Mysql读写分离
Mysql读写分离
# 如何实现mysql的读写分离
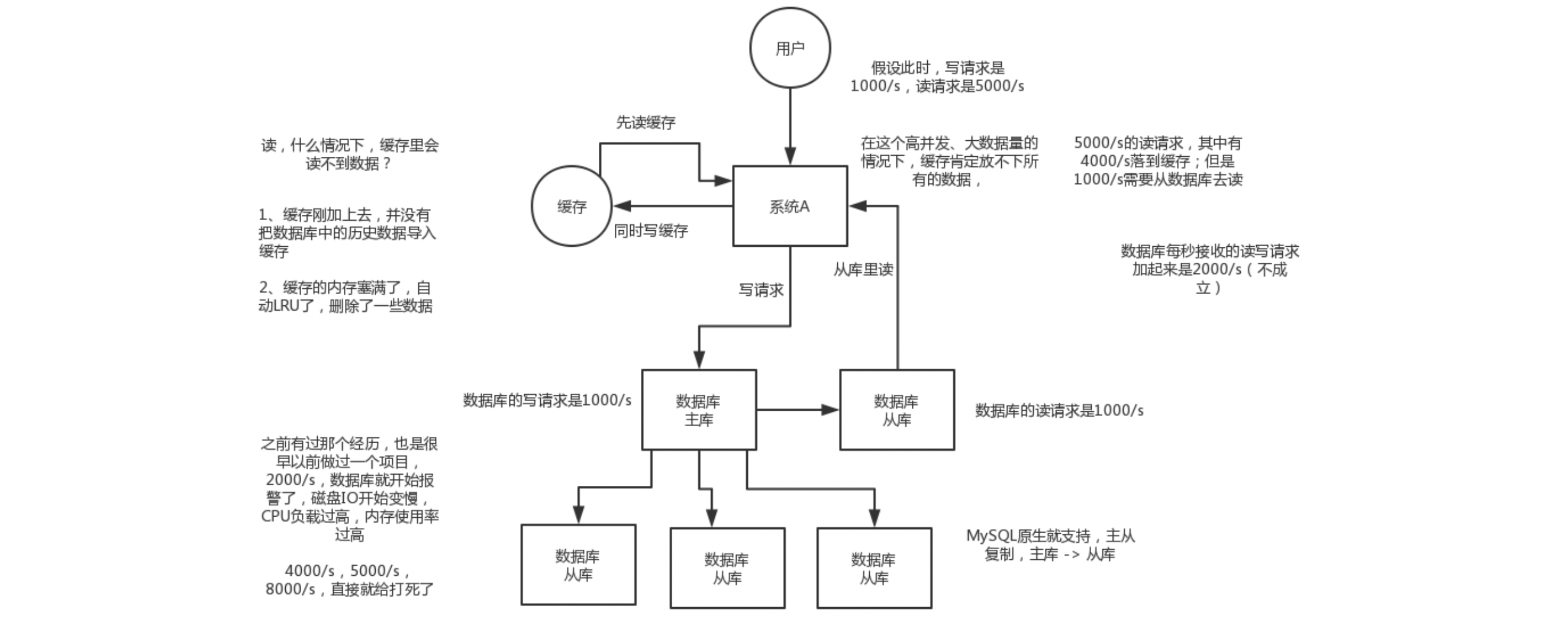
基于主从复制架构,简单来说,就搞一个主库,挂多个从库,然后我们就单单只是写主库,然后主库会自动把数据给同步到从库上去。一般情况下,主库可以挂4-5个从库
为什么需要mysql读写分离?
# 读写分离的好处
- 分摊服务器压力,提高机器的系统处理效率
- 读写分离适用于读远比写的场景,如果有一台服务器,当select很多时,update和delete会被这些select访问中的数据堵塞,等待select结束,并发性能并不高,而主从只负责各自的写和读,极大程度的缓解X锁和S锁争用;
- 假如我们有1主3从,不考虑上述1中提到的从库单方面设置,假设现在1分钟内有10条写入,150条读取。那么,1主3从相当于共计40条写入,而读取总数没变,因此平均下来每台服务器承担了10条写入和50条读取(主库不承担读取操作)。因此,虽然写入没变,但是读取大大分摊了,提高了系统性能。另外,当读取被分摊后,又间接提高了写入的性能。所以,总体性能提高了,说白了就是拿机器和带宽换性能;
- 增加冗余,提高服务可用性,当一台数据库服务器宕机后可以调整另外一台从库以最快速度恢复服务
# MySQL主从复制原理
- MySQL里有一个概念,叫binlog日志,就是每个增删改类的操作,会改变数据的操作,除了更新数据以外,对这个增删改操作还会写入一个日志文件,记录这个操作的日志。
- 主库将变更写binlog日志,然后从库连接到主库之后,从库有一个IO线程,将主库的binlog日志拷贝到自己本地,写入一个中继日志中。接着从库中有一个SQL线程会从中继日志读取binlog,然后执行binlog日志中的内容,也就是在自己本地再次执行一遍SQL,这样就可以保证自己跟主库的数据是一样的。
- 这里有一个非常重要的一点,就是从库同步主库数据的过程是串行化的,也就是说主库上并行的操作,在从库上会串行执行。所以这就是一个非常重要的点了,由于从库从主库拷贝日志以及串行执行SQL的特点,在高并发场景下,从库的数据一定会比主库慢一些,是有延时的。所以经常出现,刚写入主库的数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
- 而且这里还有另外一个问题,就是如果主库突然宕机,然后恰好数据还没同步到从库,那么有些数据可能在从库上是没有的,有些数据可能就丢失了。
- 所以mysql实际上在这一块有两个机制
- 一个是半同步复制,用来解决主库数据丢失问题;
- 一个是并行复制,用来解决主从同步延时问题。
- 这个所谓半同步复制,semi-sync复制,指的就是主库写入binlog日志之后,就会将强制此时立即将数据同步到从库,从库将日志写入自己本地的relay log之后,接着会返回一个ack给主库,主库接收到至少一个从库的ack之后才会认为写操作完成了。
# 1.MySQl主从复制
原理:将主服务器的binlog日志复制到从服务器上执行一遍,达到主从数据的一致状态。
过程:从库开启一个I/O线程,向主库请求Binlog日志。主节点开启一个binlog dump线程,检查自己的二进制日志,并发送给从节点;从库将接收到的数据保存到中继日志(Relay log)中,另外开启一个SQL线程,把Relay中的操作在自身机器上执行一遍
优点:
- 作为备用数据库,并且不影响业务
- 可做读写分离,一般是一个写库,一个或多个读库,分布在不同的服务器上,充分发挥服务器和数据库的性能,但要保证数据的一致性
# 2.主从复制的日志格式
这里的日志格式就是指二进制日志的三种格式:基于语句statement的复制、基于行row的复制、基于语句和行(mix)的复制。其中基于row的复制方式更能保证主从库数据的一致性,但日志量较大,在设置时考虑磁盘的空间问题
show variables like ‘%binlog%format%’; #查看当前使用的binlog的格式
set binlog_format = ‘row’; #设置格式,这种方法只在当前session生效
set global binlog_format = ‘row’; #在全局下设置binlog格式,会影响所有的Session
2
3
# 3.复制架构
# 3.1、一主多从架构
- 在主库的请求压力非常大时,可通过配置一主多从复制架构实现读写分离,把大量对实时性要求不是很高的请求通过负载均衡分发到多个从库上去读取数据,降低主库的读取压力。而且在主库出现宕机时,可将一个从库切换为主库继续提供服务
# 3.2、多级复制架构
因为每个从库在主库上都会有一个独立的Binlog Dump线程来推送binlog日志,所以随着从库数量的增加,主库的IO压力和网络压力也会随之增加,这时,多级复制架构应运而生。
多级复制架构只是在一主多从的基础上,再主库和各个从库之间增加了一个二级主库Master2,这个二级主库仅仅用来将一级主库推送给它的BInlog日志再推送给各个从库,以此来减轻一级主库的推送压力。
但它的缺点就是Binlog日志要经过两次复制才能到达从库,增加了复制的延时。
我们可以通过在二级从库上应用Blackhol存储引擎(黑洞引擎)来解决这一问题,降低多级复制的延时。
“黑洞引擎”就是写入Blackhole表中数据并不会写到磁盘上,所以这个Blackhole表永远是个空表,对数据的插入/更新/删除操作仅在Binlog中记录,并复制到从库中去。
# 3.3、双主复制/Dual Master架构
双主复制架构适用于需要进行主从切换的场景
在只有一个主库的架构下,当主库宕机后,将其中一个从库切换为主库继续提供服务。原来的主库就没有数据来源了,那么当这个新的主库接收到新的数据时,原来的主库却没有同步,因此他们的数据差异越来越大,那么原来的主库就无法成为主从复制环境中的一员了。当原来的主库恢复正常后,需要重新将其添加进复制环境中去。
那为了避免重复添加主库的问题,双主复制应运而生。两个数据库互为主从,当主库宕机恢复后,由于它还是原来从库(现在主库)的从机,所以它还是会复制新的主库上的数据。那么无论主库的角色怎么切换,原来的主库都不会脱离复制环境。
# 4.复制方式
- MySQL的主从复制有两种复制方式,分别是异步复制和半同步复制
# 4.1异步复制
1、逻辑上
MySQL默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主如果crash掉了,此时主上已经提交的事务可能并没有传到从库上,如果此时,强行将从提升为主,可能导致新主上的数据不完整。
2、技术上
主库将事务 Binlog 事件写入到 Binlog 文件中,此时主库只会通知一下 Dump 线程发送这些新的 Binlog,然后主库就会继续处理提交操作,而此时不会保证这些 Binlog 传到任何一个从库节点上。
# 4.2全同步复制
1、逻辑上
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。
2、技术上
当主库提交事务之后,所有的从库节点必须收到、APPLY并且提交这些事务,然后主库线程才能继续做后续操作。但缺点是,主库完成一个事务的时间会被拉长,性能降低。
# 4.3半同步复制
1、逻辑上
是介于全同步复制与全异步复制之间的一种,主库只需要等待至少一个从库节点收到并且 Flush Binlog 到 Relay Log 文件即可,主库不需要等待所有从库给主库反馈。同时,这里只是一个收到的反馈,而不是已经完全完成并且提交的反馈,如此,节省了很多时间。
2、技术上
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
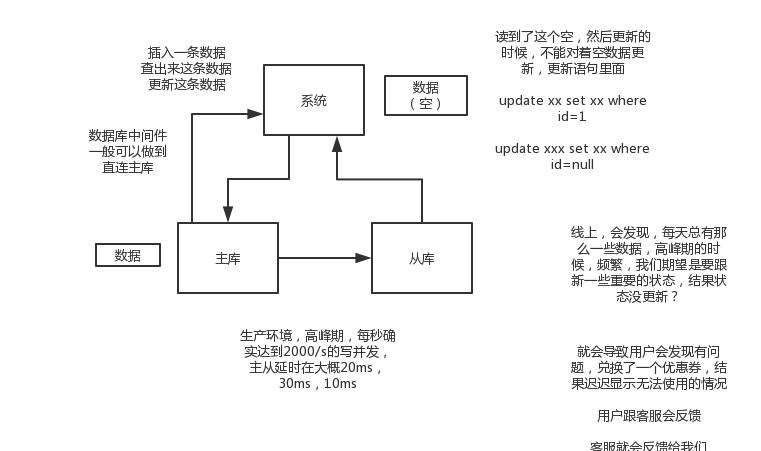
# MySQL主从同步延时问题(重点)
线上确实处理过因为主从同步延时问题,导致的线上的bug,小型的生产事故
show status,Seconds_Behind_Master,你可以看到从库复制主库的数据落后了几ms
其实这块东西我们经常会碰到,就比如说用了mysql主从架构之后,可能会发现,刚写入库的数据结果没查到,结果就完蛋了。。。。
所以实际上你要考虑好应该在什么场景下来用这个mysql主从同步,建议是一般在读远远多于写,而且读的时候一般对数据时效性要求没那么高的时候,用mysql主从同步
所以这个时候,我们可以考虑的一个事情就是,你可以用mysql的并行复制,但是问题是那是库级别的并行,所以有时候作用不是很大
所以这个时候。。通常来说,我们会对于那种写了之后立马就要保证可以查到的场景,采用强制读主库的方式,这样就可以保证你肯定的可以读到数据了吧。其实用一些数据库中间件是没问题的。
一般来说,如果主从延迟较为严重
- 分库,将一个主库拆分为4个主库,每个主库的写并发就500/s,此时主从延迟可以忽略不计
- 打开mysql支持的并行复制,多个库并行复制,如果说某个库的写入并发就是特别高,单库写并发达到了2000/s,并行复制还是没意义。28法则,很多时候比如说,就是少数的几个订单表,写入了2000/s,其他几十个表10/s。
- 重写代码,写代码的同学,要慎重,当时我们其实短期是让那个同学重写了一下代码,插入数据之后,直接就更新,不要查询
- 如果确实是存在必须先插入,立马要求就查询到,然后立马就要反过来执行一些操作,对这个查询设置直连主库。不推荐这种方法,你这么搞导致读写分离的意义就丧失了