 时间轮
时间轮
# time wheel 初识
时间轮,是一种实现延迟功能(定时器)的巧妙算法,在Netty,Zookeeper,Kafka等各种框架中,甚至Linux内核中都有用到
时间轮可以看作是由多个槽位组成的环形数据结构。每个槽位表示一个时间间隔,通常称为时间刻度。整个时间轮按照时间刻度从小到大排列。时间刻度的大小取决于系统需求,可以是毫秒、秒或其他时间单位
时间轮是一种常见的数据结构,用于处理按时间排序的事件或任务。它通常用于实现定时器和调度器,能够在未来的某个时间点执行预定的操作。时间轮的设计目的是高效地管理和触发这些事件,特别是在大量事件需要同时进行调度的情况下
能够高效地处理大量的定时任务,并且添加、删除事件的时间复杂度都是O(1)
常见的时间轮实现有两种:
简单时间轮(Simple Timing Wheel)—— 比如 Netty4 的 HashedWheelTimer (opens new window)
层级时间轮(Hierarchical Timing Wheels)—— 比如 Kafka 的 Purgatory (opens new window)
# 特点
特点
- 时间轮包含多个槽(slot),每个槽代表一个时间间隔,比如1秒、10秒等。槽按时间顺序排列成一个环形链表。
- 每个槽内部包含一个链表或哈希表,用于存储定时到该槽对应时间的事件。
- 有一个指针指向当前时间的槽,这个指针会随着时间推进而移动。
- 当指针移动到一个槽时,就可以处理该槽内部存储的到期事件。
- 时间轮通常以固定的时间间隔长度划分槽,比如10ms一个槽。当需要较长的时间间隔时,可以把多个连续的槽组成一个较大的逻辑槽。
- 时间轮可以看成是一个定时器集合,通过槽的细粒度划分,可以高效地管理大量定时任务。
优点
- 高效的调度和执行:时间轮设计的目的是高效地管理和触发按时间排序的事件,能够在未来的某个时间点执行预定的操作。通过使用时间刻度来组织和调度事件,时间轮能够以O(1)的时间复杂度执行定时任务,无论任务数量多少,执行效率都保持稳定
- 节省资源:时间轮是一个环形数组,不需要额外的内存分配,只需固定大小的空间来存储槽位和事件。相比其他定时器实现方式,时间轮具有较小的内存占用,这在资源受限的嵌入式系统和高并发环境中尤为重要
- 容易实现:时间轮的设计相对简单,易于理解和实现。它可以作为一种通用的定时器框架,并能够在不同的编程语言和环境中应用
- 容错性:时间轮对系统时间的变化和不稳定性具有一定的容错性。即使系统时间发生小幅度的跳跃或者变慢,时间轮仍然能够按照预定的时间刻度执行事件,不会因为系统时间的变化而导致任务执行出现明显的误差
- 支持嵌套时间轮:通过嵌套时间轮的方式,时间轮可以提供更高的时间精度。这允许用户在需要更细粒度的定时任务时,使用嵌套时间轮来处理,保持了整体设计的灵活性
限制
- 主要的限制是时间刻度的最小粒度受到时间轮的大小限制,因此在某些实时性要求极高的场景下,可能需要采用其他更精细的定时器实现
- 时间轮在执行大量任务时,可能会因为时间轮的指针移动而引起较大的时间开销
# 应用场景
- 定时任务调度:时间轮最典型的应用场景之一是定时任务调度。它能够高效地管理和触发按时间排序的任务,如定时执行备份、数据清理、定期报告生成等任务
- 延迟任务
- 网络服务器:在网络服务器中,时间轮可以用于管理连接超时、心跳包发送等功能,确保连接的稳定和维护
- 超时控制:时间轮可用于监控某些操作的执行时间,如超时限制、请求响应时间控制等
- 数据缓存过期:在缓存系统中,时间轮可以用来实现数据缓存的过期管理,定期清理过期的缓存数据,以保证缓存系统的有效性和性能
- 分布式系统:在分布式系统中,时间轮可以用于实现分布式任务调度和定时任务同步
# go中的Timer
在 Go 中,
Timer是一个定时器类型,用于在未来的某个时间点触发单次事件。它的实现原理涉及 Go 的协程调度和底层的系统计时器内置的 Timer (opens new window) 是采用最小堆来实现的,创建和删除的时间复杂度都为 O(log n),效率低下
Timer的实现原理如下:- 使用堆:Go 的
Timer使用一个小顶堆来维护定时器事件。每个Timer对象在创建时会被插入到这个小顶堆中 - 时间计算:当
Timer创建时,会根据设定的触发时间与当前时间的差值,计算出触发事件所需的时间间隔。这个时间间隔被用作定时器事件的优先级,也就是在小顶堆中的排序依据 - 阻塞协程:当一个
Timer启动后,在触发时间到达之前,对应的协程会被阻塞,暂停执行,而不会占用处理器资源 - 唤醒:一旦定时器事件的触发时间到达,Go 运行时会唤醒对应的阻塞协程,使其继续执行。这个唤醒操作是由运行时系统中的调度器(scheduler)负责的
- 回调执行:一旦协程被唤醒,对应的定时器事件就会执行,也就是调用用户定义的回调函数
- 重复执行:如果需要定时器重复执行,Go 会在回调函数中再次调用
Timer的Reset方法来设置下一个触发时间,并将协程重新插入小顶堆中
- 使用堆:Go 的
Timer并不是完全精确的定时器,其触发时间可能会受到系统调度和运行时的影响,不适合需要高精度和实时性的场景。对于更高精度的定时需求,可以使用time.Ticker,它会根据系统时钟的周期性中断来触发事件,但也相对更消耗资源
# 简单时间轮
参考https://www.luozhiyun.com/archives/444
在时间轮中存储任务的是一个环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表。定时任务列表是一个环形的双向链表,链表中的每一项表示的都是定时任务项,其中封装了真正的定时任务。
时间轮由多个时间格组成,每个时间格代表当前时间轮的基本时间跨度(tickMs)。时间轮的时间格个数是固定的,可用 wheelSize 来表示,那么整个时间轮的总体时间跨度(interval)可以通过公式 tickMs×wheelSize 计算得出。
时间轮还有一个表盘指针(currentTime),用来表示时间轮当前所处的时间,currentTime 是 tickMs 的整数倍。currentTime指向的地方是表示到期的时间格,表示需要处理的时间格所对应的链表中的所有任务。
如下图是一个tickMs为1s,wheelSize等于10的时间轮,每一格里面放的是一个定时任务链表,链表里面存有真正的任务项:

初始情况下表盘指针 currentTime 指向时间格0,若时间轮的 tickMs 为 1ms 且 wheelSize 等于10,那么interval则等于10s。如下图此时有一个定时为2s的任务插进来会存放到时间格为2的任务链表中,用红色标记。随着时间的不断推移,指针 currentTime 不断向前推进,如果过了2s,那么 currentTime 会指向时间格2的位置,会将此时间格的任务链表获取出来处理。
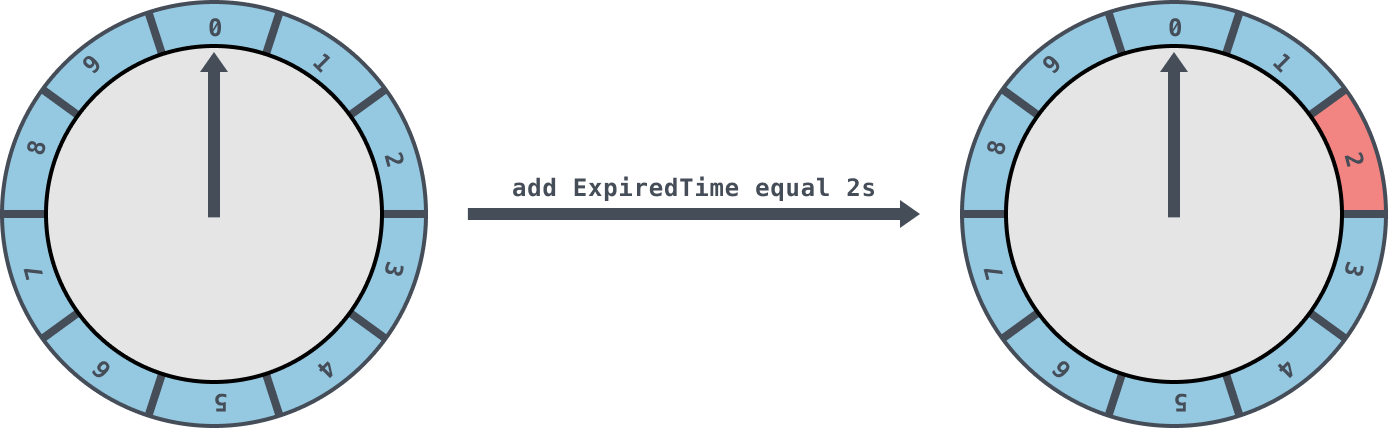
如果当前的指针 currentTime 指向的是2,此时如果插入一个9s的任务进来,那么新来的任务会服用原来的时间格链表,会存放到时间格1中
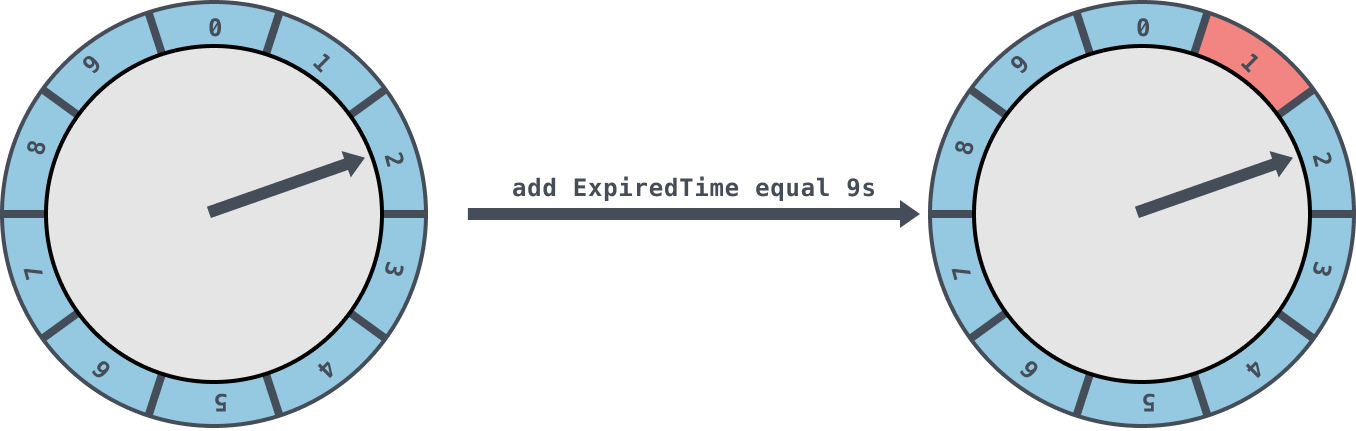
这里所讲的时间轮都是简单时间轮,只有一层,总体时间范围在 currentTime 和 currentTime+interval 之间。如果现在有一个15s的定时任务是需要重新开启一个时间轮,设置一个时间跨度至少为15s的时间轮才够用。但是这样扩充是没有底线的,如果需要一个1万秒的时间轮,那么就需要一个这么大的数组去存放,不仅占用很大的内存空间,而且也会因为需要遍历这么大的数组从而拉低效率,解决办法:
- 层级时间轮
- 为每个task添加一个 circle( 任务所在轮盘的圈数)来虚拟层级的概念
# 层级时间轮
如图是一个两层的时间轮,第二层时间轮也是由10个时间格组成,每个时间格的跨度是10s。第二层的时间轮的 tickMs 为第一层时间轮的 interval,即10s。每一层时间轮的 wheelSize 是固定的,都是10,那么第二层的时间轮的总体时间跨度 interval 为100s。
图中展示了每个时间格对应的过期时间范围, 我们可以清晰地看到, 第二层时间轮的第0个时间格的过期时间范围是 [0,9]。也就是说, 第二层时间轮的一个时间格就可以表示第一层时间轮的所有(10个)时间格;
如果向该时间轮中添加一个15s的任务,那么当第一层时间轮容纳不下时,进入第二层时间轮,并插入到过期时间为[10,19]的时间格中。

每层时间轮的任务封装为
随着时间的流逝,当原本15s的任务还剩下5s的时候,这里就有一个时间轮降级的操作,此时第一层时间轮的总体时间跨度已足够,此任务被添加到第一层时间轮到期时间为5的时间格中,之后再经历5s后,此任务真正到期,最终执行相应的到期操作
# 虚拟层级时间轮
为每个task添加一个 circle( 任务所在轮盘的圈数)来虚拟层级的概念
代码实现
package main import ( "container/list" "fmt" "sync" "time" ) type TimeWheel struct { interval time.Duration // 时间轮盘的精度 slotNums int // 时间轮盘的槽数 currentPos int // 时间轮盘指针当前的位置 ticker *time.Ticker // 时钟计时器,定时触发 slots []*list.List // 时间轮盘的槽(双向队列) taskRecords *sync.Map // 针对任务的一个map表,key是任务的key,value是任务对象 isRunning bool // 时间轮盘是否是running状态,避免重复启动 } type Job func(interface{}) // 到时间以后执行的Job type Task struct { key interface{} // 任务的唯一标识,必须是唯一的 interval time.Duration // 任务间隔多长时间执行 createdTime time.Time // 创建时间 pos int // 任务在时间轮盘的存储位置,也就是TimeWheel.slots中的存储位置 circle int // 任务所在轮盘的圈数 job Job // 任务的执行函数 times int // 该任务需要执行的次数,如果需要一直执行,设置成<0的数 } func (tw *TimeWheel) Start() { if tw.isRunning { return } tw.ticker = time.NewTicker(tw.interval) tw.isRunning = true } func (tw *TimeWheel) start() { for { select { case <-tw.ticker.C: // 通过runTask函数来检查当前需要执行的任务 tw.checkAndRunTask() } } } // 添加任务的内部函数 // @param task Task Task对象 // @param byInterval bool 生成Task在时间轮盘位置和圈数的方式,true表示利用Task.interval来生成,false表示利用Task.createTime生成 func (tw *TimeWheel) addTask(task *Task, byInterval bool) { var pos, circle int if byInterval { pos, circle = tw.getPosAndCircleByInterval(task.interval) } else { pos, circle = tw.getPosAndCircleByCreatedTime(task.createdTime, task.interval, task.key) } task.circle = circle task.pos = pos element := tw.slots[pos].PushBack(task) tw.taskRecords.Store(task.key, element) } // 通过任务的周期来计算下次执行的位置和圈数 func (tw *TimeWheel) getPosAndCircleByInterval(d time.Duration) (int, int) { delaySeconds := int(d.Seconds()) intervalSeconds := int(tw.interval.Seconds()) circle := delaySeconds / intervalSeconds / tw.slotNums pos := (tw.currentPos + delaySeconds/intervalSeconds) % tw.slotNums // 特殊case,当计算的位置和当前位置重叠时,因为当前位置已经走过了,所以circle需要减一 if pos == tw.currentPos && circle != 0 { circle-- } return pos, circle } // 用任务的创建时间来计算下次执行的位置和圈数 func (tw *TimeWheel) getPosAndCircleByCreatedTime(createdTime time.Time, interval time.Duration, key interface{}) (int, int) { passedTime := time.Since(createdTime) passedSeconds := int(passedTime.Seconds()) delaySeconds := int(interval.Seconds()) intervalSeconds := int(tw.interval.Seconds()) circle := delaySeconds / intervalSeconds / tw.slotNums pos := (tw.currentPos + (delaySeconds-(passedSeconds%delaySeconds))/intervalSeconds) % tw.slotNums // 特殊case,当计算的位置和当前位置重叠时,因为当前位置已经走过了,所以circle需要减一 if pos == tw.currentPos && circle != 0 { circle-- } return pos, circle } // 删除任务的内部函数 func (tw *TimeWheel) removeTask(task *Task) { // 从map结构中删除 val, _ := tw.taskRecords.Load(task.key) tw.taskRecords.Delete(task.key) // 通过TimeWheel.slots获取任务的 currentList := tw.slots[task.pos] currentList.Remove(val.(*list.Element)) } // 检查该轮盘点位上的Task,看哪个需要执行 func (tw *TimeWheel) checkAndRunTask() { // 获取该轮盘位置的双向链表 currentList := tw.slots[tw.currentPos] if currentList != nil { for item := currentList.Front(); item != nil; { task := item.Value.(*Task) // 如果圈数>0,表示还没到执行时间,更新圈数 if task.circle > 0 { task.circle-- item = item.Next() continue } // 执行任务时,Task.job是第一优先级,然后是 TimeWheel.job if task.job != nil { go task.job(task.key) } else { fmt.Println(fmt.Sprintf("The task %d don't have job to run", task.key)) } // 执行完成以后,将该任务从时间轮盘删除 next := item.Next() tw.taskRecords.Delete(task.key) currentList.Remove(item) item = next // 重新添加任务到时间轮盘,用Task.interval来获取下一次执行的轮盘位置 if task.times != 0 { if task.times < 0 { tw.addTask(task, true) } else { task.times-- tw.addTask(task, true) } } else { // 将任务从taskRecords中删除 tw.taskRecords.Delete(task.key) } } } // 轮盘前进一步 if tw.currentPos == tw.slotNums-1 { tw.currentPos = 0 } else { tw.currentPos++ } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
# kafka 层级时间轮实现
# 1. 时钟驱动方式
常规的时间轮实现中,会在一个线程中每隔一个时间单位 tick 就醒来一次,并驱动时钟走向下一格,然后检查这一格中是否包含定时任务。如果时间单位 tick 很小(比如 Kafka 中 tick 为 1ms)并且(在最低层时间轮的)定时任务很少,那么这种驱动方式将会非常低效。比如上面的【虚拟层级时间轮】章节中的时间轮盘的推动就是通过time.ticker 实现的
func (tw *TimeWheel) start() { for { select { case <-tw.ticker.C: // 通过runTask函数来检查当前需要执行的任务 tw.checkAndRunTask() } } }1
2
3
4
5
6
7
8
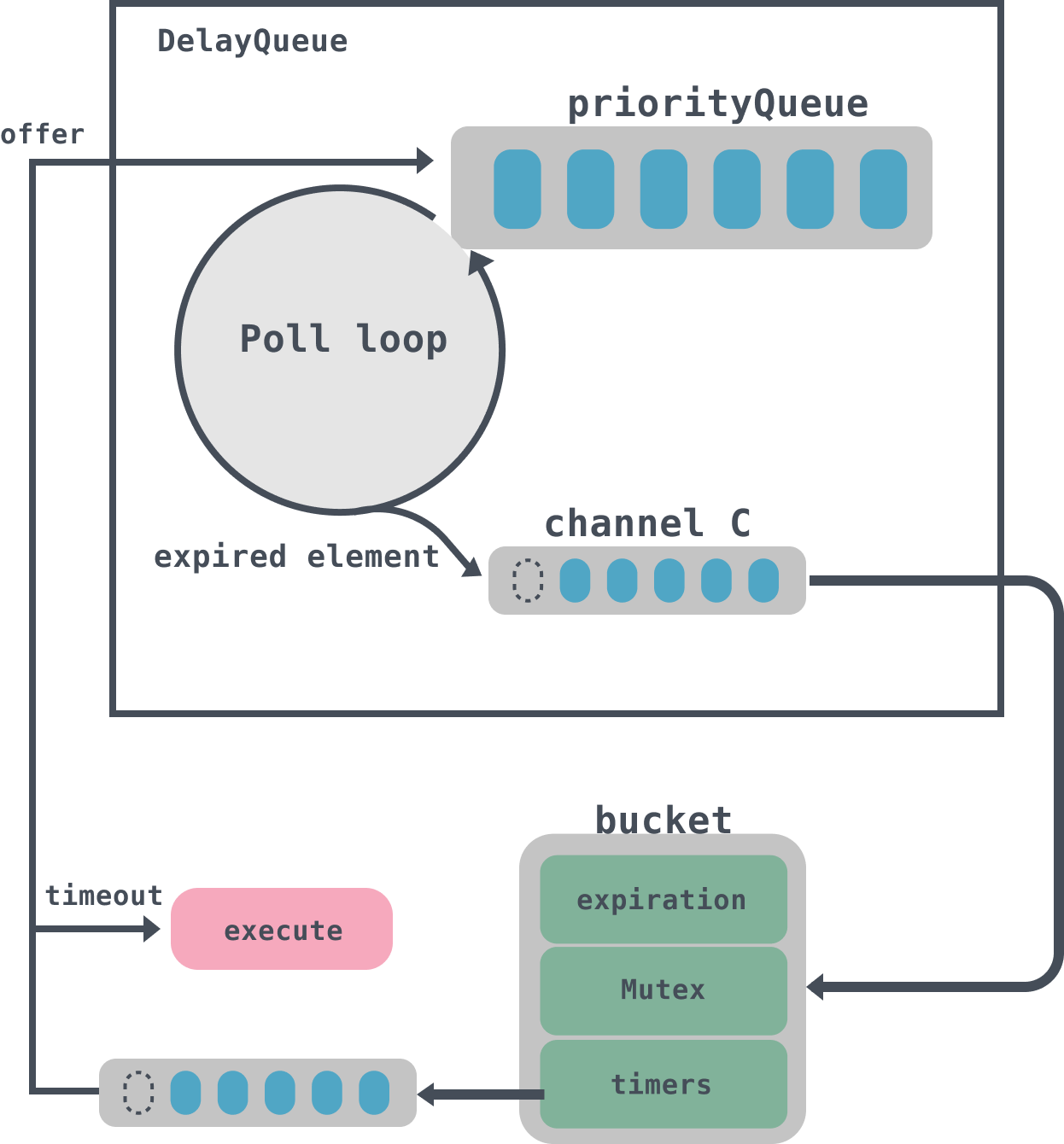
9Kafka 的层级时间轮实现中,利用了 Java 内置的 DelayQueue (opens new window) 结构,将每一层时间轮中所有 “包含有定时任务的 bucket” 都加入到同一个 DelayQueue 中(参考 源码 (opens new window)),然后 等到有 bucket 到期后再驱动时钟往前走(参考 源码 (opens new window)),并逐个处理该 bucket 中的定时任务(参考 源码 (opens new window))。
- 往层级时间轮中添加一个定时任务 task1 后,会将该任务所属的 bucket2 的到期时间设置为 task1 的到期时间 expiration(= 当前时间 currentTime + 定时任务到期间隔 duration),并将这个 bucket2 添加(Offer)到 DelayQueue 中。
- DelayQueue(内部有一个线程)会等待 “到期时间最早(earliest)的 bucket” 到期,图中等到的是排在队首的 bucket2,于是经由 poll 返回并删除这个 bucket2;随后,时间轮会将当前时间 currentTime 往前移动到 bucket2 的 expiration 所指向的时间(图中是 1ms 所在的位置);最后,bucket2 中包含的 task1 会被删除并执行。
- 上述 Kafka 层级时间轮的驱动方式是非常高效的。虽然 DelayQueue 中 offer(添加)和 poll(获取并删除)操作的时间复杂度为 O(log n),但是相比定时任务的个数而言,bucket 的个数其实是非常小的(也就是 O(log n) 中的 n 很小),因此性能也是没有问题的

# 2. 代码实现
https://github.com/RussellLuo/timingwheel
- 细节
- 时间轮的时间格中每个链表会有一个root节点用于简化边界条件。它是一个附加的链表节点,该节点作为第一个节点,它的值域中并不存储任何东西,只是为了操作的方便而引入的;
- 除了第一层时间轮,其余高层时间轮的起始时间(startMs)都设置为创建此层时间轮时前面第一轮的 currentTime。每一层的 currentTime 都必须是 tickMs 的整数倍,如果不满足则会将 currentTime 修剪为 tickMs 的整数倍。修剪方法为:currentTime = startMs – (startMs % tickMs);
- Kafka 中的定时器只需持有 TimingWheel 的第一层时间轮的引用,并不会直接持有其他高层的时间轮,但每一层时间轮都会有一个引用(overflowWheel)指向更高一层的应用;
- Kafka 中的定时器使用了 DelayQueue 来协助推进时间轮。在操作中会将每个使用到的时间格中每个链表都加入 DelayQueue,DelayQueue 会根据时间轮对应的过期时间 expiration 来排序,最短 expiration 的任务会被排在 DelayQueue 的队头,通过单独线程来获取 DelayQueue 中到期的任务;
# a. 结构体
code
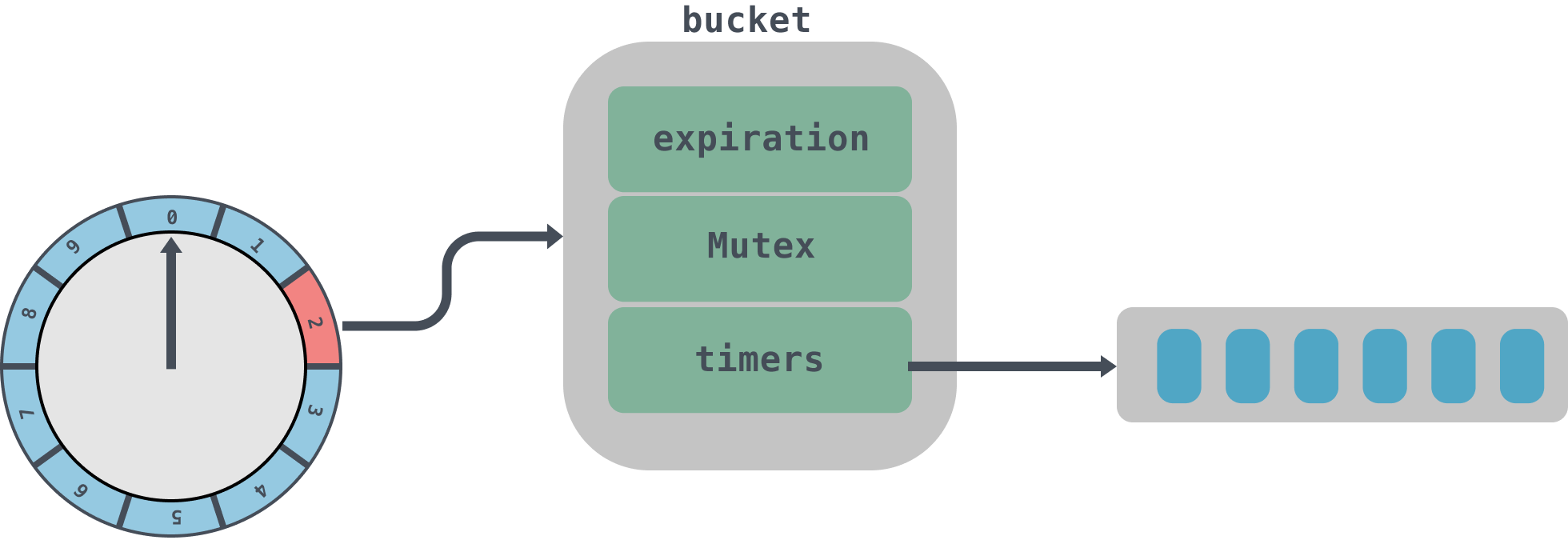
type TimingWheel struct { // 时间跨度,单位是毫秒 tick int64 // in milliseconds // 时间轮个数 wheelSize int64 // 总跨度 interval int64 // in milliseconds // 当前指针指向时间 currentTime int64 // in milliseconds // 时间格列表 buckets []*bucket // 延迟队列 queue *delayqueue.DelayQueue // 上级的时间轮引用 overflowWheel unsafe.Pointer // type: *TimingWheel exitC chan struct{} waitGroup waitGroupWrapper } // bucket里面实际上封装的是时间格里面的任务队列,里面放入的是相同过期时间的任务,到期后会将队列timers拿出来进行处理 type bucket struct { // 任务的过期时间 expiration int64 mu sync.Mutex // 相同过期时间的任务队列 timers *list.List } // Timer是时间轮的最小执行单元,是定时任务的封装,到期后会调用task来执行任务。 type Timer struct { // 到期时间 expiration int64 // in milliseconds // 要被执行的具体任务 task func() // Timer所在bucket的指针 b unsafe.Pointer // type: *bucket // bucket列表中对应的元素 element *list.Element }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# b. 初识化时间轮
code
func main() { tw := timingwheel.NewTimingWheel(time.Second, 10) tw.Start() } func NewTimingWheel(tick time.Duration, wheelSize int64) *TimingWheel { // 将传入的tick转化成毫秒 tickMs := int64(tick / time.Millisecond) // 如果小于零,那么panic if tickMs <= 0 { panic(errors.New("tick must be greater than or equal to 1ms")) } // 设置开始时间 startMs := timeToMs(time.Now().UTC()) // 初始化TimingWheel return newTimingWheel( tickMs, wheelSize, startMs, delayqueue.New(int(wheelSize)), ) } func newTimingWheel(tickMs int64, wheelSize int64, startMs int64, queue *delayqueue.DelayQueue) *TimingWheel { // 初始化buckets的大小 buckets := make([]*bucket, wheelSize) for i := range buckets { buckets[i] = newBucket() } // 实例化TimingWheel return &TimingWheel{ tick: tickMs, wheelSize: wheelSize, // currentTime必须是tickMs的倍数,所以这里使用truncate进行修剪 currentTime: truncate(startMs, tickMs), interval: tickMs * wheelSize, buckets: buckets, queue: queue, exitC: make(chan struct{}), } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# c. 启动时间轮
code
// Start方法会启动两个goroutines。第一个goroutines用来调用延迟队列的queue的Poll方法,这个方法会一直循环获取队列里面的数据,然后将到期的数据放入到queue的C管道中;第二个goroutines会无限循环获取queue中C的数据,如果C中有数据表示已经到期,那么会先调用advanceClock方法将当前时间 currentTime 往前移动到 bucket的到期时间,然后再调用Flush方法取出bucket中的队列,并调用addOrRun方法执行。 func (tw *TimingWheel) Start() { // Poll会执行一个无限循环,将到期的元素放入到queue的C管道中 tw.waitGroup.Wrap(func() { tw.queue.Poll(tw.exitC, func() int64 { return timeToMs(time.Now().UTC()) }) }) // 开启无限循环获取queue中C的数据 tw.waitGroup.Wrap(func() { for { select { // 从队列里面出来的数据都是到期的bucket case elem := <-tw.queue.C: b := elem.(*bucket) // 时间轮会将当前时间 currentTime 往前移动到 bucket的到期时间 tw.advanceClock(b.Expiration()) // 取出bucket队列的数据,并调用addOrRun方法执行 b.Flush(tw.addOrRun) case <-tw.exitC: return } } }) } // advanceClock方法会根据到期时间来从新设置currentTime,从而推进时间轮前进。 func (tw *TimingWheel) advanceClock(expiration int64) { currentTime := atomic.LoadInt64(&tw.currentTime) // 过期时间大于等于(当前时间+tick) if expiration >= currentTime+tw.tick { // 将currentTime设置为expiration,从而推进currentTime currentTime = truncate(expiration, tw.tick) atomic.StoreInt64(&tw.currentTime, currentTime) // Try to advance the clock of the overflow wheel if present // 如果有上层时间轮,那么递归调用上层时间轮的引用 overflowWheel := atomic.LoadPointer(&tw.overflowWheel) if overflowWheel != nil { (*TimingWheel)(overflowWheel).advanceClock(currentTime) } } } // Flush方法会根据bucket里面timers列表进行遍历插入到ts数组中,然后调用reinsert方法,这里是调用的addOrRun方法。 func (b *bucket) Flush(reinsert func(*Timer)) { var ts []*Timer b.mu.Lock() // 循环获取bucket队列节点 for e := b.timers.Front(); e != nil; { next := e.Next() t := e.Value.(*Timer) // 将头节点移除bucket队列 b.remove(t) ts = append(ts, t) e = next } b.mu.Unlock() b.SetExpiration(-1) // TODO: Improve the coordination with b.Add() for _, t := range ts { reinsert(t) } } //addOrRun会调用add方法检查传入的定时任务Timer是否已经到期,如果到期那么异步调用task方法直接执行 func (tw *TimingWheel) addOrRun(t *Timer) { // 如果已经过期,那么直接执行 if !tw.add(t) { // 异步执行定时任务 go t.task() } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81启动流程
- start方法回启动一个goroutines调用poll来处理DelayQueue中到期的数据,并将数据放入到管道C中;
- start方法启动第二个goroutines方法会循环获取DelayQueue中管道C的数据,管道C中实际上存放的是一个bucket,然后遍历bucket的timers列表,如果任务已经到期,那么异步执行,没有到期则重新放入到DelayQueue中。
# d. add task
code
// 通过AfterFunc方法添加一个15s的定时任务,如果到期了,那么执行传入的函数 func main() { tw := timingwheel.NewTimingWheel(time.Second, 10) tw.Start() // 添加任务 tw.AfterFunc(time.Second*15, func() { fmt.Println("The timer fires") exitC <- time.Now().UTC() }) } // AfterFunc方法回根据传入的任务到期时间,以及到期需要执行的函数封装成Timer,调用addOrRun方法。addOrRun方法我们上面已经看过了,会根据到期时间来决定是否需要执行定时任务。 func (tw *TimingWheel) AfterFunc(d time.Duration, f func()) *Timer { t := &Timer{ expiration: timeToMs(time.Now().UTC().Add(d)), task: f, } tw.addOrRun(t) return t } func (tw *TimingWheel) add(t *Timer) bool { currentTime := atomic.LoadInt64(&tw.currentTime) // 已经过期 if t.expiration < currentTime+tw.tick { // Already expired return false // 到期时间在第一层环内 } else if t.expiration < currentTime+tw.interval { // Put it into its own bucket // 获取时间轮的位置 virtualID := t.expiration / tw.tick b := tw.buckets[virtualID%tw.wheelSize] // 将任务放入到bucket队列中 b.Add(t) // 如果是相同的时间,那么返回false,防止被多次插入到队列中 if b.SetExpiration(virtualID * tw.tick) { // 将该bucket加入到延迟队列中 tw.queue.Offer(b, b.Expiration()) } return true } else { // Out of the interval. Put it into the overflow wheel // 如果放入的到期时间超过第一层时间轮,那么放到上一层中去 overflowWheel := atomic.LoadPointer(&tw.overflowWheel) if overflowWheel == nil { atomic.CompareAndSwapPointer( &tw.overflowWheel, nil, // 需要注意的是,这里tick变成了interval unsafe.Pointer(newTimingWheel( tw.interval, tw.wheelSize, currentTime, tw.queue, )), ) overflowWheel = atomic.LoadPointer(&tw.overflowWheel) } // 往上递归 return (*TimingWheel)(overflowWheel).add(t) } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64