int = 12; var foo_val3 int = 13; var foo_val4 int = 14; var foo_val5 int = 15; //此处循环是防止go编译器将foo优化成inline(内联函数) //如果是内联函数,main调用foo将是原地展开,所以foo_val1-5相当于main作用域的变量 //即使foo_val3发生逃逸,地址与其他也是连续的 for i := 0; i < 5; i++ { println(&arg_val, &foo_val1, &foo_val2, &foo_val3, &foo_val4, &foo_val5) } //返回foo_val3给main函数 return &foo_val3; } func main() { main_val := foo(666) println(*main_val, main_val) } /* 输出结果 $ go run pro_2.go 0xc000030758 0xc000030738 0xc000030730 0xc000082000 0xc000030728 0xc000030720 0xc000030758 0xc000030738 0xc000030730 0xc000082000 0xc000030728 0xc000030720 0xc000030758 0xc000030738 0xc000030730 0xc000082000 0xc000030728 0xc000030720 0xc000030758 0xc000030738 0xc000030730 0xc000082000 0xc000030728 0xc000030720 0xc000030758 0xc000030738 0xc000030730 0xc000082000 0xc000030728 0xc000030720 13 0xc000082000 */1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37我们能看到
foo_val3是返回给main的局部变量, 其中他的地址应该是0xc000082000,很明显与其他的foo_val1、2、3、4不是连续的.foo_val3是被runtime.newobject()在堆空间开辟的, 而不是像其他几个是基于地址偏移的开辟的栈空间.
# 2. 逃逸规则
我们其实都知道一个普遍的规则,就是如果变量需要使用堆空间,那么他就应该进行逃逸。但是实际上Golang并不仅仅把逃逸的规则如此泛泛。Golang会有很多场景具备出现逃逸的现象。
**一般我们给一个引用类对象中的引用类成员进行赋值,可能出现逃逸现象。**可以理解为访问一个引用对象实际上底层就是通过一个指针来间接的访问了,但如果再访问里面的引用成员就会有第二次间接访问,这样操作这部分对象的话,极大可能会出现逃逸的现象。
Go语言中的引用类型有func(函数类型),interface(接口类型),slice(切片类型),map(字典类型),channel(管道类型),*(指针类型)等。
- 指针逃逸: 指针逃逸应该是最容易理解的一种情况了,即在函数中创建了一个对象,返回了这个对象的指针。这种情况下,函数虽然退出了,但是因为指针的存在,对象的内存不能随着函数结束而回收,因此只能分配在堆上。
- **interface{} 动态类型逃逸:**空接口即
interface{}可以表示任意的类型,如果函数参数为interface{},编译期间很难确定其参数的具体类型,也会发生逃逸。 - 栈空间不足: 操作系统对内核线程使用的栈空间是有大小限制的,64 位系统上通常是 8 MB。可以使用
ulimit -a命令查看机器上栈允许占用的内存的大小。对于 Go 语言来说,运行时(runtime) 尝试在 goroutine 需要的时候动态地分配栈空间,goroutine 的初始栈大小为 2 KB。当 goroutine 被调度时,会绑定内核线程执行,栈空间大小也不会超过操作系统的限制。 - **闭包:**闭包让你可以在一个内层函数中访问到其外层函数的作用域。变量 n 占用的内存不能随着函数的退出而回收,因此将会逃逸到堆上。
- 发送指针的指针或值包含了指针到channel 中,由于在编译阶段无法确定其作用域与传递的路径,所以一般都会逃逸到堆上分配。
- slice 由于 append 操作超出其容量,因此会导致 slice 重新分配。这种情况下,由于在编译时 slice 的初始大小的已知情况下,将会在栈上分配。如果 slice 的底层存储必须基于仅在运行时数据进行扩展,则它将分配在堆上。
# 2.1 逃逸场景1 (interface{} 逃逸)
[]interface{}数据类型,通过[]赋值必定会出现逃逸。
package main
func main() {
data := []interface{}{100, 200}
data[0] = 100
}
2
3
4
5
6
我们通过编译看看逃逸结果
aceld:test ldb$ go tool compile -m 1.go
1.go:3:6: can inline main
1.go:4:23: []interface {}{...} does not escape
1.go:4:24: 100 does not escape
1.go:4:29: 200 does not escape
1.go:6:10: 100 escapes to heap
2
3
4
5
6
7
我们能看到,data[0] = 100 发生了逃逸现象。
# 2.2 逃逸场景2 (interface{} 逃逸)
map[string]interface{}类型尝试通过赋值,必定会出现逃逸。
package main
func main() {
data := make(map[string]interface{})
data["key"] = 200
}
2
3
4
5
6
我们通过编译看看逃逸结果
aceld:test ldb$ go tool compile -m 2.go
2.go:3:6: can inline main
2.go:4:14: make(map[string]interface {}) does not escape
2.go:6:14: 200 escapes to heap
2
3
4
我们能看到,data["key"] = 200 发生了逃逸。
# 2.3 逃逸场景3 (interface{} 逃逸)
map[interface{}]interface{}类型尝试通过赋值,会导致key和value的赋值,出现逃逸。
package main
func main() {
data := make(map[interface{}]interface{})
data[100] = 200
}
2
3
4
5
6
我们通过编译看看逃逸结果
aceld:test ldb$ go tool compile -m 3.go
3.go:3:6: can inline main
3.go:4:14: make(map[interface {}]interface {}) does not escape
3.go:6:6: 100 escapes to heap
3.go:6:12: 200 escapes to heap
2
3
4
5
我们能看到,data[100] = 200 中,100和200均发生了逃逸。
# 2.4 逃逸场景4
map[string][]string数据类型,赋值会发生[]string发生逃逸。
package main
func main() {
data := make(map[string][]string)
data["key"] = []string{"value"}
}
2
3
4
5
6
我们通过编译看看逃逸结果
aceld:test ldb$ go tool compile -m 4.go
4.go:3:6: can inline main
4.go:4:14: make(map[string][]string) does not escape
4.go:6:24: []string{...} escapes to heap
2
3
4
我们能看到,[]string{...}切片发生了逃逸。
# 2.5 逃逸场景5
[]*int数据类型,赋值的右值会发生逃逸现象。
package main
func main() {
a := 10
data := []*int{nil}
data[0] = &a
}
2
3
4
5
6
7
我们通过编译看看逃逸结果
aceld:test ldb$ go tool compile -m 5.go
5.go:3:6: can inline main
5.go:4:2: moved to heap: ash
5.go:6:16: []*int{...} does not escape
2
3
4
其中 moved to heap: a,最终将变量a 移动到了堆上。
# 2.6 逃逸场景6
func(*int)函数类型,进行函数赋值,会使传递的形参出现逃逸现象。
package main
import "fmt"
func foo(a *int) {
return
}
func main() {
data := 10
f := foo
f(&data)
fmt.Println(data)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
我们通过编译看看逃逸结果
aceld:test ldb$ go tool compile -m 6.go
6.go:5:6: can inline foo
6.go:12:3: inlining call to foo
6.go:14:13: inlining call to fmt.Println
6.go:5:10: a does not escape
6.go:14:13: data escapes to heap
6.go:14:13: []interface {}{...} does not escape
:1: .this does not escape
2
3
4
5
6
7
8
我们会看到data已经被逃逸到堆上。
# 2.7 逃逸场景7
func([]string): 函数类型,进行[]string{"value"}赋值,会使传递的参数出现逃逸现象。
package main
import "fmt"
func foo(a []string) {
return
}
func main() {
s := []string{"aceld"}
foo(s)
fmt.Println(s)
}
2
3
4
5
6
7
8
9
10
11
12
13
我们通过编译看看逃逸结果
aceld:test ldb$ go tool compile -m 7.go
7.go:5:6: can inline foo
7.go:11:5: inlining call to foo
7.go:13:13: inlining call to fmt.Println
7.go:5:10: a does not escape
7.go:10:15: []string{...} escapes to heap
7.go:13:13: s escapes to heap
7.go:13:13: []interface {}{...} does not escape
:1: .this does not escape
2
3
4
5
6
7
8
9
我们看到 s escapes to heap,s被逃逸到堆上。
# 2.8 逃逸场景8
chan []string数据类型,想当前channel中传输[]string{"value"}会发生逃逸现象。
package main
func main() {
ch := make(chan []string)
s := []string{"aceld"}
go func() {
ch <- s
}()
}
2
3
4
5
6
7
8
9
10
11
我们通过编译看看逃逸结果
aceld:test ldb$ go tool compile -m 8.go
8.go:8:5: can inline main.func1
8.go:6:15: []string{...} escapes to heap
8.go:8:5: func literal escapes to heap
2
3
4
我们看到[]string{...} escapes to heap, s被逃逸到堆上。
# 四. 内存溢出
# 1. 什么情况下内存会泄露
- go 中的内存泄漏一般都是 goroutine 泄漏,就是 goroutine 没有被关闭,或者没有添加超时控制,让 goroutine 一直处于阻塞状态,不能被 GC。
如果 goroutine 在执行时被阻塞而无法退出,就会导致 goroutine 的内存泄漏,一个 goroutine 的最低栈大小为 2KB,在高并发的场景下,对内存的消耗也是非常恐怖的。
互斥锁未释放或者造成死锁会造成内存泄漏
time.Ticker 是每隔指定的时间就会向通道内写数据。作为循环触发器,必须调用 stop 方法才会停止,从而被 GC 掉,否则会一直占用内存空间。
字符串的截取引发临时性的内存泄漏
func main() { var str0 = "12345678901234567890" str1 := str0[:10] }1
2
3
4切片截取引起子切片内存泄漏
func main() { var s0 = []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} s1 := s0[:3] }1
2
3
4函数数组传参引发内存泄漏
- 【如果我们在函数传参的时候用到了数组传参,且这个数组够大(我们假设数组大小为 100 万,64 位机上消耗的内存约为 800w 字节,即 8MB 内存),或者该函数短时间内被调用 N 次,那么可想而知,会消耗大量内存,对性能产生极大的影响,如果短时间内分配大量内存,而又来不及 GC,那么就会产生临时性的内存泄漏,对于高并发场景相当可怕。】
# 2. 怎么定位排查内存泄漏问题
- 一般通过 pprof 是 Go 的性能分析工具,在程序运行过程中,可以记录程序的运行信息,可以是 CPU 使用情况、内存使用情况、goroutine 运行情况等,当需要性能调优或者定位 Bug 时候,这些记录的信息是相当重要。
# 五. 结论
- Golang中一个函数内局部变量,不管是不是动态new出来的,它会被分配在堆还是栈,是由编译器做逃逸分析之后做出的决定。
- go语言不希望程序员关心这些事!