 redis分布式锁
redis分布式锁
# 普通redis分布式锁
SET 命令有个 NX 参数可以实现「key不存在才插入」,可以用它来实现分布式锁:
如果 key 不存在,则显示插入成功,可以用来表示加锁成功;
如果 key 存在,则会显示插入失败,可以用来表示加锁失败。
一般而言,还会对分布式锁加上过期时间,分布式锁的命令如下:
SET lock_key unique_value NX PX 100001lock_key就是 key 键;unique_value是客户端生成的唯一的标识;NX代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;PX10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。
而解锁的过程就是将 lock_key 键删除,但不能乱删,要保证执行操作的客户端就是加锁的客户端。所以,解锁的时候,我们要先判断锁的 unique_value 是否为加锁客户端,是的话,才将 lock_key 键删除。
可以看到,解锁是有两个操作,这时就需要 Lua 脚本来保证解锁的原子性,因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,保证了锁释放操作的原子性。
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放 if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end1
2
3
4
5
6- 这样一来,就通过使用 SET 命令和 Lua 脚本在 Redis 单节点上完成了分布式锁的加锁和解锁。
# RedLock
redlock 也是分布式缓存的一种官方解决方案
# 1. 为什么需要RedLock
因为普通的分布式锁算法在加锁时它的KEY只会存在于某一个Redis Master实例以及它的slave上(假如有slave的话, 即使cluster集群模式,也是一样的。因为一个KEY只会属于一个slot,一个slot只会属于一个Redis节点),而Redis又不是基于CP模型的。那么就会有很大概率存在锁丢失的情况。以如下场景为例:
线程T1在M1中加锁成功。
M1出现故障,但是由于主从同步延迟问题,加锁的KEY并没有同步到S1上。
S1升级为Master节点。
另一个线程T2在S1上也加锁成功,从而导致线程T1和T2都获取到了分布式锁。
RedLock方法就是根除普通基于Redis分布式锁而生的(无论是主从模式、sentinel模式还是cluster模式)!官方把RedLock方法当作使用Redis实现分布式锁的规范算法,并认为这种实现比普通的单实例或者基于Redis Cluster的实现更安全。
# 2. RedLock 实现流程
在Redis的分布式环境中,我们假设有N个Redis Master。这些节点完全互相独立,不存在主从复制或者其他集群协调机制(这句话非常重要,如果没有理解这句话,也就无法理解RedLock。并且由这句话我们可以得出,RedLock依赖的环境不能是一个由N主N从组成的Cluster集群模式,因为Cluster模式下的各个Master并不完全独立,而是存在Gossip协调机制的)。
假设有3个完全相互独立的Redis Master单机节点,所以我们需要在3台机器上面运行这些实例
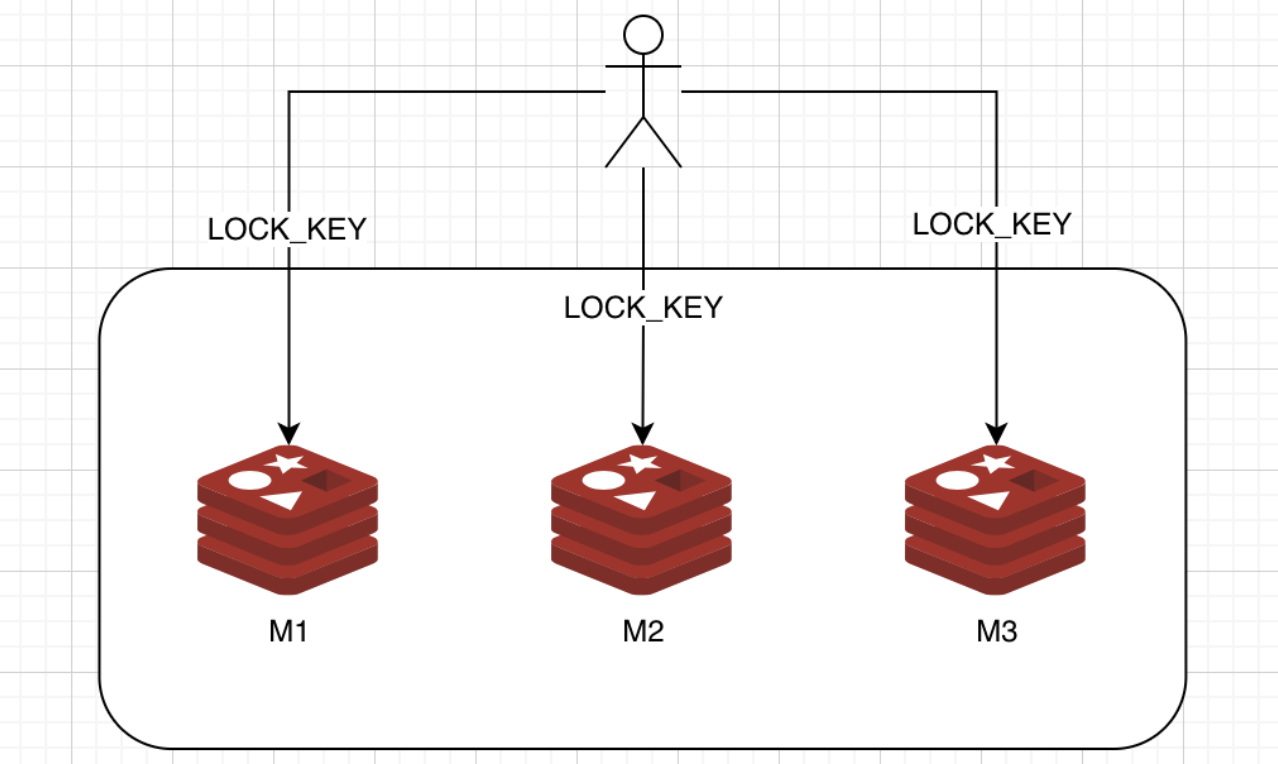
- 获取当前Unix时间,以毫秒为单位。
- 依次尝试从N个Master实例使用相同的key和随机值获取锁(假设这个key是LOCK_KEY)。当向Redis设置锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间。例如你的锁自动失效时间为10秒,则超时时间应该在5-50毫秒之间。这样可以避免服务器端Redis已经挂掉的情况下,客户端还在死死地等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试另外一个Redis实例。
- 客户端使用当前时间减去开始获取锁时间(步骤1记录的时间)就得到获取锁使用的时间。当且仅当从大多数的Redis节点都取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功。
- 如果取到了锁,key的真正有效时间等于有效时间减去获取锁所使用的时间(步骤3计算的结果)。
- 如果因为某些原因,获取锁失败(没有在至少N/2+1个Redis实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁(即便某些Redis实例根本就没有加锁成功)。