 redis缓存穿透、缓存雪崩、缓存击穿
redis缓存穿透、缓存雪崩、缓存击穿
# Redis缓存穿透、缓存雪崩、缓存击穿
# 1. 缓存穿透
缓存穿透,是指查询一个数据库一定不存在的数据。正常的使用缓存流程大致是,数据查询先进行缓存查询,如果key不存在或者key已经过期,再对数据库进行查询,并把查询到的对象,放进缓存。如果数据库查询对象为空,则不放进缓存。
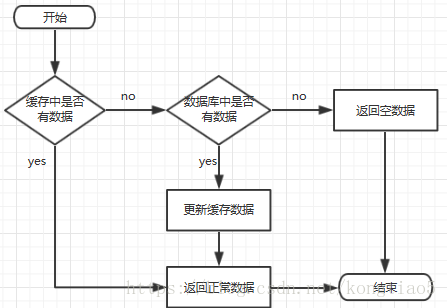
代码流程
- 参数传入对象主键ID
- 根据key从缓存中获取对象
- 如果对象不为空,直接返回
- 如果对象为空,进行数据库查询
- 如果从数据库查询出的对象不为空,则放入缓存(设定过期时间)
- 在缓存层上层加入一个布隆过滤器
- 针对这种情况,可以在Redis前加上布隆过滤器,预先把数据库中的数据加入到布隆过滤器中,因为布隆过滤器的底层数据结构是一个二进制向量,所以占用的空间并不是很大。在查询Redis之前先通过布隆过滤器判断是否存在,如果不存在就直接返回,如果存在的话,按照原来的流程还是查询Redis,Redis不存在则查询DB。
- 这里主要利用的是布隆过滤器判断结果是不存在的话就一定不存在这一个特点,但是由于布隆过滤器有一定的误判,所以并不能说完全解决缓存穿透,但是能很大程度缓解缓存穿透的问题。
想象一下这个情况,如果传入的参数为-1,会是怎么样?这个-1,就是一定不存在的对象。就会每次都去查询数据库,而每次查询都是空,每次又都不会进行缓存。假如有恶意攻击,就可以利用这个漏洞,对数据库造成压力,甚至压垮数据库。即便是采用UUID,也是很容易找到一个不存在的KEY,进行攻击。
在工作中,可以采用缓存空值的方式,也就是【代码流程】中第5步,如果从数据库查询的对象为空,也放入缓存,只是设定的缓存过期时间较短,比如设置为60秒。
# 解决办法
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
- 缓存数据为空的key; 比如设为key_null
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。
# 2. 缓存雪崩
缓存雪崩,是指在某一个时间段,缓存集中过期失效。或者缓存宕机!
产生雪崩的原因之一,比如在写本文的时候,马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。
电商项目,一般是采取不同分类商品,缓存不同周期。在同一分类中的商品,加上一个随机因子。这样能尽可能分散缓存过期时间,而且,热门类目的商品缓存时间长一些,冷门类目的商品缓存时间短一些,也能节省缓存服务的资源。
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,那么那个时候数据库能顶住压力,这个时候,数据库也是可以顶住压力的。无非就是对数据库产生周期性的压力而已。而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮。
# 解决办法
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
- 设置热点数据永远不过期。
- 集群模式,或者哨兵高可用模式
# 3. 缓存击穿
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
小编在做电商项目的时候,把这货就成为“爆款”。
其实,大多数情况下这种爆款很难对数据库服务器造成压垮性的压力。达到这个级别的公司没有几家的。所以,务实主义的小编,对主打商品都是早早的做好了准备,让缓存永不过期。即便某些商品自己发酵成了爆款,也是直接设为永不过期就好了。
# 解决办法
- 使用singleflight
- 设置热点数据永远不过期
- **接口限流与熔断,降级。**重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些 服务 不可用时候,进行熔断,失败快速返回机制。